In this example, we will understand what Apache Hive is, where it is used, basics of Apache Hive, its data types and basic operations.
1. Introduction
Apache Hive is data infrastructure tool which works on top of Hadoop to handle big data. It provides a SQL-like query system to system to interact with the data stored in the Hadoop Distributed File System(HDFS). It makes querying data and analysis of this data quite easy.
Hive was developed by Facebook and then the development moved to the Apache Software Foundation and Hive became the Apache project which made it the integral part of the Hadoop ecosystem.
2. Features
Following are some of the features of Apache Hive:
- Hive provides SQL like query language for querying and manipulating the database. This querying language is called HiveQL or HQL
- It is designed for OLAP (OnLine Analytical Processing) on the data stored in HDFS.
- Hive stores the schema in a database and processed data in Hadoop Distributed File System(HDFS)
- Hive is familiar for people who used SQL, it is fast, scalable and extensible.
- Hive is not designed for OLTP (OnLine Transaction Processing).
3. Data Types
In this section we will check all the available datatypes in Hive. There are four categories of datatypes in Hive:
- Column Types
- Literals
- Null Types
- Complex Types
We will check all these categories in details.
3.1 Column Types
Column Types as the name suggests are the datatypes which are used for columns of the table. Most of the familiar SQL datatypes are also available in Hive. The following list depicts the various column datatypes available:
- TINYINT: Tiny int is the integer type used to store integer values, it has a postfix “Y”. For example: Integer value 10 is stored as 10Y
- SMALLINT: Small int is also an integer type which uses the postfix of “S”. For example: 10 will be stored as 10S
- INT: Int is the column datatype which is used most frequently and there is not postfix required for the int datatype.
- BIGINT: Similar to INT, BIGINT is used to store integer values which are too big for INT. It has a postfix of “L”. For example: 10 will be stored as 10L in BIGINT column type.
- VARCHAR: VARCHAR is the datatype to store string in the column. The column with VARCHAR datatype can have variable length ranging from 1 to 65355.
- CHAR: CHAR is similar to VARCHAR except that it have fixed length of the string. CHAR datatype have a length limit of 255.
- TIMESTAMP: Timestamp is the datatype to store date and time in the column. Hive supports UNIX type timestamp. The format of the timestamp is “YYYY-MM-DD HH:MM:SS:fffffffff”. The nanosecond precision is option and can be omitted.
- DATE: Date type column datatype are used just to store date information without any time value. The format of the date type is “YYYY-MM-DD”.
- DECIMAL: It is quite clear from the name that this column type is used to store decimal formats with given precision. The syntax of the decimal datatype is DECIMAL(precision, scale)
- UNION: Union is a datatype which is used to represent the collection of heterogeneous column datatypes. The syntax to create a union datatype is UNION<int, double, array<string>>. For example: {1:[“apple”,”orange”]}
3.2 Literals
There are two literal types available in Apache Hive. They are as following:
- Floating Point Types: Floating Point Types are the numbers with decimal points.
- Decimal Type: Decimal types are just the Floating Point Types but with higher limits and capacity to store decimal numbers. The range of the decimal type is -10^-308 to 10^^308
3.3 Null Type
Null type is the special value which is used to represent the null or missing values in the columns. It is represented by the value “NULL”.
3.4 Complex Types
Apache Hive also provide three complex types by default. As the name suggests there are the complex datatypes. Available three complex datatypes are:
- Arrays: Arrays are the datatypes used to store the list of similar type of values, it is similar to how arrays are in any programming language. Syntax of the array complex datatype is ARRAY<data_type>
- Maps: Maps in Apache Hive are also similar to the Map implementation in any of the programming language. It holds the list of key and a value. Syntax of map datatype is MAP<primitive_type, data_type>
- Structs: Struct datatype is hive is used to define a structure. The syntax of defining a struct datatype is STRUCT<col_name : data_type[COMMENT col_comment], …>
4. Basic Operations
In this section, we will see the basic operation which are quite commonly required by the Hive users. These basics operations will be performed in the command prompt.
4.1 Creating Database
Hive is basically a database technology so it will obviously have databases on the top level. The following command is required to create a database in Apache Hive.
