This tutorial is for the beginners who want to start learning about Big Data and Apache Hadoop Ecosystem. This tutorial gives the introduction of different concepts of Big Data and Apache Hadoop which will set the base foundation for further learning.
Table Of Contents
1. Introduction
In this tutorial, we are going to look at the basics of big data, what exactly big data is. How to process that amount of data and where Apache Hadoop fits in the processing of big data. This article is for the beginners and will address all the basics needed to understand in order to dive into the Big Data and Hadoop Ecosystem.
2. Big Data?
Data is defined as quantities, characters or symbols on which computers or other computational systems perform operations and which can be stored and transmitted in the form of electronic form.
So based on that, “Big Data“ is also similar data but in terms of size is quite bigger and is growing exponentially with time. Now big is not a quantitative term and different people can have a different definition of how much is big. But there is an acceptable definition of big in the sense of big data. Data which is so large and complex that it can’t be processed or efficiently stored by the traditional data management tools is called “Big Data”.
2.1 Examples of Big Data
Some of the examples of big data are:
- Social Media: Social media is one of the biggest contributors to the flood of data we have today. Facebook generates around 500+ terabytes of data everyday in the form of content generated by the users like status messages, photos and video uploads, messages, comments etc.
- Stock Exchange: Data generated by stock exchanges is also in terabytes per day. Most of this data is the trade data of users and companies.
- Aviation Industry: A single jet engine can generate around 10 terabytes of data during a 30 minute flight.
3. Characteristics of Big Data
Big Data basically have three characteristics:
- Volume
- Variety
- Velocity
3.1 Volume
The size of data plays a very important role in getting the value out of data. Big Data implies that enormous amount of data is involved. Social Media sites, Stock Exchange industry and other machines (sensors etc) generate an enormous amount of data which is to be analyzed to make sense of the data. This makes enormous volume of data as one of the basic characteristics of big data.
3.2 Variety
Variety, as the name suggests indicates data of various types and from various sources. It can contain both structured and unstructured data. With a continuous increase in the use of technology, now we have multiple sources from where data is coming like emails, videos, documents, spreadsheets, database management systems, websites etc. Variety in the structure of data from different sources makes it difficult to store this data but the more complex task it to mine, process and transforms this different structures to make a sense out of it. The variety of data is the characteristic of big data which is even more important that the Volume of data.
3.3 Velocity
Big Data Velocity deals with the pace and steep at which data flows into the receiving system from various data sources like business processes, sensors, social networks, mobile devices etc. The flow of data is huge and continuous many times in real time or near real time. Big data frameworks need to be able to deal with the continuous stream of data which makes a Velocity also one of the main characteristics of Big Data.

4. Types of Big Data
Big Data is generally divided in 3 categories:
- Structured Data
- Semi-structured Data
- Un-structured Data
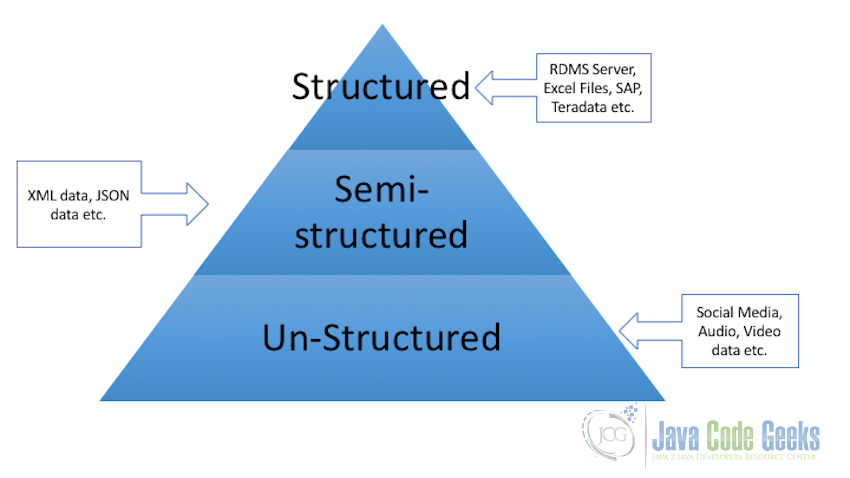
4.1 Structured Data
Any data that can be stored in the form of a particular fixed format is known as structured data. For example, data stored in the columns and rows of tables in a relational database management systems is a form of structured data.
