In this example, we are going to show you how to copy large files in inter/intra-cluster setup of Hadoop using distributed copy tool.
1. Introduction
DistCP is the shortform of Distributed Copy in context of Apache Hadoop. It is basically a tool which can be used in case we need to copy large amount of data/files in inter/intra-cluster setup. In the background, DisctCP uses MapReduce to distribute and copy the data which means the operation is distributed across multiple available nodes in the cluster. This makes it more efficient and effective copy tool.
DistCP takes a list of files(in case of multiple files) and distribute the data between multiple Map tasks and these map tasks copy the data portion assigned to them to the destination.
2. Syntax and Examples
In this section, we will check the syntax of DistCP along with some examples.
2.1 Basic
Following is the basic syntac of distCp command.
hadoop distcp hdfs://namenode:port/source hdfs://namenode:port/destination
Following the distcp first argument should be the fully qualified address of the source including the namenode and the port number. Second argument should be the destination address. The basic syntax of distcp is quite easy and symple. It handles all the distribution and copying automatically using MapReduce.
If copying between the same cluster, the namenode and the port number of both source and destination will be same and in case of different cluster both will be different.
Example of basic distcp:
hadoop distcp hdfs://quickstart.cloudera:8020/user/access_logs hdfs://quickstart.cloudera:8020/user/destination_access_logs
Following is the log of the command execution:
15/12/01 17:13:07 INFO tools.DistCp: Input Options: DistCpOptions{atomicCommit=false, syncFolder=false, deleteMissing=false, ignoreFailures=false, maxMaps=20, sslConfigurationFile='null', copyStrategy='uniformsize', sourceFileListing=null, sourcePaths=[hdfs://quickstart.cloudera:8020/user/access_logs], targetPath=hdfs://quickstart.cloudera:8020/user/destination_access_logs, targetPathExists=false, preserveRawXattrs=false, filtersFile='null'}
15/12/01 17:13:07 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
15/12/01 17:13:08 INFO tools.SimpleCopyListing: Paths (files+dirs) cnt = 2; dirCnt = 1
15/12/01 17:13:08 INFO tools.SimpleCopyListing: Build file listing completed.
15/12/01 17:13:08 INFO Configuration.deprecation: io.sort.mb is deprecated. Instead, use mapreduce.task.io.sort.mb
15/12/01 17:13:08 INFO Configuration.deprecation: io.sort.factor is deprecated. Instead, use mapreduce.task.io.sort.factor
15/12/01 17:13:08 INFO tools.DistCp: Number of paths in the copy list: 2
15/12/01 17:13:08 INFO tools.DistCp: Number of paths in the copy list: 2
15/12/01 17:13:08 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
15/12/01 17:13:09 INFO mapreduce.JobSubmitter: number of splits:2
15/12/01 17:13:09 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1449017643353_0001
15/12/01 17:13:10 INFO impl.YarnClientImpl: Submitted application application_1449017643353_0001
15/12/01 17:13:10 INFO mapreduce.Job: The url to track the job: http://quickstart.cloudera:8088/proxy/application_1449017643353_0001/
15/12/01 17:13:10 INFO tools.DistCp: DistCp job-id: job_1449017643353_0001
15/12/01 17:13:10 INFO mapreduce.Job: Running job: job_1449017643353_0001
15/12/01 17:13:20 INFO mapreduce.Job: Job job_1449017643353_0001 running in uber mode : false
15/12/01 17:13:20 INFO mapreduce.Job: map 0% reduce 0%
15/12/01 17:13:32 INFO mapreduce.Job: map 50% reduce 0%
15/12/01 17:13:34 INFO mapreduce.Job: map 100% reduce 0%
15/12/01 17:13:34 INFO mapreduce.Job: Job job_1449017643353_0001 completed successfully
15/12/01 17:13:35 INFO mapreduce.Job: Counters: 33
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=228770
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=39594819
HDFS: Number of bytes written=39593868
HDFS: Number of read operations=28
HDFS: Number of large read operations=0
HDFS: Number of write operations=7
Job Counters
Launched map tasks=2
Other local map tasks=2
Total time spent by all maps in occupied slots (ms)=20530
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=20530
Total vcore-seconds taken by all map tasks=20530
Total megabyte-seconds taken by all map tasks=21022720
Map-Reduce Framework
Map input records=2
Map output records=0
Input split bytes=276
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=94
CPU time spent (ms)=1710
Physical memory (bytes) snapshot=257175552
Virtual memory (bytes) snapshot=3006455808
Total committed heap usage (bytes)=121503744
File Input Format Counters
Bytes Read=675
File Output Format Counters
Bytes Written=0
org.apache.hadoop.tools.mapred.CopyMapper$Counter
BYTESCOPIED=39593868
BYTESEXPECTED=39593868
COPY=2
Line number 35 in the log indicate the number of map tasks executed, which is 2 in this case.