Syntax:
CREATE DATABASE|SCHEMA [IF NOT EXISTS] <database name>
Example:
#Usind DATABASE command CREATE DATABASE exampledb; #Using SCHEMA command CREATE SCHEMA exampledb;
Following screenshot shows the example in the console:
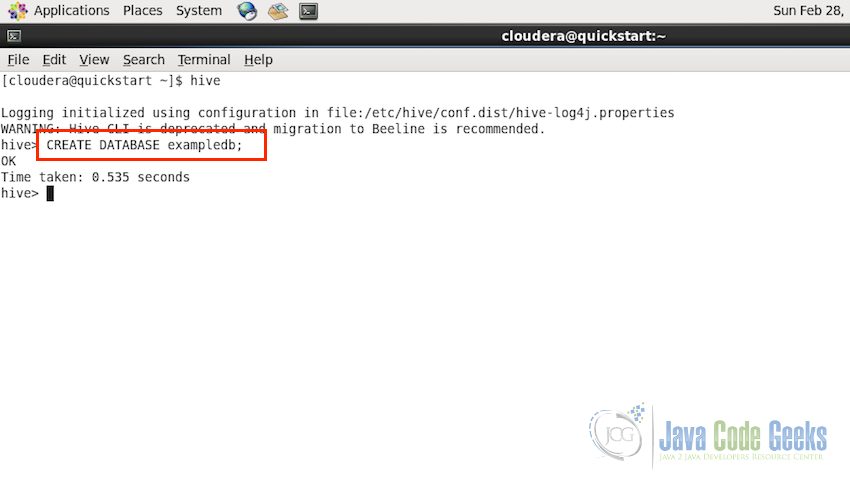
Both DATABASE or SCHEMA can be used interchangeably followed by the database name. IF NOT EXISTS is an optional parameter which specify that database will only be created if the database with the same name does not exist already.
4.2 Viewing and Selecting Databases
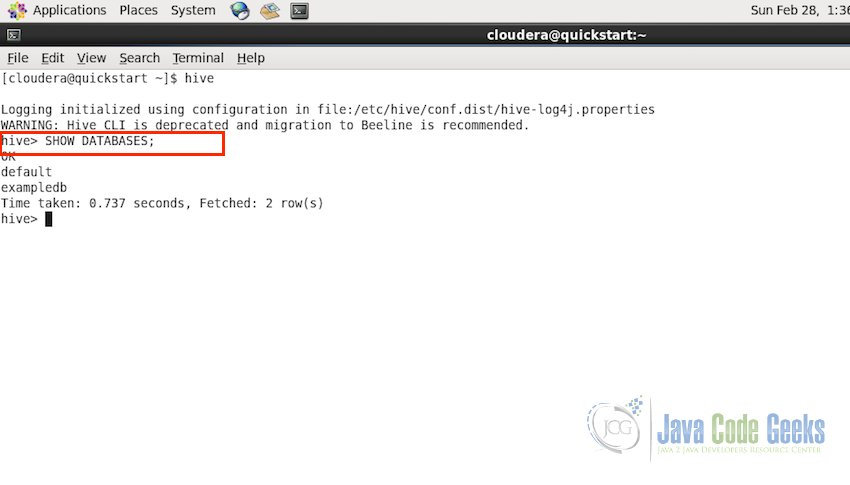
Following query is used to view the list of all the existing databases:
SHOW DATABASES;
at this point, it will show two databases, exampledb which we created in the previous step and default which is the default database available in Apache Hive.
