In the article we will have a look at Hadoop Sequence file format. Hadoop Sequence Files are one of the Apache Hadoop specific file formats which stores data in serialized key-value pair. We have look into details of Hadoop Sequence File in the subsequent sections.
1. Introduction
Apache Hadoop supports text files which are quite commonly used for storing the data, besides text files it also supports binary files and one of these binary formats are called Sequence Files. Hadoop Sequence File is a flat file structure which consists of serialized key-value pairs. This is the same format in which the data is stored internally during the processing of the MapReduce tasks.
Sequence files can also be compressed for space considerations and based on these compression type users, Hadoop Sequence files can be of three types:
- Uncompressed
- Record Compressed
- Block Compressed
2. File Format
Sequence files in Hadoop similar to other file formats consists of a Header at the top. This header consists of all the meta-data which is used by the file reader to determine the format of the file or if the file is compressed or not.
2.1 File Header
File header consists of the following data:

- Version: Version of the file is the first data stored in the header. It consists of a byte array in which first 2 bytes are “SEQ” followed by 1 byte which indicates the version of the file format. For example: SEQ4 or SEQ6
- Key Class Name: Next information is the string which tells the class of the key. For example it can be “Text” class.
- Value Class Name: Another string which mentioned the class of the value type. For example: “Text” class.
- Compression: A boolean value which informs the reader if the file is comptessed or not.
- Block Compression: Another boolean value which informa if the file is block compressed.
- Compression Codec Class: The classname of the Compression Codec which is used for compressing the data and will be used for de-comptessing the data.
- MetaData: Key-value pair which can provide another metadata required for the file.
- Sync Marker: A sync marker which indicates that this is the end of the header.
2.2 Uncompressed File Data Format
Uncompressed file format consists of the following data:

- Header: Header will be similar to one described in the section above.
- Record: Record is where the actual data is stored. Following is the format of the records in uncompressed files:
- Record Length
- Key length
- Key
- Value
- Sync Marker: Sync marker is placed every 100 bytes of data or so, this helps when the file needs to be split for workers processed
2.3 Record Compressed File Data Format
Record Compressed file format as discussed above has all the values compressed. The data format is almost similar to the uncompressed format, the only difference being is that values are compressed in record compressed format. It consists of the following data:

- Header: Header will be similar to one described in the header section above.
- Record: Record is where the actual data is stored. Following is the format of the records in uncompressed files:
- Record Length
- Key length
- Key
- Compressed Value
- Sync Marker: Sync marker is placed every 100 bytes of data or so, this helps when the file needs to be split for workers processed
2.4 Block Compressed File Data Format
Block compressed is the format in which both keys and values are collected in blocks separately and these blocks are compressed. Following is the format of the data file:

- Header: Header will be similar to one described in the header section above.
- Record Block: Record is where the actual data is stored. Following is the format of the records in uncompressed files:
- Uncompressed number of records in the block
- Compressed key-lengths block size
- Compressed key-length size
- Compressed key block size
- Compressed key block
- Compressed value-lengths block size
- Compressed value-lengths block
- Compressed value block size
- Compressed value block
- Sync Marker: Sync marker is placed after every block.
3. Writing to a Sequence File
In this section, we will go through the sample code which will explain how to write and read sequence file using MapReduce jobs in Apache Hadoop.
3.1 Input Text File
The input file will be the plain text file which contains the key-value pairs separated by a space.
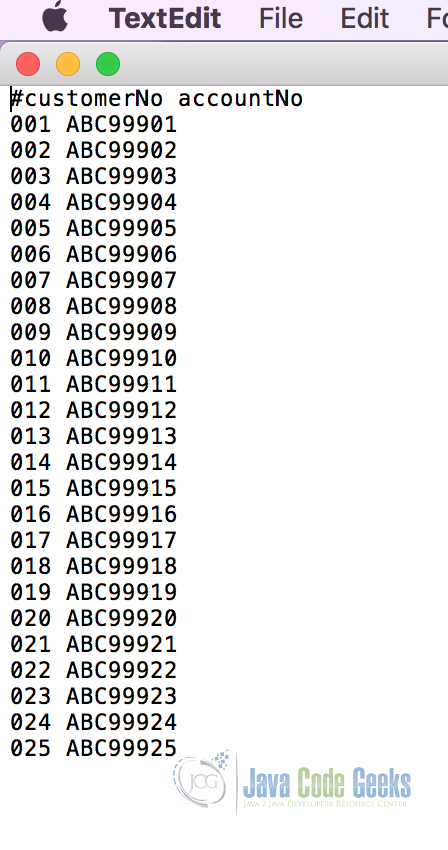
This file contains 25 key-value pairs. Let’s consider keys to be the customer numbers and the values to be the account number of these customers.
Note: File in the screenshot is present in the code sample attached with the example at the bottom.
3.2 The POM file
Now it’s the time to start writing some code. We will start by creating a maven project. In the POM file of the maven project we will add the required Apache Hadoop dependencies:
POM.xml
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
So we add the hadoop-core as a dependency in our POM.xml. You can check the complete POM file in the project code attached at the bottom of the example.
3.3 Mapper to Write Sequence File
As we know internally in Apache Hadoop data can be stored in a sequence file. We will do the same, we will write a Mapper class which will write the data in the Sequence file from out text file. Our MapReduce program will have only Mapper and no Reducer.
SequenceFileWriterMapper.java
package com.javacodegeeks.examples.sequenceFile;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* Mapper class of the MapReduce package.
* It just writes the input key-value pair to the context
*
* @author Raman
*
*/
public class SequenceFileWriterMapper extends Mapper {
/**
* This is the map function, it does not perform much functionality.
* It only writes key and value pair to the context
* which will then be written into the sequence file.
*/
@Override
protected void map(Text key, Text value,Context context) throws IOException, InterruptedException {
context.write(key, value);
}
}
In the code above, you will notice that we are not doing much in the Mapper class. We just take the key and the value and write it in the context. That is the only thing Mapper is required to perform as the data in the context will be stored in the Sequence file. All the magic happens in the Driver class of the MapReduce Job where we will define the job configuration and set the data storage format.
3.4 Driver Class
Driver class is the entry point of the MapReduce job, it is the main function of Java. This is the place where we configure the MapReduce job and set all the required values.
Following is the code of our Driver class:
SequenceFileWriterApp.java
package com.javacodegeeks.examples.sequenceFile;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* The entry point for the Sequence Writer App example,
* which setup the Hadoop job with MapReduce Classes
*
* @author Raman
*
*/
public class SequenceFileWriterApp extends Configured implements Tool
{
/**
* Main function which calls the run method and passes the args using ToolRunner
* @param args Two arguments input and output file paths
* @throws Exception
*/
public static void main(String[] args) throws Exception{
int exitCode = ToolRunner.run(new SequenceFileWriterApp(), args);
System.exit(exitCode);
}
/**
* Run method which schedules the Hadoop Job
* @param args Arguments passed in main function
*/
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.printf("Usage: %s needs two arguments files\n",
getClass().getSimpleName());
return -1;
}
//Initialize the Hadoop job and set the jar as well as the name of the Job
Job job = new Job();
job.setJarByClass(SequenceFileWriterApp.class);
job.setJobName("SequenceFileWriter");
//Add input and output file paths to job based on the arguments passed
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(KeyValueTextInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
//Set the MapClass and ReduceClass in the job
job.setMapperClass(SequenceFileWriterMapper.class);
//Setting the number of reducer tasks to 0 as we do not
//have any reduce tasks in this example. We are only concentrating on the Mapper
job.setNumReduceTasks(0);
//Wait for the job to complete and print if the job was successful or not
int returnValue = job.waitForCompletion(true) ? 0:1;
if(job.isSuccessful()) {
System.out.println("Job was successful");
} else if(!job.isSuccessful()) {
System.out.println("Job was not successful");
}
return returnValue;
}
}
SequenceFileWriterApp class extends the Hadoop Configured class and implements the Tool class. First task in the class is to check if the arguments are present. We need to pass two arguments to this main() function, the input file path and the output file path.

