In this article, we will go through the Hadoop Ecosystem and will see of what it consists and what does the different projects are able to do.
1. Introduction
Apache Hadoop is an open source platform managed by Apache Foundation. It is written in Java and is able to process large amount of data (generally called Big Data) in distributed setup on top of a cluster of systems. Hadoop is designed to scale up to thousands of computer system in a cluster in order to process data in parallel.
2. Apache Hadoop
Apache Hadoop framework is designed for keeping in mind scalability and fault-tolerance. When using community hardware, failures are quite common and unavoidable, so the system needs to be capable of handling hardware failures. Hadoop as well as all its components are designed keeping that in mind. Apache Hadoop in itself consists of two main components which form the base of the whole Hadoop ecosystem:
- Hadoop Distributed File System: Hadoop Distributed File system as the name indicates is a file system which is distributed in nature. It takes care of the storage part of the Hadoop applications and enables the data to be stored in the distributed fashion on the different systems in the cluster. HDFS also creates multiple replicas of data blocks and distributes them on the different nodes of the cluster. Distribution and replication of data allow rapid computing and extreme reliability in case of failures. HDFS is the open source implementation of Google File System about which Google first published a paper in 2003 named The Google File System.
- Hadoop MapReduce: MapReduce is the programming paradigm and computational model for writing Hadoop applications which run on Hadoop cluster. There MapReduce applications have parallel running jobs which are capable of processing enormous data in parallel, on large clusters. Hadoop MapReduce is the open-source implementation of the Google MapReduce. Google wrote a paper on its MapReduce paradigm in 2004 MapReduce: Simplified Data Processing on Large Clusters which became the base of the MapReduce and data processing in cluster computing era.
Besides these two main components there are two other components which also helps in the whole ecosystem and not only in Apache Hadoop Framework:
- Hadoop Common: Hadoop Common contains java libraries and utilities which makes the very basic and the common components needed by the ecosystem in many other modules. These are the libraries which allow access to the filesystem, OS level abstraction and other essential java classes for other modules.
- Hadoop YARN: YARN is a resource management framework which is responsible for job scheduling and cluster management for Hadoop. YARN was introduced in Hadoop Framework in version two, so that a common resource management framework can be used so that other modules can also be compatible with Hadoop and Hadoop Ecosystem and grow further.
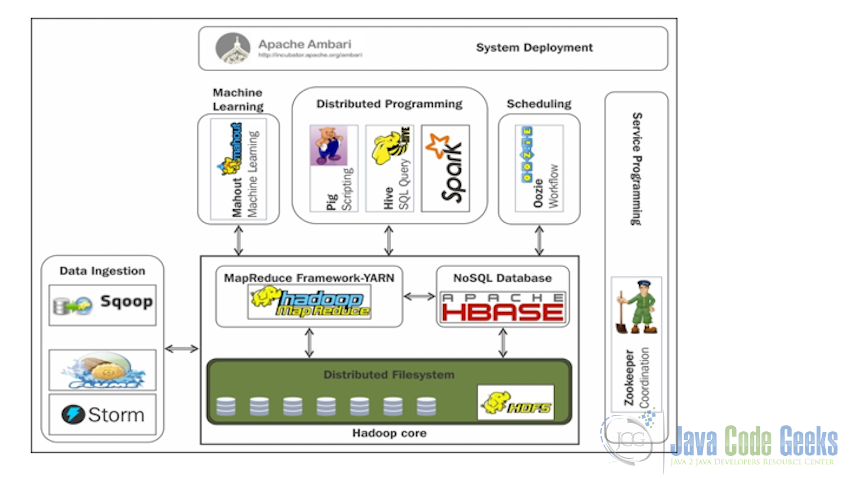
3. Hadoop Ecosystem
After Apache Hadoop became famous and companies started working with Hadoop in production, the demand for more and more components started arising, this was the point where new component started getting added into Hadoop ecosystem. Now Hadoop is far from just being a single project and is more of a Hadoop ecosystem which contains a lot of other projects all of which have Hadoop and HDFS as their base.
Hadoop ecosystem contains both open-source as well as commercial proprietary projects built by companies on top of Hadoop. In this section, we will check few of the projects in Hadoop Ecosystem.