4.2 Semi-Structured Data
Semi-structured data as the name suggests can have data which is structured and the same data source can have data which is unstructured. Data from the different kinds of forms which store data in the XML or JSON format can be categorized as semi-structured data. With this kind of data, we know what is the form of data in a way that we understand what this section of data represent and what another particular set of data represent, but this data may or may not be converted and stored as table schema.
4.3 Un-Structured Data
Any data which have no fixed format or the format can’t be known in advance is categorized as unstructured data. In the case of unstructured data, the size is not the only problem, deriving value or getting results out of unstructured data is much more complex and challenging as compared of structured data. Examples of unstructured data are, a collection of documents residing in the storage of a company or organization which have different structures, contains videos, pictures, audios etc. Almost all the organizations big or small have a huge number of such data lying around but they have no idea how to derive value out of this data.
5. Apache Hadoop
With all this amount and types of data available, we need to process them all to make sense out of it. Businesses need to understand the data so that we can make better decisions. There is no single commercial system easily available which can process this amount of data. To harness the power of big data, we need an infrastructure that can manage and process huge volume of structured and unstructured data and all this should be within the acceptable time limits. This is where Apache Hadoop comes into the picture.
Apache Hadoop is a framework which uses MapRedue programming paradigm and is used to develop data processing applications which can execute in parallel, in a distributed computing setup on top of a cluster of commercial systems.
Apache Hadoop consists of two main sub-projects which makes the base of the Hadoop Ecosystem:
- Hadoop Distributed File System (HDFS): Hadoop Distributed File system as the name indicates is a file system which is distributed in nature. It takes care of the storage part of the Hadoop applications and enables the data to be stored in the distributed fashion on the different systems in the cluster. HDFS also creates multiple replicas of data blocks and distributes them on the different nodes of the cluster. Distribution and replication of data allow rapid computing and extreme reliability in case of failures. HDFS is the open source implementation of Google File System about which Google first published a paper in 2003 named The Google File System
- Hadoop MapReduce: As we discussed above, MapReduce is the programming paradigm and computational model for writing Hadoop applications which run on Hadoop cluster. There MapReduce applications have parallel running jobs which are capable of processing enormous data in parallel on large clusters. Hadoop MapReduce is the open-source implementation of the Google MapReduce. Google wrote a paper on its MapReduce paradigm in 2004 MapReduce: Simplified Data Processing on Large Clusters which became the base of the MapReduce and data processing in cluster computing era.
6. Hadoop Distributed File System (HDFS)
HDFS is designed for storing very large data files which are processed by MapReduce, running on clusters of commodity hardware. HDFS is a fault tolerant as it replicated the data multiple times in the cluster and is also scalable which means that it can be easily scaled based on the requirement.
HDFS cluster consists of two types of nodes:
- DataNode: Datanode are the slave nodes which resides on each machine in the cluster and are responsible for providing the actual storage for the data. DataNode is the one which is responsible for reading and writing files to the storage. Read/Write operations are done at the block level. Default block size in HDFS is set to 64 MB. Files are broken into chunks as per the block sizes and stored in the DataNode. Once the data is stored in blocks, these blocks are also replicated to provide the fault-tolerance in case of hardware failure.
- NameNode: NameNode is the component of HDFS which maintains the metadata for all the files and directories stored in HDFS. NameNode maintains details about all the DataNodes which contains blocks for a particular file.
7. HDFS Working
In this section, we will go through the working of Hadoop Distributed File System. We will look at the Read and Write operation in HDFS.
