In this example, we will dive into the streaming component of Hadoop MapReduce. We will understand the basics of Hadoop Streaming and see an example using Python.
Table Of Contents
1. Introduction
Hadoop Streaming is the name which is quite misleading, here streaming has nothing to do with the continuous data streams or continuous data flow as it is understood generally. Hadoop Streaming is just a utility provided by the Hadoop MapReduce distribution which gives users the possibility to write MapReduce jobs in other programming languages like Python or C++ etc which can make use of stdin and stdout to readin and writeout lines of text data. Support for C++ is available on since the version 0.14.1
When we talk about using other programming languages, we do not mean that the code written in those languages need to be converted to the Java code. For example, if the original code is in Python, it is not required that the code be converted to Java using Jython or any similar utility. Direct Python code can run in Hadoop ecosystem using Hadoop Streaming.
2. Prerequisites and Assumptions
Following are the prerequisites/assumptions we made before diving into the details of Hadoop Streaming:
- It is assumed that you are familiar with Hadoop and MapReduce or atleast knows the basics of it. In case you need some basic understanding of those you can refer to the following articles.
- It is also assumed that you understand the basics of running and setting up a Hadoop Cluster or atleast a single instance for testing purpose. In case you need help with that, you can refer to the following articles.
Once we have all this prerequisites setup and clear, we can dive into the details of Hadoop Streaming and check out some examples.
3. Hadoop Streaming Workflow
For using Hadoop Streaming, both the mapper and reducer need to be executables and should be able to read input from stdin line by line and emit the output to stdout
Hadoop Streaming API will create and submit a MapReduce job from the executables defined for Mapper and Reducers. On initialization of each Map or Reduce task, a new process will be started with the corresponding executable.
For each input data, the mapper task takes the input line-by-line and feed the lines to the stdin of the mapper executable. After execution, the lines from stdout are taken by mapper and converted to key-value pair which will be the output of the mapper task and will be passed on to the reducer task.
In the similar fashion, reducer takes the key-value pair and convert it into lines and feed the reducer executable using stdin. After reducer is executed, it again takes the line from stdout and convert it into the key-value pair to be passed on as the final result.
Note: By default, the text in the lines upto first tab will be taken as the key and the rest of the line as value. In case, there is no tab character present in the line, the whole line will be taken as the key and value will be null. But this behavior is not binding and can be changed is required and the required behavior can be configured.
4. MapReduce Code in Python
As discussed in the section above, we will use Hadoop Streaming API to run Python Code on Hadoop. We will use sys.stdin and sys.stdout in Python to read in the data and write out the output data, everything else will be handled by the Streaming API itself.
4.1 Wordcount Example
Wordcount, as you might be knowing is the basic program which is used to explain the basics of the Hadoop MapReduce framework. In wordcount program, a bunch of text input is provided to the Mapper function which splits the lines of text into single words and pass these single words as key-value pair to the Reducer functions. Reducer received the input as the key-value pair and counts the number of instances of a particular word in the provided input text and output the key-value pairs with word as the key and the number of counts as the value. If you are not familiar with basics of wordcount program, please refer to the article Apache Hadoop Wordcount Example for the detailed explanation. In this article we will implement the same wordcount example but instead of Java we will use Python and will run the MapReduce job using Hadoop Streaming API
4.2 Mapper
The Mapper function in Python will read the line from stdin, split the line in the individual words and output the word as key-value pair with value as 1 and word as the key. For example, <word,1>
#!/usr/bin/env python
import sys
# read the input from stdin
for line in sys.stdin:
# trim any leading and trailing spaces
line = line.strip()
# split the line into individual words
words = line.split()
# for each word in words, output key-value pair
for word in words:
# outputs the result to stdout
# MapReduce Streaming API will take this output
# and feed as the input to the Reduce step
# tab-delimited
# word count is always one
print '%s\t%s' % (word, 1)
Above is the Python code to perform the Map task, now save it as mapper.py and make sure we have read and run permission for the python file.
4.3 Reducer
The Reducer will take the input from the mapper.py through stdin. Reducer then sums the occurrence of each word and output the file reduced output in the form of key-value pair having the particular word as key and the total occurrences of the word as the value. For example, <word, 5>
#!/usr/bin/env python
from operator import itemgetter
import sys
#variable initialization
current_word = None
current_count = 0
word = None
# takes input stdin
for line in sys.stdin:
# trim any leading and trailing spaces
line = line.strip()
# split the input from mapper.py and take the word and its count
word, count = line.split('\t', 1)
# convert count string to int
try:
count = int(count)
except ValueError:
# in case of exception
# ignore the exception and discard the input line
continue
# this IF-switch only works because Hadoop sorts map output
# by key (here: word) before it is passed to the reducer
if current_word == word:
current_count += count
else:
if current_word:
# write result to STDOUT
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)
Above is the Python code to perform the reduce task. Save this code in the file reducer.py and also make sure this file also have read and execution permission.
