In this example, we will understand the CopyFromLocal API of Hadoop MapReduce and various ways it can be used in the applications and maintenance of the clusters.
We assume the previous knowledge of what Hadoop is and what Hadoop can do? How it works in distributed fashion and what Hadoop Distributed File System(HDFS) is? So that we can go ahead and check some examples of how to deal with the Hadoop File System and in particular how to use copyFromLocal command. We will need a working Hadoop System for that, either a single node cluster or multi-node cluster. Following are two examples which can help you if you are not well familiar with Apache Hadoop and how to setup Hadoop:
- Hadoop “Hello World” Example
- How to Install Apache Hadoop on Ubuntu
- Apache Hadoop Cluster Setup Example (with Virtual machines)
1. Introduction
The File System(FS) include various commands which are much like shell commands. Most of the people working with shell commands will find Hadoop File System commands familiar.
These commands interact directly with the Hadoop Distributed File System(HDFS) as well as other file systems that are supported by Hadoop. For example, Local File System, HFTP File System, S3 File System etc.
One of the most frequently used command in Hadoop File System is copyFromLocal, we will look into this command in this example.
2. copyFromLocal
The Hadoop copyFromLocal command is used to copy a file from the local file system to Hadoop HDFS. While copying files to HDFS using copyFromLocal there is one restriction that is the source of the files can only be local file system.
copyFromLocal file comes with an optional parameter -f which can be used if we want to overwrite some files which already exist in file system. This can be useful when we want to update some file and copy again. By default, if we try to copy a file which already exists at the same directory path, an error will be thrown. So one way is to first delete the file from the file system and then copy again or another way is to use the option -f with the command. We will see this in action in the later section.
3. Shell Interface
The File System(FS) can be invoked by the following command:
hadoop fs <args>