3.1 MapReduce
As we discussed above also, MapReduce is one of the core components of Hadoop Ecosystem. It is the software framework/paradigm to write applications which run parallelly on the cluster of commodity hardware in order to process, analyse and store a large amount of data. Hadoop MapReduce handles data in the fault-tolerant and reliable way.
MapReduce consists of two main components (also called phases):
- Map Phase: This is the phase in which the input is divided and converted into smaller parts and mapped to the corresponding output which will be further processed by the next phase.
- Reduce Phase: This is the second phase of MapReduce, in this phase the data processed and divided into small segments by Map phase is further processed and is reduced to the meaningful output in the database of the file system.
For more details information regarding MapReduce you can have a look ar the following articles:
- Apache Hadoop WordCount Example
- Hadoop Mapper Example
- Combiner are the third kind of components besides Map and Reduce which are quite frequently used. Under the hood, combiners are also just the reducers. Hadoop MapReduce Combiner Example
- Big Data Hadoop Tutorial for Beginners
3.2 Hadoop Distributed File System (HDFS)
Hadoop Distributed File System (HDFS) is also introduced before in the last section. It is the distributed file system on top of which MapReduce is highly dependent. HDFS is also designed keeping in mind fault-tolerance and reliability. When data is pushed to HDFS it splits the data, stores it into distributed fashion and keep the check on replication of these small parts to increase the reliability of the component in case of any failure.
Hadoop Distributed File System also consists of two components:
- NameNode: Namenode is the compoent which is the master of HDFS. It maintains the metadata of the files stored in the system and also the relevant path to the data.
- DataNode: Datanode as the name implies in the component which actually stored the chunks of data processed by Hadoop and stored in HDFS.
For more details about HDFS, follow the links below:
- Apache Hadoop Distributed File System Explained
- Apache Hadoop FS Commands Example
- Hadoop CopyFromLocal Example
3.3 HBase
HBase is the derived term from Hadoop DataBase and as the name specifies, it is the database for Hadoop. HBase is the column-oriented database which is distributed in fashion. HBase uses HDFS at the underlying storage. HBase comes into play when we need real-time access to the data and need to perform random queries and write operation because HDFS as the core works on the principle of write once and read multiple times so we need HBase in the cases where we need instant and frequent write operations and that too random once.
There are two main components of HBase:
- HBase Master: HBase master is responsible for maintaining the state of the cluster and is responsible for the load balancing on the cluster of HBase.
- Region Server: Region Servers are the component which is deployed on each system of the cluster and this is where the actual data is stored and processes the read and write requests to the database.
3.4 Hive
Hive is the part of the Hadoop Ecosystem which allows the user to write queries in its SQL-like queries in order to process data stored in HDFS and compatible file systems such as Amazon S3. The Hive queries are converted to the MapReudce jobs under the hood and executed to process the data in HDFS and output the result. Hive also provides an SQL-like language called HiveQL with schema on read and transparently converts queries to MapReduce, Apache Tez and Spark jobs.
For detailed understanding of Hive check out Apache Hadoop Hive Tutorial
3.5 Pig
Pig is another component of the Hadoop Ecosystem which is designed to analyze and query huge data sets which consist of high-level language for expressing data analysis programs. It is a high-level platform for creating jobs which runs on top of Apache Hadoop. Pig is competent enough to process and analyze semi-structured data. Apache Pig abstracts the programming from the Java MapReduce idiom into a notation which makes MapReduce programming high level, similar to that of SQL for RDBMSs.
3.6 Oozie
Apache Oozie is an open-source project which is the part of the Hadoop Ecosystem. It is used to create the workflow and automate the process of different job and task scheduling depending on these workflows. From the Apache Hadoop ecosystem, Oozie is designed to work seamlessly with Apache Hadoop MapReduce jobs, Hive, Pig, Sqoop and simple java jars.
There are three type of Oozie jobs:
- Oozie Workflow Jobs: Represented as directed acyclical graphs to specify a sequence of actions to be executed.
- Oozie Coordinator Jobs: Oozie workflow jobs that are triggered by time and data availability.
- Oozie Bundle: Oozie bundle is the packaging manager which handles packaging of multiple coordinator and workflow jobs, and makes it easier to manage the life cycle of those jobs.