7.1 Read Operation
Below diagram explains the read operation of HDFS:
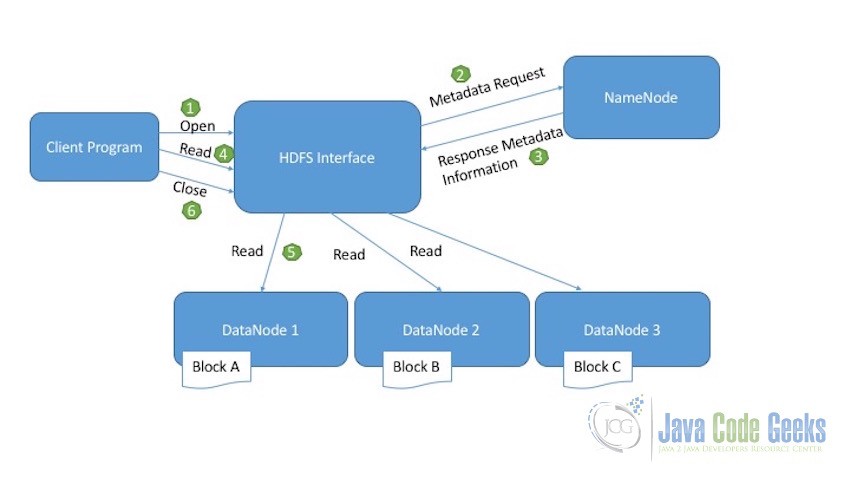
- Client Program which needs to read the file from HDFS initiates the read request by calling the open method.
- HDFS Interface receive the read request and connects to the NameNode to get the metadata information of the file. This metadata information includes location of the blocks of file.
- NameNode sends the response back with all the required metadata information required to access the blocks of data in the DataNodes.
- On receiving the location of the file blocks, the client initiates the read request for the DataNodes provided by the NameNode.
- HDFS interface now performs the actual read activity. It connects to the first DataNode which contains the first block of data. The data is returned from the DataNode as a stream. This continues till the last block of the data is read.
- Once the reading of the last block of data is finished, client send the close request to indicate the read operation is completed.
7.2 Write Operation
Below diagram explains the write operation of HDFS:

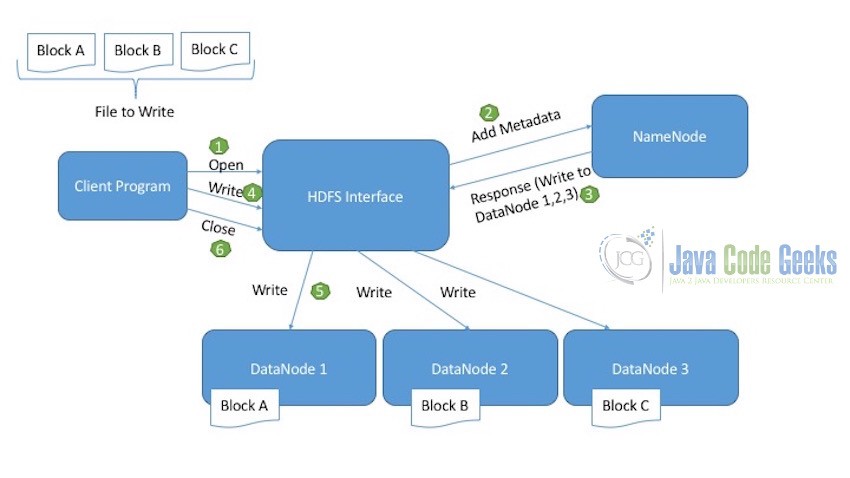
Let’s assume the file we want to write to the HDFS is divided into three blocks: Block A, Block B, Block C.
- Client first of all initiates the read operation indicated by the open call.
- HDFS interface on receiving the new write request, connects to the NameNode and initiates a new file creation. NameNode at this points makes sure the file does not exist already and that the client program has correct permissions to create this file. If the file is already present in HDFS or the Client Program does not have the necessary permissions to write the file, an IOException is thrown.
- Once the NameNode successfully creates the new record for the file to be written in DataNodes, it tells the client where to write which block. For example, write Block A in DataNode 1, Block B in DataNode 2 and Block C in DataNode 3.
- Client then having the sufficient information regarding where to write the file blocks, calls the write method.
- HDFS interface on receiving the write call, writes the blocks in the corresponding DataNodes.
- Once the writing of all the blocks in the corresponding DataNodes is completed, the client sends the close request to indicate that the write operation is completed successfully.
Note: For further reading and understanding of HDFS, I recommend reading Apache Hadoop Distributed File System Explained
8. MapReduce
As we already discussed and introduced, MapReduce is a programming paradigm/framework which is developed for the sole purpose of making possible the processing of “big data”. These MapReduce jobs run on top of Hadoop Cluster. MapReduce is written in Java and it is the primary language for Hadoop but Hadoop also supports MapReduce programs written in other languages like Python, Ruby, C++ etc.