5. Testing the Python code
Before submitting the Python code as MapReduce job to the Hadoop cluster, it is preferred that we test the code to confirm that it works as excepted. Is it easy to make sure that the code works fine with a small input text before submitting to the cluster to parse large amount of data. We can perform the following two tests:
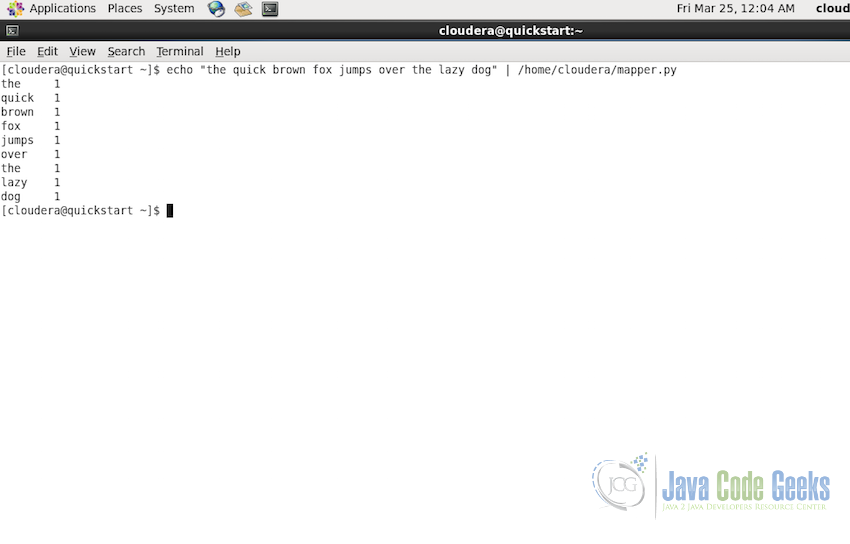
- First test will be to test the Mapper code. Execute the following command in the console. It will run the
mapper.pyscript with the given input string and we can confirm that the output is as expected.echo "the quick brown fox jumps over the lazy dog" | /home/cloudera/mapper.py
The output should be as shown in the screenshot below:

Test for mapper.py -
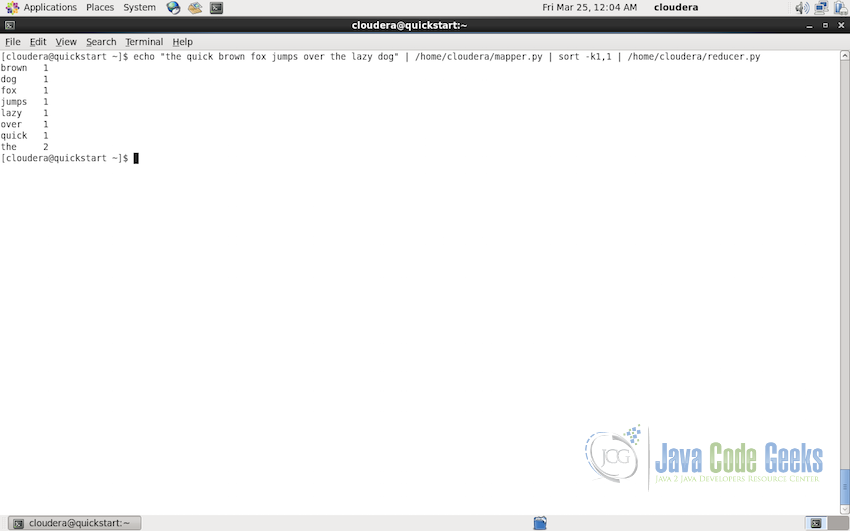
Now we can also test the Reducer code. Execute the following command in the console.
echo "the quick brown fox jumps over the lazy dog" | /home/cloudera/mapper.py | sort -k1,1 | /home/cloudera/reducer.py
The output of the above command should be as shown in the screenshot below:

Test for reducer.py
6. Submitting and Executing the Job on Hadoop cluster
In this section, we will learn how to run the Python MapReduce scripts on the Hadoop Cluster using Hadoop Streaming API.