To understand Apache Oozie in details and to check out the working example of Oozie, please refer to the article Hadoop Oozie Example
3.7 Mahout
Apache Mahout is the scalable machine learning library which implements different algorithms which can run on top of Hadoop to provide machine learning capabilities on large amount of date.
Mahout contains four groups of algorithms:
- Recommendation algorithms.
- Classification and categorization algorithms.
- Clustering algorithms.
- Frequent itemset mining or Frequent patter mining.
3.8 Zookeeper
Apache Zookeeper is configuration management system. It is a centralized service which maintains the configuration of the system, provides naming and distributed synchronization and group services. It is an open-source server which enables highly reliable distributed coordination in the application which uses it for deployment. ZooKeeper’s architecture supports high availability through redundant services. In case of failure and delayed response from the Zookeeper leader, the application can thus ask another ZooKeeper leader.

ZooKeeper nodes store their data in a hierarchical name space, much like a file system or a tree data structure. Clients applications can read from and write to the nodes and in this way have a shared configuration service.
3.9 Sqoop
Sqoop is the name derived from “SQL-to-Hadoop”. It is the tool developed to efficiently transfer structured relational data from different kind of SQL servers to HDFS so that it can be used in Hadoop MapReduce or Hive. After the initial stage, it is extended and we are able to move the data other way around also i.e. from HDFS to SQL Servers.
3.10 Flume
Flume is the component of Hadoop ecosystem which is designed with a very specific target. Flume framework is designed to harvest, aggregate and move huge amount of log data or text file from various services to Hadoop HDFS. It is a highly reliable, distributed, and configurable tool. Apache Flume has a simple and flexible architecture which is based on streaming data flows and is robust and fault tolerant with tunable reliability mechanisms for failover and recovery.
3.11 Ambari
Apache Ambari is designed to help manage Hadoop clusters. Is consists of softwares for provisioning, managing, and monitoring Apache Hadoop clusters. Ambari provides an intuitive, easy-to-use Hadoop management web UI backed by its RESTful APIs. Amabari is mostly targeted to help system administrators and helps them with provisioning, managing and monitoring the Hadoop cluster.
Hadoop cluster provisioning and ongoing management can be a complicated task, especially when there are hundreds or thousands of hosts involved. Ambari provides a single control point for viewing, updating and managing Hadoop service life cycles.
4. Related Projects
Hadoop ecosystem consists of all the above-mentioned components which are directly related and dependent on Apache Hadoop. There are some other projects which are considered the part of Hadoop Ecosystem and are loosely related and dependent on Apache Hadoop. In this section we will check two such projects:
4.1 Apache Storm
Apache Storm is a free and open source distributed realtime computation system. It was first developed at Twitter and was named Twitter but after twitter made it open-source and contributed it to Apache Foundation it was renamed to Apache Storm.
Apache Storm aims to reliably process unbounded streams of data. It is doing for realtime processing what Apache Hadoop did for batch processing. Some of the use cases of Storm are:
- Realtime analytics
- Online machine learning
- Continuous computation etc.
Apache Storm consists of following components:
- Spouts: A spout is a source of streams in a computation. Typically a spout reads from a queueing broker such as Kestrel, RabbitMQ, or Kafka, but a spout can also generate its own stream or read from somewhere like the Twitter streaming API. Spout implementations already exist for most queueing systems.
- Bolts: A bolt processes any number of input streams and produces any number of new output streams. Most of the logic of a computation goes into bolts, such as functions, filters, streaming joins, streaming aggregations, talking to databases, and so on.
- Topology: A topology is a network of spouts and bolts, with each edge in the network representing a bolt subscribing to the output stream of some other spout or bolt. A topology is an arbitrarily complex multi-stage stream computation. Topologies run indefinitely when deployed.