FS shell commands are almost same as Unix commands and behave similar to the corresponding Unix commands. When the command is executed, the output is sent to stdout and in case of any error, error details are sent to stderr
Note: In case the Hadoop Distributed File System (HDFS) is used as a File System (FS) for Hadoop (which is the default implementation), we can also use:
hdfs dfs
as synonyms to
hadoop fs
The usage of copyFromLocal command is as following:
hadoop fs -copyFromLocal <local_file_source> URI
There is an optional parameter which can be passed with the command, the -f option will overwrite the destination if it already exists.
hadoop fs -copyFromLocal -f <local_file_source> URI
Following are the steps we need to perform to use the command copyFromLocal from shell:
3.1 Making directory in HDFS
First step we would like to do is to make a separate directory for the example
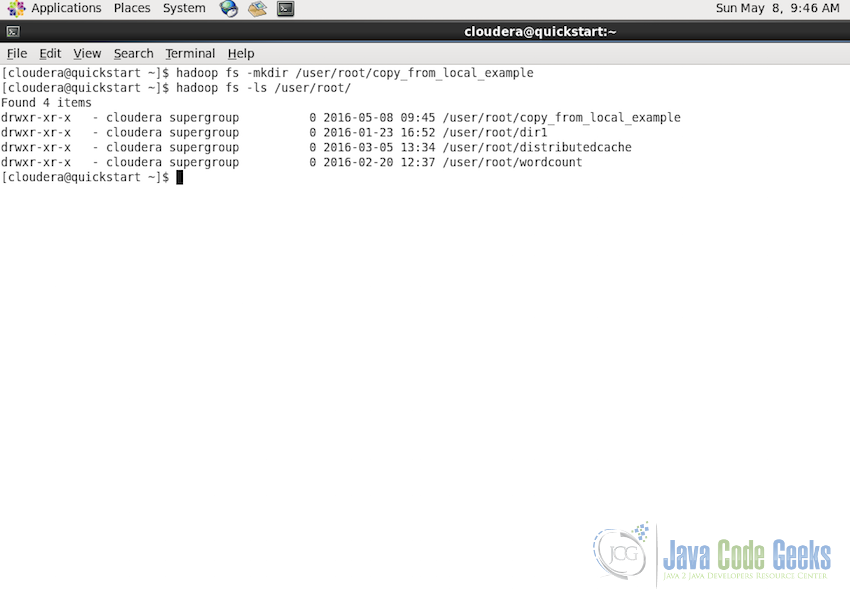
hadoop fs -mkdir /user/root/copy_from_local_example
This will make a directory by the name copy_from_local_example on the path /user/root/ in HDFS. We can confirm the directory is present using the command:
hadoop fs -ls /user/root/
Following is the screenshot of the above commands in the shell, notice the directory is created with the given name:
3.2 Copying a local file to HDFS
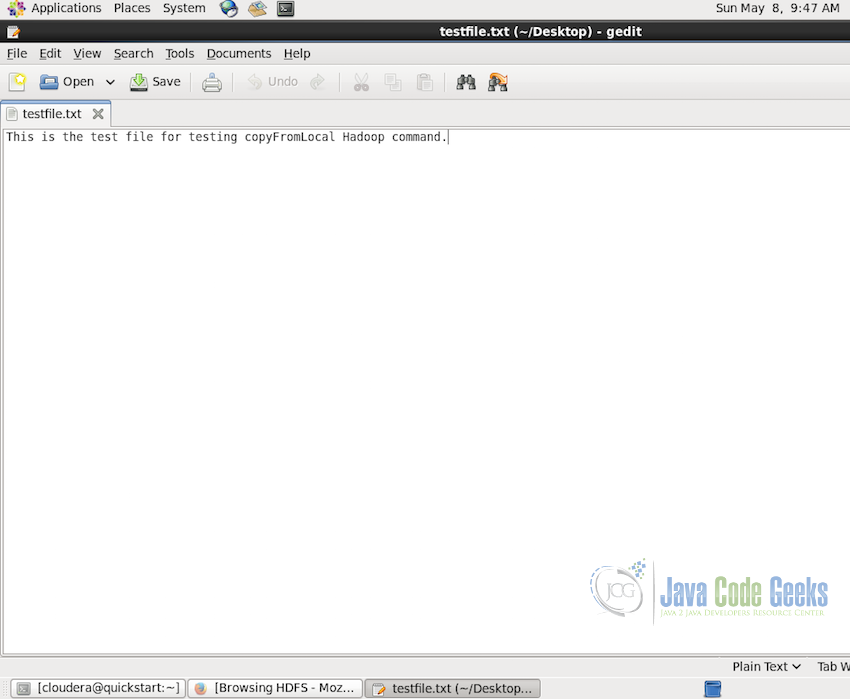
Once we have the directory where we want to copy out file, we are ready to test the command but first we will need a test file which we will copy, for this we created a testfile.txt with some dummy data on the desktop itself.
Now we will use the following command to copy this test file to HDFS:
hadoop fs -copyFromLocal Desktop/testfile.txt /user/root/copy_from_local_example
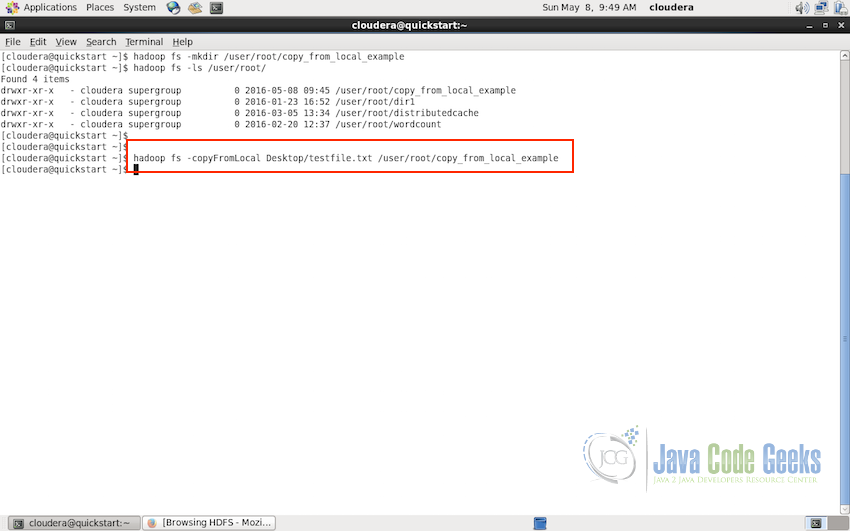

The above command will not output any message on successful execution of the command, so we can use the ls command to make sure the file is copied:
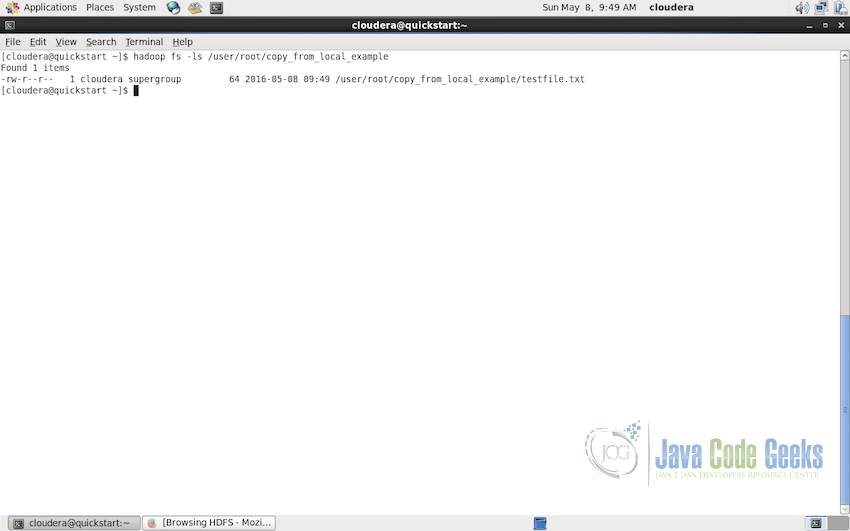
hadoop fs -ls /user/root/copy_from_local_example
As shown in the following screenshot, the file will be listed in the output:
This is the example of how copyFromLocal command works. But sometimes there can be a requirement to copy the updated version of files in the HDFS but the old version of files are already present in the HDFS. In which case, we need to use the -f parameter option with the command, as shown in the next section.