6.1 Input Data
For this example, we will download a book from the Project Gutenberg which we will use as the input data for the MapReduce program. I have downloaded the book “Opportunities in Engineering by Charles M. Horton“.
When you visit the webpage, you will find the book in many formats as shown in the screenshot below. Make sure to download the book in Plain Text UTF-8 encoding format so that it can be easily read by the MapReduce program.
Once the book is downloaded, lets rename it to input.txt for easy reference
6.2 Transferring input data to HDFS
MapReduce needs the input data to be present and accessible in the corresponding HDFS. So before we can run the MapReduce job, we need to transfer the book we just downloaded in the previous step to the HDFS. To do so, please use the following command:
hadoop fs -put input.txt input.txt
The above command, puts the input.txt file from the local system to the HDFS at the root location and with the name input.txt as shown in the screenshot below:
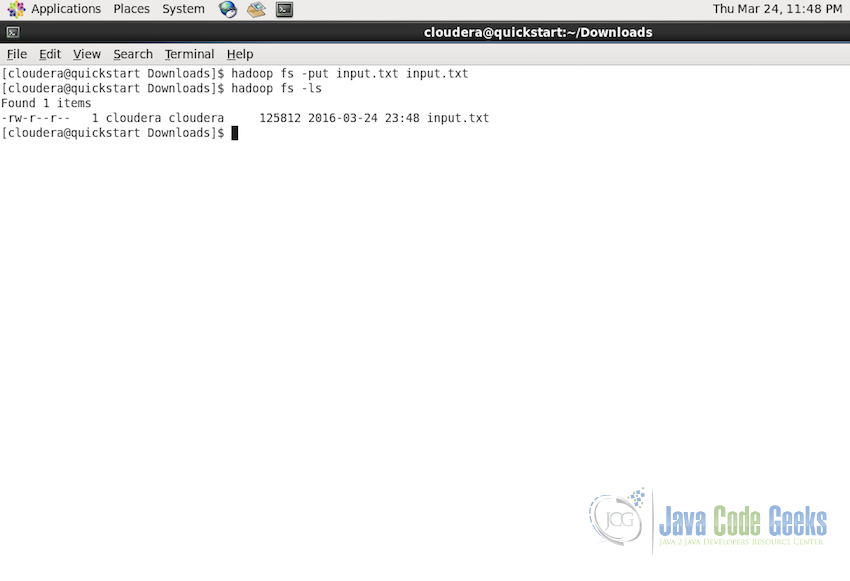
You can check if the file is successfully transferred using the command:
hadoop fs -ls
or from the Hadoop User Panel

With the successful completion of this step we are now ready to submit the Python MapReduce job to Hadoop cluster.
6.3 Submitting the MapReduce Job
For running the job on Hadoop Cluster we will use the Streaming API so that the data can be passed between the Mapper and the Reducer using stdin and stdout. Following is the command used to submit and run the job:
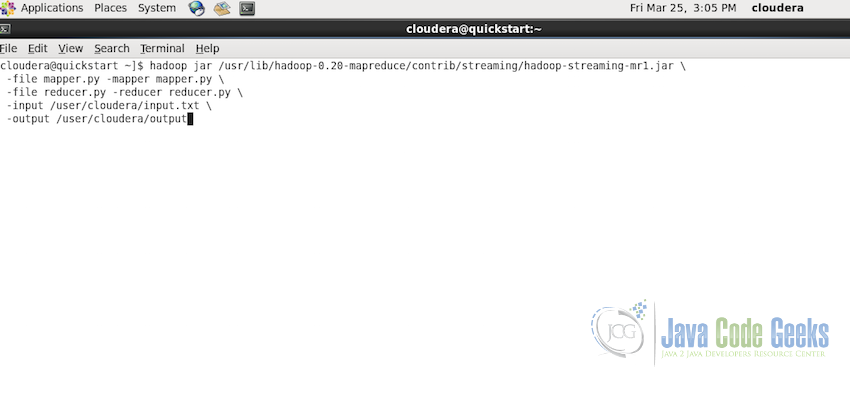
hadoop jar /usr/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming-mr1.jar \ -file mapper.py -mapper mapper.py \ -file reducer.py -reducer reducer.py \ -input /user/cloudera/input.txt \ -output /user/cloudera/output
Following is the screenshot of complete command in the console:

If the job is successfully submitted and running, you will see the console out similar to the one in the screenshot below:
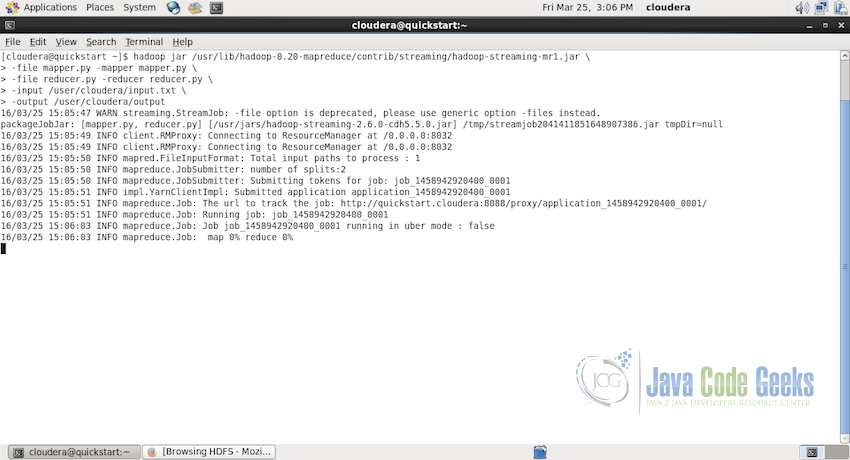
Notice the console log assigned a job id to the MapReduce job and started running the job.