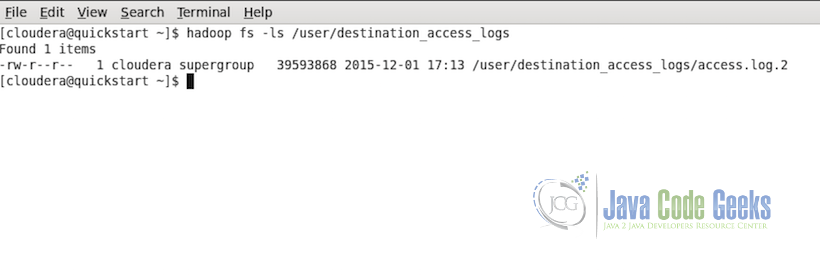
To check if the copy was successful, we can run the following command in HDFS:
hadoop fs -ls /user/destination_access_logs
Below is the output if the copy was successful and data is present in the destination folder:
Note: When the files are copied between the two different clusters, HDFS version on both the clusters should be same or in case of different versions, the higher version should be backward compatible.
2.2 Multiple Sources
In case there are multiple file sources and it need to go to the same destination sources, then all the sources can be passed as the arguments as shown in the example syntax below:
hadoop distcp hdfs://namenode:port/source1 hdfs://namenode:port/source2 hdfs://namenode:port/source3 hdfs://namenode:port/destination
So the files from all the three sources will be copied to the destination specified.
There is another alternative if there are many sources and writing long command becomes an issue. Following is the alternative approach:
hadoop distcp -f hdfs://namenode:port/sourceListFile hdfs://namenode:port/destination
where, the sourceListFile is a simple file containing the list of all the sources. In this case, the source list file need to be passed with the flag -f which indicates that the source is not the file to be copied but a file which contains all the sources.
Note: When distcp is used with multiple sources, in case if the sources collide, distcp will abort the copy with an error message. But in case of collisions at the destination, copying is not aborted but the collision is resolved as per the options specified. If no options are specified, default is that the files already existing at the destination are skipped.
2.3 Update and Overwrite Flag
As the names indicate, update will update the files at the destination folder but only if the update conditions are met. Conditions for update to be performed are that update checks id the destination have the same file name, if the file size and content are same as the source file, if everything is same then the files are not updated but if different the files are updated from the source to destination.

overwrite will overwrite the files at the destination id the destination have same file name, if so, then the file will be overwritten.
hadoop distcp -update hdfs://namenode:port/source hdfs://namenode:port/destination
hadoop distcp -overwrite hdfs://namenode:port/source hdfs://namenode:port/destination
2.4 Ignore Failures Flag
In distcp is any map task fails, it stops the other map tasks also and the copying process halts completely with an error. In case, there is the requirement to continue copying other chunks of data even if one or more map tasks fails we have an ignore failures flag i.e. -i.
hadoop distcp -i hdfs://namenode:port/source hdfs://namenode:port/destination
2.5 Maximum Map Tasks
If the user wants to specify the maximum number of map tasks which can be assigned for distcp execution, there is another flag -m <max_num>.
hadoop distcp -m 5 hdfs://namenode:port/source hdfs://namenode:port/destination
This example command will assign maximum of 5 map tasks to the distcp command.