As evident by the name MapReduce programs consists of atleast two phases:
- Map Phase
- Reduce Phase
8.1 How MapReduce Works
MapReduce programs consists of different phases and each phase takes key-value pairs as inputs. Following is the workflow of a simple MapReduce program:
- The first phase of the program is the map phase. Each map phase takes a chunk of input data to process. This chunk is called input split. Complete input is divided into input splits and one map task process one input split.
- Map phase processes the chunk of data it receives. For example, in case of a work count example, map phase reads the data, splits in into words and send the key-value pair with word as key and 1 as value to the output stream.
- Now this output from the multiple map tasks is in random form. So after the map task, shuffling off this data is done to order the data so that similar key-value pairs go to a single reducer.
- Reducer phase of MapReduce, the input values are aggregated. It combines values from the input and returns a single resultant value. For example, in word count program, reduce phase will receive key value pair with words and value as one. If a reducer receives let’s say three key-value pairs for the word “Data”, it will combine all three and the output will be <data,3>
- After the reduce phase finishes processing the data, the MapReduce program ends.
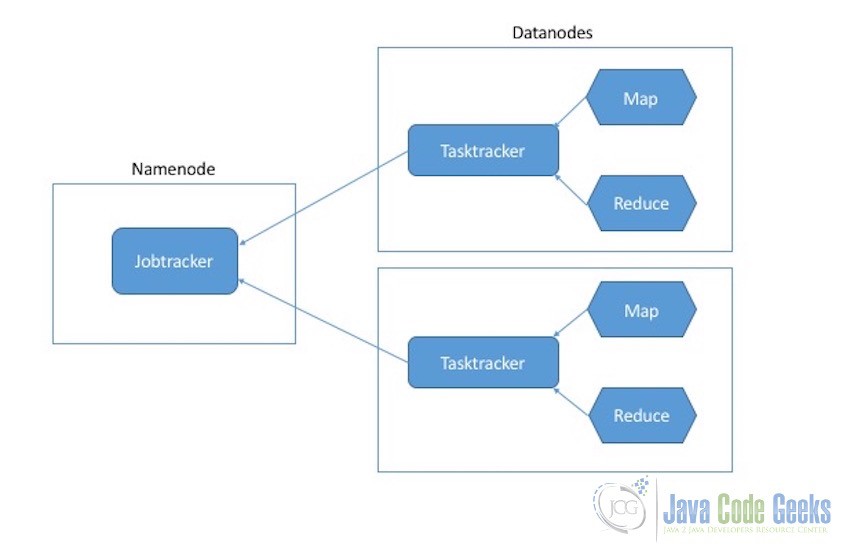
8.2 Execution Process
The execution processes of Map and Reduce tasks is controlled by two types of entities:
- Jobtracker: Job tracker is the master component which is responsible for the complete execution of the overall MapReduce job. For a submitted job, there will always be a one jobtracker running on the Namenode.
- Tasktrackers: Tasktrackers are the slave components they are responsible for the execution of the individual jobs on the Datanodes.
9. Further Readings
This article covers the basics of the Apache Hadoop for the beginners. After this I would like to recommend some other articles to dig a little deeper into the journey of learning Apache Hadoop and MapReduce. Following are some more articles for further reading:
Hadoop Distributed File System
MapReduce
Hadoop Cluster Administration
- How to Install Apache Hadoop on Ubuntu
- Apache Hadoop Cluster Setup Example (with Virtual Machine)
- Apache Hadoop Administration Tutorial
10. Conclusion
In this beginners article, we looked into what exactly Big Data is, different types of big data and we also discussed different characteristics of big data. Then we learned about Apache Hadoop Ecosystem.
Two main sub-projects(components) of Apache Hadoop were discussed i.e. Hadoop Distributed File System and MapReduce framework and how they work in Hadoop on top of the multi-node cluster.
The article is concluded with the links to some important articles for further reading which will cover the most important topics of Apache Hadoop learning once these basics are clear.

The objective of the blog is to give a basic idea on Big Data Hadoop to those people who are new to the platform. This article will not make you ready for the Hadoop programming, but you will get a sound knowledge of Hadoop basics and its core components.