Once the job is finished without any exceptions or errors, you will see the following console log with the last line mentioning the path where the output of the job is stored.
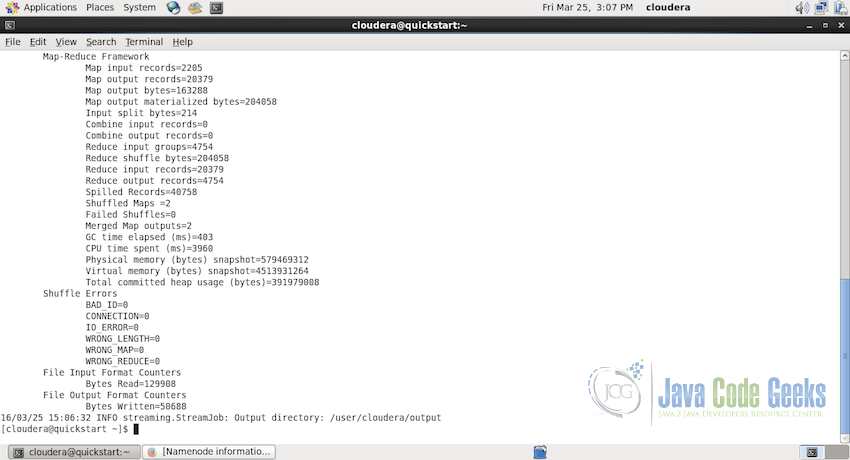
6.4 Understanding the Console Log
Successful execution of the MapReduce job will output a significant amount of log to the console. There are few important parts of the log which you should be aware of. Following is the complete console log of the execution of the above MapReduce job.
[cloudera@quickstart ~]$ hadoop jar /usr/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming-mr1.jar \ > -file mapper.py -mapper mapper.py \ > -file reducer.py -reducer reducer.py \ > -input /user/cloudera/input.txt \ > -output /user/cloudera/output 16/03/25 15:05:47 WARN streaming.StreamJob: -file option is deprecated, please use generic option -files instead. packageJobJar: [mapper.py, reducer.py] [/usr/jars/hadoop-streaming-2.6.0-cdh5.5.0.jar] /tmp/streamjob2041411851648907386.jar tmpDir=null 16/03/25 15:05:49 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 16/03/25 15:05:49 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 16/03/25 15:05:50 INFO mapred.FileInputFormat: Total input paths to process : 1 16/03/25 15:05:50 INFO mapreduce.JobSubmitter: number of splits:2 16/03/25 15:05:50 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1458942920400_0001 16/03/25 15:05:51 INFO impl.YarnClientImpl: Submitted application application_1458942920400_0001 16/03/25 15:05:51 INFO mapreduce.Job: The url to track the job: http://quickstart.cloudera:8088/proxy/application_1458942920400_0001/ 16/03/25 15:05:51 INFO mapreduce.Job: Running job: job_1458942920400_0001 16/03/25 15:06:03 INFO mapreduce.Job: Job job_1458942920400_0001 running in uber mode : false 16/03/25 15:06:03 INFO mapreduce.Job: map 0% reduce 0% 16/03/25 15:06:20 INFO mapreduce.Job: map 100% reduce 0% 16/03/25 15:06:32 INFO mapreduce.Job: map 100% reduce 100% 16/03/25 15:06:32 INFO mapreduce.Job: Job job_1458942920400_0001 completed successfully 