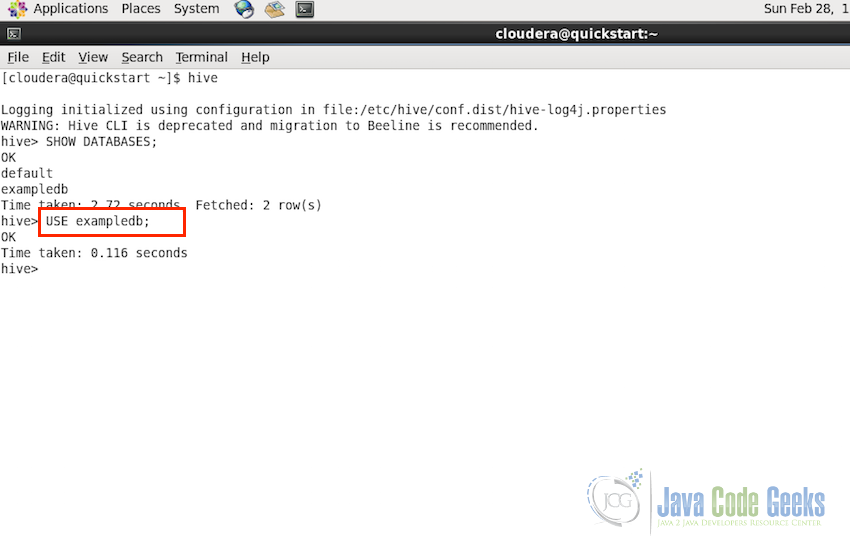
To select the database we created for further query execution, we can select the databse using the following command:
USE database_name;
Following screenshot shows the statement in action:
4.3 Create Table
Now after we have created a database/schema, now it is time to create a table in the database.
Syntax:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [ROW FORMAT row_format] [STORED AS file_format]
Following is the basic example to creating a table:
CREATE TABLE IF NOT EXISTS users (userid int, firstname String, lastname String, address String) COMMENT ‘Users Table’ ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ LINES TERMINATED BY ‘\n’ STORED AS TEXTFILE;
With the above command, Hive will create the table users only if it does not already exists. After the successful execution of the command, you will see the output as OK and the time taken to execute the command.

4.4 Insert Data
As we have seen in the previous sections, Hive queries are quite similar to the SQL queries, but in case of inserting data in the table, Apache Hive uses LOAD DATA instead of the usual Insert statement. Now as we execute Hive queries on top of distributed system, there are two ways to load data into the hive tables, one if from Hadoop File System and other is from Local File System. Following is the syntax for loading the data in Hive table:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
For example, lets assume we have a text file in the Local File System with userid, firstname, lastname, address stored.

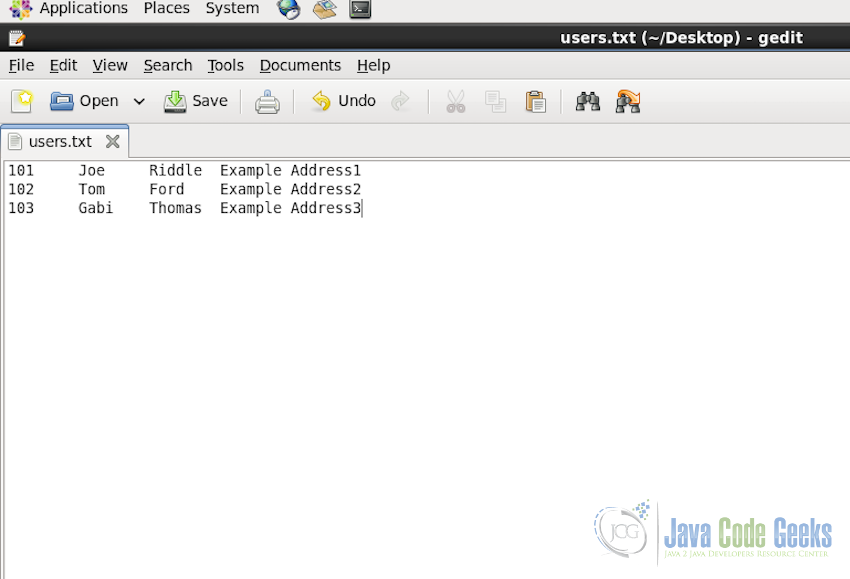
We can load this file into Hive using the following comamnd
LOAD DATA LOCAL INPATH '/home/user/users.txt' OVERWRITE INTO TABLE users
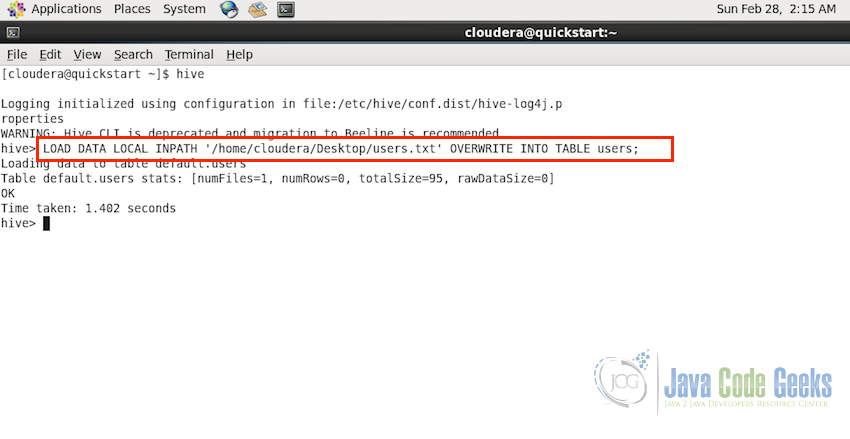
After the successful execution of the command, you will see the output as OK and the time taken to execute the command.