Let’s understand what exactly the code does:
- Line no. 45-47: We create a Job object and set the class of the jar which will be the entry point of MapReduce Job and assign the name to the Job.
- Lines 50-51: We set the input and the output paths which will be provided as the arguments.
- Lines 56-57: These are the most important Job configuration setting for out example. We set the input format which will be the
KeyValueTextInputFormatand the output format which will be theSequenceFileOutputFormat. This tells the Mapper class that the output format needs to be the Sequence File.
<li<Lines 60 and 64: Sets the Mapper class and also informs the Job that there will be no Reducer for this job and it will be MapOnly Job.
3.5 The Output
We are done writing out MapReduce job, now we can run this locally or in the Hadoop cluster and we will have the output on the path provided.
If you would like to know how to execute on Hadoop cluster or locally please following the example: Apache Hadoop Wordcount Example
If you would like to learn more about how to setup the Hadoop cluster, follow the detailed tutorial Apache Hadoop Cluster Setup Example (with Virtual Machines)
We have implemented any kind of compression on the Sequence file, so we will be able to read the file. Following is how the output will look like:
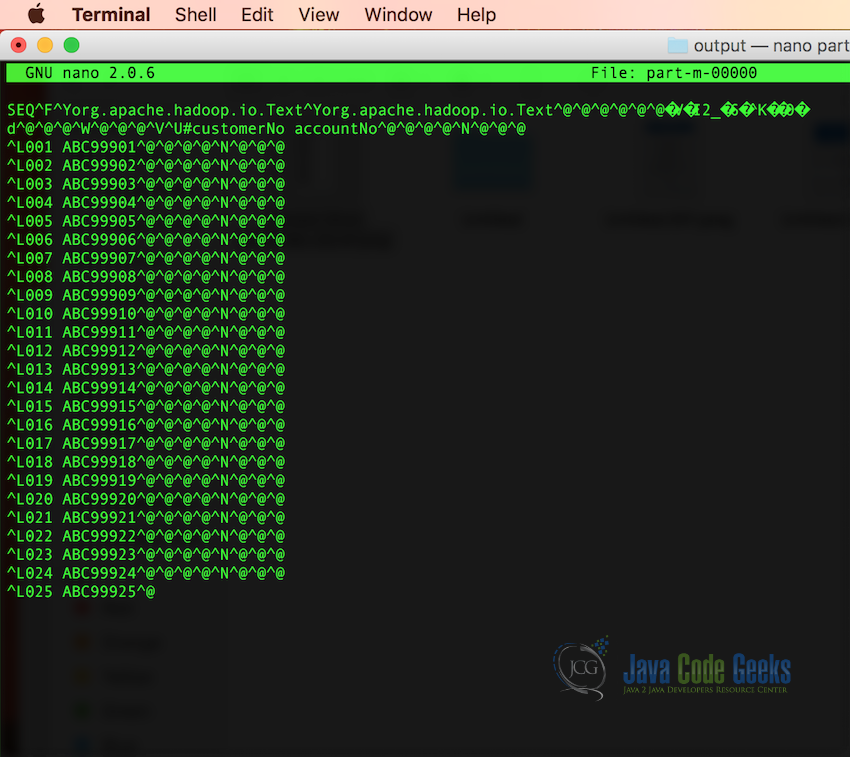
3.6 Reading the Sequence File
We can also read the Sequence files and convert them to the normal text file. For reading the sequence file and writing the data in the text file will not need any change in the Mapper class. Only change will be in the job configuration in the Driver class.
Following is the modified Driver class for the MapReduce job for reading the Sequence File and writing to the Text File:
Note: I have created two completely separate code projects in order to preserve the previous code and to avoid overwriting it so that you can get the complete code with the example. That is why if you notice below there are changes in the class names of the Driver class and also the Mapper Class.
SequenceFileReaderApp.java
package com.javacodegeeks.examples.sequenceFile;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* The entry point for the Sequence Writer App example,
* which setup the Hadoop job with MapReduce Classes
*
* @author Raman
*
*/
public class SequenceFileReaderApp extends Configured implements Tool
{
/**
* Main function which calls the run method and passes the args using ToolRunner
* @param args Two arguments input and output file paths
* @throws Exception
*/
public static void main(String[] args) throws Exception{
int exitCode = ToolRunner.run(new SequenceFileReaderApp(), args);
System.exit(exitCode);
}
/**
* Run method which schedules the Hadoop Job
* @param args Arguments passed in main function
*/
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.printf("Usage: %s needs two arguments files\n",
getClass().getSimpleName());
return -1;
}
//Initialize the Hadoop job and set the jar as well as the name of the Job
Job job = new Job();
job.setJarByClass(SequenceFileReaderApp.class);
job.setJobName("SequenceFileReader");
//Add input and output file paths to job based on the arguments passed
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
//Set the MapClass and ReduceClass in the job
job.setMapperClass(SequenceFileReaderMapper.class);
//Setting the number of reducer tasks to 0 as we do not
//have any reduce tasks in this example. We are only concentrating on the Mapper
job.setNumReduceTasks(0);
//Wait for the job to complete and print if the job was successful or not
int returnValue = job.waitForCompletion(true) ? 0:1;
if(job.isSuccessful()) {
System.out.println("Job was successful");
} else if(!job.isSuccessful()) {
System.out.println("Job was not successful");
}
return returnValue;
}
}
If you notice in the Reader Driver class, there is not much change, first thing you will notice is the change in the class names. But the most important change is in the lines 56 and 57, we have set the input file format to SequenceFileInputFormat and output file format to TextOutputFormat. This way, the MapReduce job will read the Sequence file as the input and write a text file as an ouput after converting it to the readable text.
3.7 Sequence File Compression Setting
In the code examples above, we didn’t use the compression formats for the sake of clarity. If we want to use the compression formats of the Sequence file, we will need to set the configuration in the Driver class itself.
Following are the configurations required for the compression format:
FileOutputFormat.setCompressOutput(job, true); FileOutputFormat.setOutputCompressorClass(job, SnappyCodec.class); SequenceFileOutputFormat.setOutputCompressionType(job,CompressionType.BLOCK);
Here we set the FileOutputFormat to user the compressed output following by setting the compression class to be used, which is SnappyCodec.class in this case. Last setting it to set the compression type which can be either Block or RECORD.
4. Conclusion
This brings us to the conclusion. In this example, we started by learning about the Sequence File, followed by the types of the sequence file which we can make use in Apache Hadoop Ecosystem. Then we dived into the code and saw how to write and read the sequence files using MapReduce job. Feel free to experiment with the code and dig more deep into the Apache Hadoop Ecosystem.
5. Download the Eclipse Projects
These projects contains codes for Reading the Sequence Files and Writing the Sequence Files.
Download the Eclipse projects:
You can download the full source code of SequenceFileWriter here: SequenceFileWriter
You can download the full source code of SequenceFileReader here: SequenceFileReader