Example of setting maximum map tasks in distcp:
hadoop distcp -m 1 hdfs://quickstart.cloudera:8020/user/access_logs hdfs://quickstart.cloudera:8020/user/destination_access_logs_3
Here we limit the map task to be 1. From the above example log output we know that default map tasks for this file data is 2.
Below is the log of the command execution:
15/12/01 17:19:33 INFO tools.DistCp: Input Options: DistCpOptions{atomicCommit=false, syncFolder=false, deleteMissing=false, ignoreFailures=false, maxMaps=1, sslConfigurationFile='null', copyStrategy='uniformsize', sourceFileListing=null, sourcePaths=[hdfs://quickstart.cloudera:8020/user/access_logs], targetPath=hdfs://quickstart.cloudera:8020/user/destination_access_logs_3, targetPathExists=false, preserveRawXattrs=false, filtersFile='null'}
15/12/01 17:19:33 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
15/12/01 17:19:34 INFO tools.SimpleCopyListing: Paths (files+dirs) cnt = 2; dirCnt = 1
15/12/01 17:19:34 INFO tools.SimpleCopyListing: Build file listing completed.
15/12/01 17:19:34 INFO Configuration.deprecation: io.sort.mb is deprecated. Instead, use mapreduce.task.io.sort.mb
15/12/01 17:19:34 INFO Configuration.deprecation: io.sort.factor is deprecated. Instead, use mapreduce.task.io.sort.factor
15/12/01 17:19:34 INFO tools.DistCp: Number of paths in the copy list: 2
15/12/01 17:19:34 INFO tools.DistCp: Number of paths in the copy list: 2
15/12/01 17:19:34 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
15/12/01 17:19:35 INFO mapreduce.JobSubmitter: number of splits:1
15/12/01 17:19:35 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1449017643353_0003
15/12/01 17:19:35 INFO impl.YarnClientImpl: Submitted application application_1449017643353_0003
15/12/01 17:19:35 INFO mapreduce.Job: The url to track the job: http://quickstart.cloudera:8088/proxy/application_1449017643353_0003/
15/12/01 17:19:35 INFO tools.DistCp: DistCp job-id: job_1449017643353_0003
15/12/01 17:19:35 INFO mapreduce.Job: Running job: job_1449017643353_0003
15/12/01 17:19:44 INFO mapreduce.Job: Job job_1449017643353_0003 running in uber mode : false
15/12/01 17:19:44 INFO mapreduce.Job: map 0% reduce 0%
15/12/01 17:19:52 INFO mapreduce.Job: map 100% reduce 0%
15/12/01 17:19:52 INFO mapreduce.Job: Job job_1449017643353_0003 completed successfully
15/12/01 17:19:52 INFO mapreduce.Job: Counters: 33
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=114389
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=39594404
HDFS: Number of bytes written=39593868
HDFS: Number of read operations=20
HDFS: Number of large read operations=0
HDFS: Number of write operations=5
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=5686
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=5686
Total vcore-seconds taken by all map tasks=5686
Total megabyte-seconds taken by all map tasks=5822464
Map-Reduce Framework
Map input records=2
Map output records=0
Input split bytes=138
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=45
CPU time spent (ms)=1250
Physical memory (bytes) snapshot=123002880
Virtual memory (bytes) snapshot=1504280576
Total committed heap usage (bytes)=60751872
File Input Format Counters
Bytes Read=398
File Output Format Counters
Bytes Written=0
org.apache.hadoop.tools.mapred.CopyMapper$Counter
BYTESCOPIED=39593868
BYTESEXPECTED=39593868
COPY=2
Map tasks in this example is maximum 1 as indicated in the line 34 of the above log.
3. Final Notes
In this example, we saw the use of distcp command in Apache Hadoop to copy large amount of data. For more help and details about distcp command and all the options available, use the following command to check the built-in help:
hadoop distcp