4.5 Select Data
In this section, we will learn about the SELECT statement of Hive Query Language. As we know, select statement is used to select or retrieve data from the database table. Following is the syntax of the select statement:
SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [HAVING having_condition] [CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]] [LIMIT number];
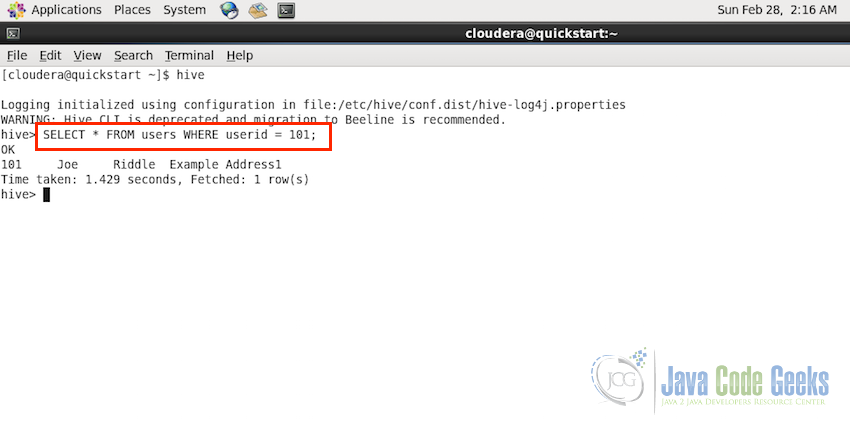
For the example we will use the table users which we have created in the previous sections. Lets assume we have a user entry with the userid 101 and we want to select that particular entry. Following the the example code to perform the required select operation:
SELECT * FROM users WHERE userid = 101
As we can see the select statement is exactly identical to the SQL select statement.
Following screenshots shows the select statement and the output in the Hive console:
4.6 Alter Table
Now we will see how to alter the table if needed. We can change or alter the attribute of the table like table name, column names, adding or removing columns etc. Following is the alter table syntax for Apache Hive
ALTER TABLE name RENAME TO new_name ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...]) ALTER TABLE name DROP [COLUMN] column_name ALTER TABLE name CHANGE column_name new_name new_type
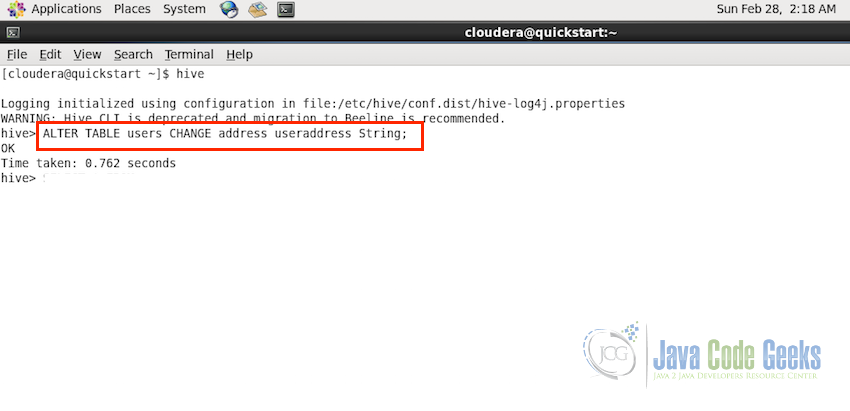
Following are the example of the above statements:
#Changing the table name from users to userdetails ALTER TABLE users RENAME TO userdetails; #Changing the column name from address to useraddress. #If you have renamed the table in database using the previous command, make sure to use the new name ALTER TABLE users CHANGE address useraddress String; #Adding new column to the table ALTER TABLE users ADD COLUMNS (officeaddress STRING COMMENT 'Office Address'); #Dropping the column ALTER TABLE users DROP COLUMN officeaddress