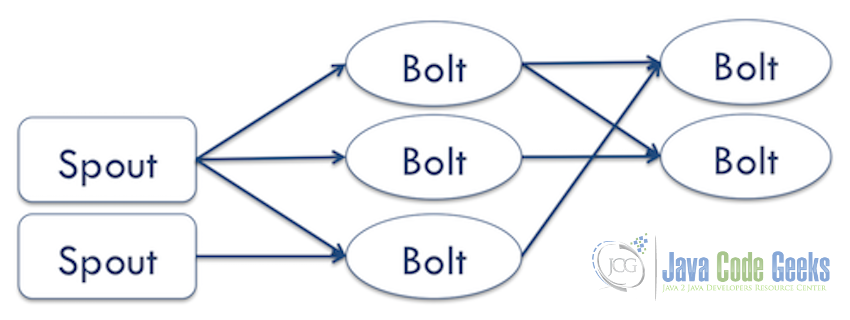
A Storm application is designed as a “topology” in the shape of a directed acyclic graph (DAG) with spouts and bolts acting as the graph vertices. Edges on the graph are named streams and direct data from one node to another. Together, the topology acts as a data transformation pipeline.
4.2 Apache Spark
Apache Spark is an open source cluster computing framework. It was originally developed at the Berkeley’s AMPLab in The University of California and like Apache Storm it was later donated to Apache Software Foundation. Spark provides an interface for programming entire clusters with implicit data parallelism and fault-tolerance.
Apche Spark was developed to overcome some of the bottlenecks of Apache Hadoop. One of the biggest bottleneck which Apache Spark addresses is the intermediate persistent storage. Apache Hadoop stores all the data in HDFS for intermediate processing also, which impact its processing speed. Apache Spark addresses this bottleneck and makes the processing much faster as compare to Hadoop.
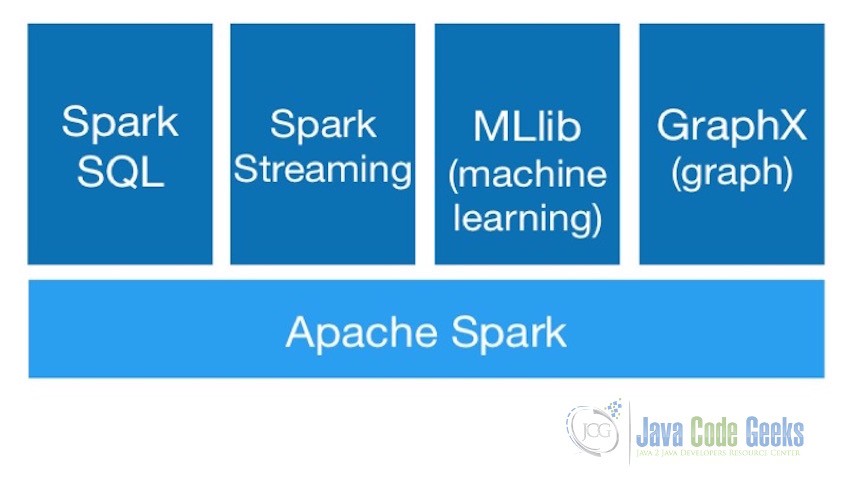
Apache Spark consits of multiple components as shown in the image above:
- Spark Core: Spark Core is the foundation of the overall project. It provides distributed task dispatching, scheduling, and basic I/O functionalities. Spark core provides interfaces for multiple programming languages like Java, Python, Scala, and R.
- Spark SQL: Spark SQL is a component on top of Spark Core that introduces a new data abstraction called DataFrames. Spark SQL provides support for handling structured as well as semi-structured data. It provides a domain-specific language to manipulate DataFrames in Scala, Java, or Python. It also provides SQL language support, with command-line interfaces and ODBC/JDBC server.
- Spark Streaming: Spark Streaming is also based on top of Spark Core and leverages Spark Core’s fast scheduling capability to perform streaming analytics. It ingests data in mini-batches and performs RDD transformations on those mini-batches of data thus providing the capabilities of processing continuous streams of data.
- Spark MLLib: Spark MLlib is a distributed machine learning framework on top of Spark Core. As Apache Spark make use of the distributed memory-based Spark Core architecture it is as much as nine times as fast as the disk-based implementation used by Apache Mahout
- Spark GraphX: GraphX is a distributed graph processing framework on top of Apache Spark Core.
5. Conclusion
Apache Hadoop is a very powerful ecosystem which started with a single project and now consists of a lot of powerful and mutually compatible projects which are easy to integrate and work well with each other. Apache Hadoop gained popularity due to its ability to process and analyze large amount of data efficiently, parallel and with fault-tolerance.