3.3 Overwriting existing files in HDFS
Sometimes, we already have files in HDFS and later on we need to replace/overwrite those files with the new version of the files, in this case the names of the files will be same as already present in the HDFS. Now copyFromLocal does not overwrite the file by default. If we try to execute the command to copy the files in the same directory with the same name, it will give error as showin in the screenshot below:
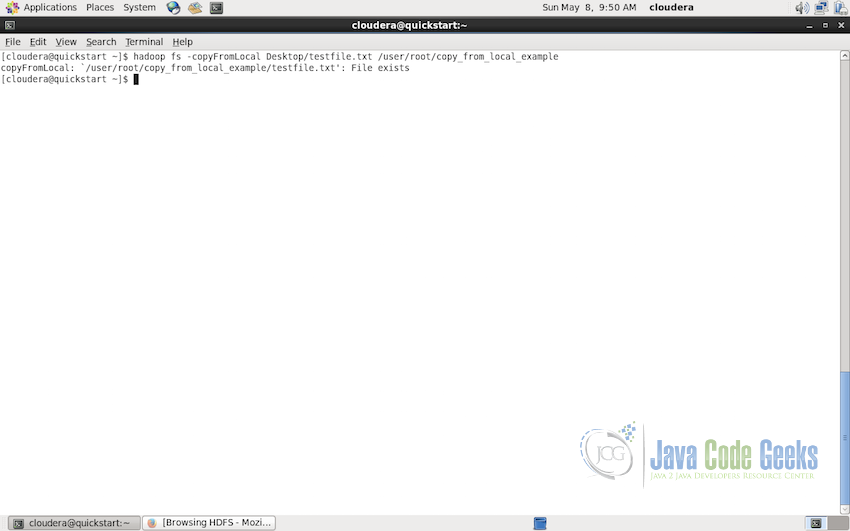
For such cases, copyFromLocal command is available with an optional parameter -f which will overwrite the existing files in HDFS. Following is the command to overwite/replace the testfile.txt on the same directory path as before:
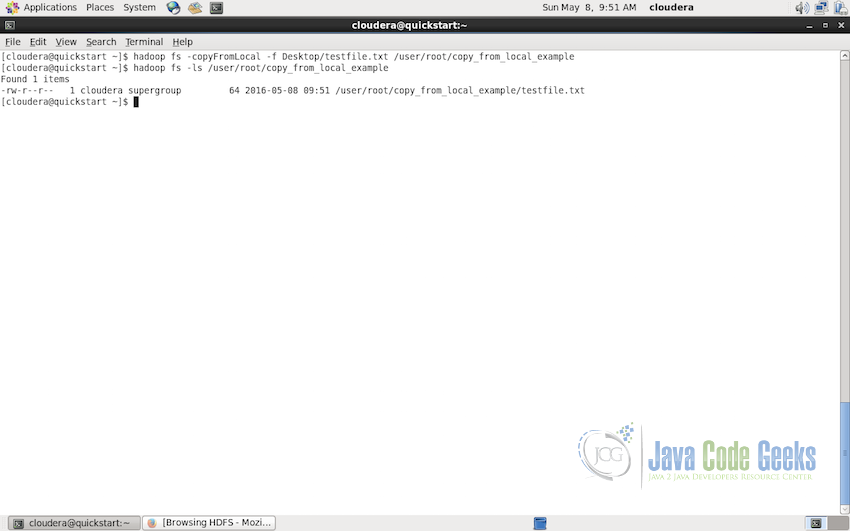
hadoop fs -copyFromLocal -f Desktop/testfile.txt /user/root/copy_from_local_example
This will replace the old file if there is no error in the command line that indicates the file is overwritten successfully, as shown in the screenshot below. We can use the ls to verify if the file is present and as we can see in the screenshot below the timestamp is of 09:51 as compared to 09:49 when the file was initially copied(timestamp shown in the screenshot in section 3.2).
4. Conclusion
This brings us to the end of the example. In this article, we started with the Introduction to the Hadoop File System followed by understanding the copyFromLocal command which was followed by the introduction to the shell interface of Hadoop and step by step example of how to use copyFromLocal to copy files from the local system to the Hadoop Distributed File System(HDFS).
If you are interested in learning about some more commonly used shell commands of Hadoop, please read the article Apache Hadoop FS Commands Example for more commands and the example of how to use those commands.