Screenshot shows the ALTER for changing the column name and the output in the console:
4.7 Drop Table
There will for sure be the cases, when we need to drop the complete table from the database. For dropping the complete table, following is the syntax:
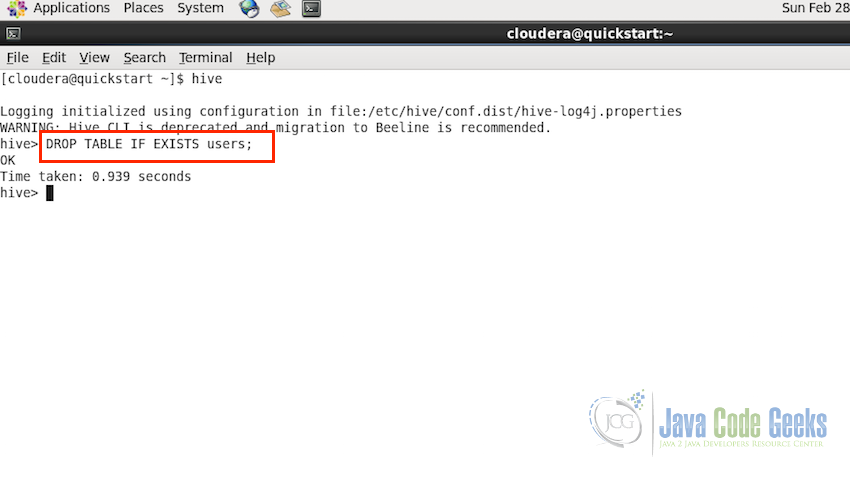
DROP TABLE [IF EXISTS] table_name;
Following the example for dropping the users table we created and modified in the previous sections:
DROP TABLE IF EXISTS users;
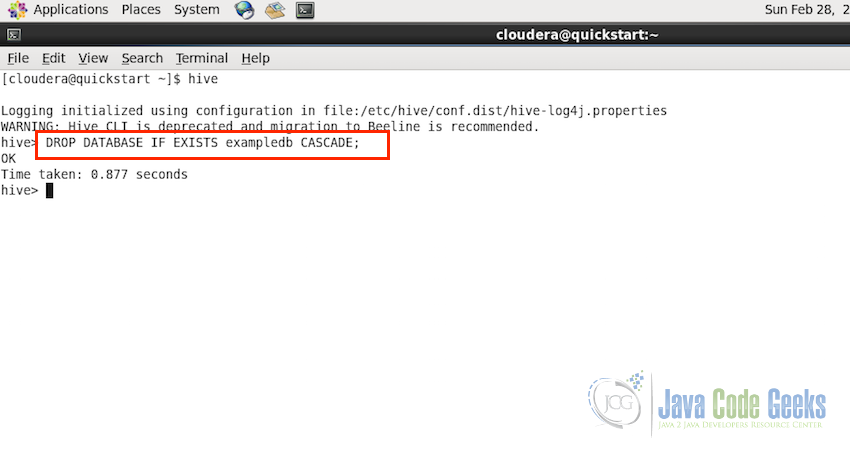
4.8 Drop Database
In case we need to drop the complete database from Apache Hive, Hive provides the statement for that also. We can use either DROP DATABASE or DROP SCHEMA for the task, the usage of both database or schema is same. It will drop all the tables along with any data it contains and then deletes the database. The syntax for the dropping database statement is as following:
DROP DATABASE (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
Following are the example using both Database and Schema:
#Example using DATABASE and using CASCADE DROP DATABASE IF EXISTS users CASCADE; #Example using SCHEMA DROP SCHEMA users;
5. Conclusion
In this article, we have seen the basic Apache Hive tutorial. We started with the introduction to Apache Hive followed by the basic features of Hive and the different data types which Hive offers by default. Following this we saw how some of the basic operations works in Hive and how they are somewhat identical to the SQL statements which we are generally familiar with, this makes learning and using Apache Hive quite easy for an experienced SQL users.