16/03/25 15:06:32 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=204052 FILE: Number of bytes written=753127 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=130122 HDFS: Number of bytes written=50688 HDFS: Number of read operations=9 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=29025 Total time spent by all reduces in occupied slots (ms)=10319 Total time spent by all map tasks (ms)=29025 Total time spent by all reduce tasks (ms)=10319 Total vcore-seconds taken by all map tasks=29025 Total vcore-seconds taken by all reduce tasks=10319 Total megabyte-seconds taken by all map tasks=29721600 Total megabyte-seconds taken by all reduce tasks=10566656 Map-Reduce Framework Map input records=2205 Map output records=20379 Map output bytes=163288 Map output materialized bytes=204058 Input split bytes=214 Combine input records=0 Combine output records=0 Reduce input groups=4754 Reduce shuffle bytes=204058 Reduce input records=20379 Reduce output records=4754 Spilled Records=40758 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=403 CPU time spent (ms)=3960 Physical memory (bytes) snapshot=579469312 Virtual memory (bytes) snapshot=4513931264 Total committed heap usage (bytes)=391979008 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=129908 File Output Format Counters Bytes Written=50688 16/03/25 15:06:32 INFO streaming.StreamJob: Output directory: /user/cloudera/output
Following are the important parts of the whole console log:
- Line 10: Logs the total number of paths to be processed for the job. Here we have only one input file so the path to be processed is also 1.
- Line 14: Logs the url which can be used to track the progess of the job in the web-browser
- Line 17-19: Logs the progress of the Map and the Reduce taks respectively.
- Line 20: Informs that the job is completed succesfully and after this the console log will display the stats of the job.
- Line 22-32: Displays the file system stats including the number of bytes read, total number of bytes written, number of read operations and number of write operations
- Line 33-44: Displays the Job stats including total number of map and reduce jobs launched (2 and 1 respectively in this case), total time spent by map tasks and reduce tasks for exections etc.
- Line 45-64: Display the MapReduce Framework stats including the Map and Reduce records processed, total CPU time spent in processing, amount of physical and virtual memory used etc.
- Line 77: Finally the line 77 logs the path where the output of the MapReduce job is stored.
6.5 MapReduce Job Output
So after the successful execution of the job, the output data is present at the provided path. We can check if the output directory is present using the command:
hadoop fs -ls
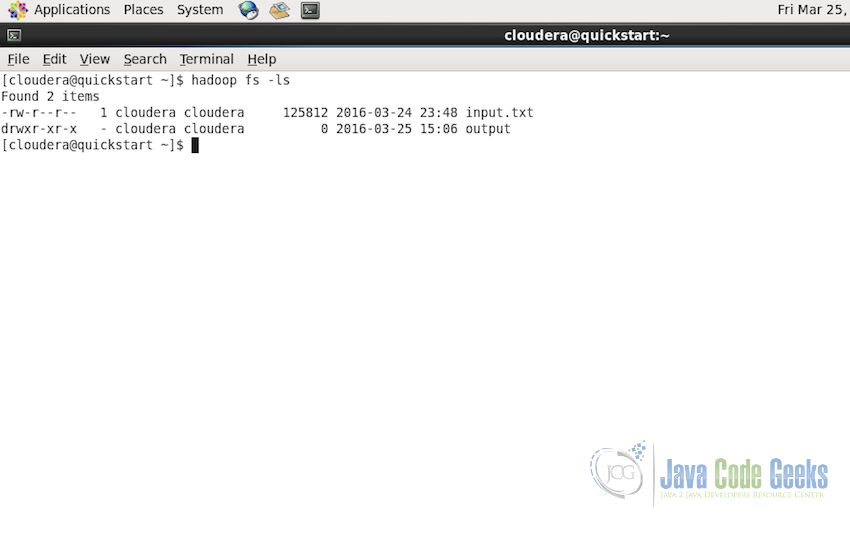
or through the Hadoop user interface:
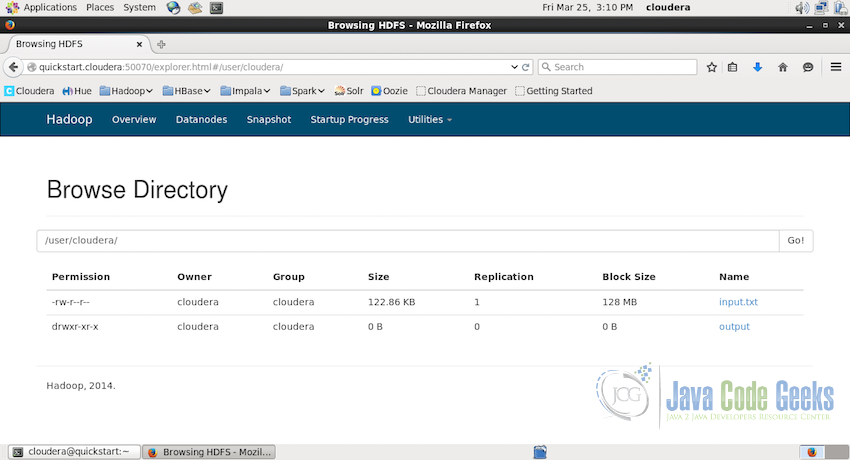
This output file can be downloaded either using the command:
hadoop fs -get output
or directly using the user interface:
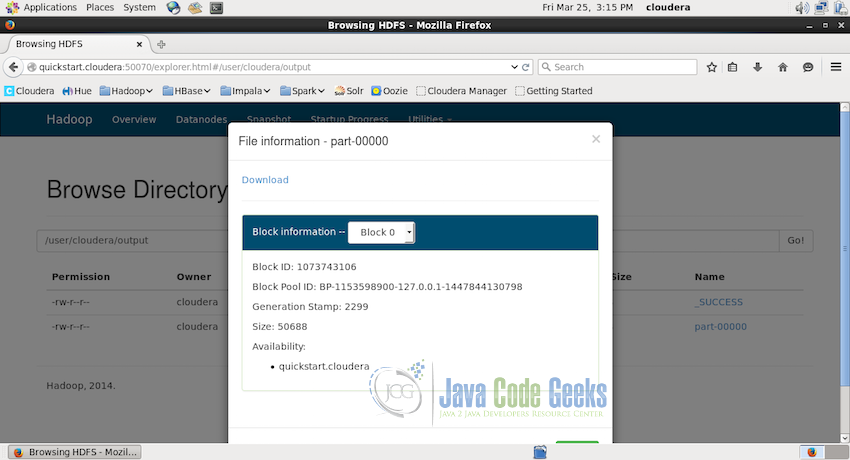
After downloading the output directly should have a text file with the name part-00000 which contains the output of the job. Following is the screenshot of the part of the file:
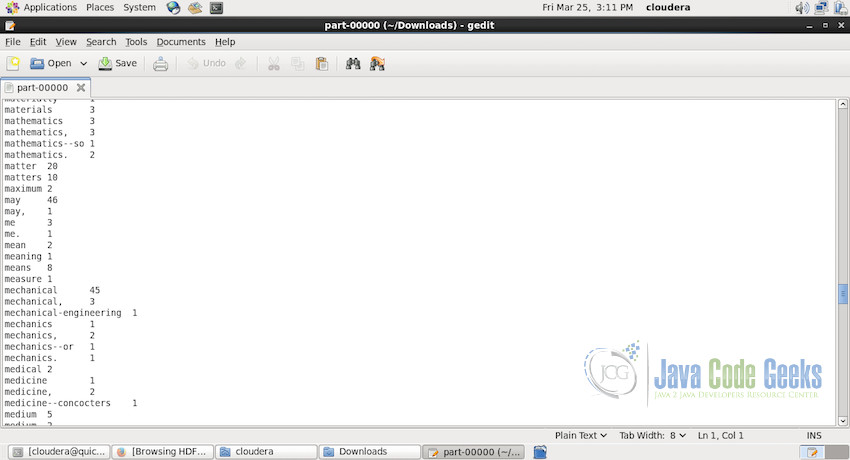
7. Conclusion
This brings us to the end of the article, to conclude, we started by understanding the basic working of the Hadoop Streaming API and its complete workflow, we saw how MapReduce code can be written in Python and how the Streaming API can be used to run the jobs on the Hadoop Cluster.
We followed the theoretical understanding with the actually WordCount example in Python, we learnt how to submit the job using Streaming API, how to interpret the console log of the Hadoop job and finally how to get the output of the processed job for further usage.
8. Download the Source Code
The following download package contains the mapper.py and reducer.py scripts used in the article.
You can download the full source code of this example here: HadoopStreaming_WordCount_Python

you have any idea as how to use JAVA for hadoop streaming? Please…