Log-structured merge Trees (LSM Trees) represent a groundbreaking approach to managing data in modern storage systems and databases. In this introduction to LSM Tree, we will help you learn what an LSM Tree is, its key benefits and features but also its drawbacks so as to properly utilize it for maximum performance gains.
1. Introduction
A Log Structured Merge Tree (LSM Tree) is a popular data structure used to efficiently manage and organize data for fast read and write operations, particularly used in storage systems and databases. Modern distributed and NoSQL databases like Apache Cassandra, RocksDB, and Apache HBase use LSM trees to improve read and write performance and to efficiently organize and manage data.
2. Basic Concepts of Log Structured Merge (LSM) Trees
LSM Tree is used in various storage systems and databases due to its ability to provide fast write performance and manage large volumes of data effectively. The core idea behind an LSM Tree is to optimize write operations while maintaining reasonable read performance. Here are the concepts and key components of LSM Trees.
2.1 Memtable
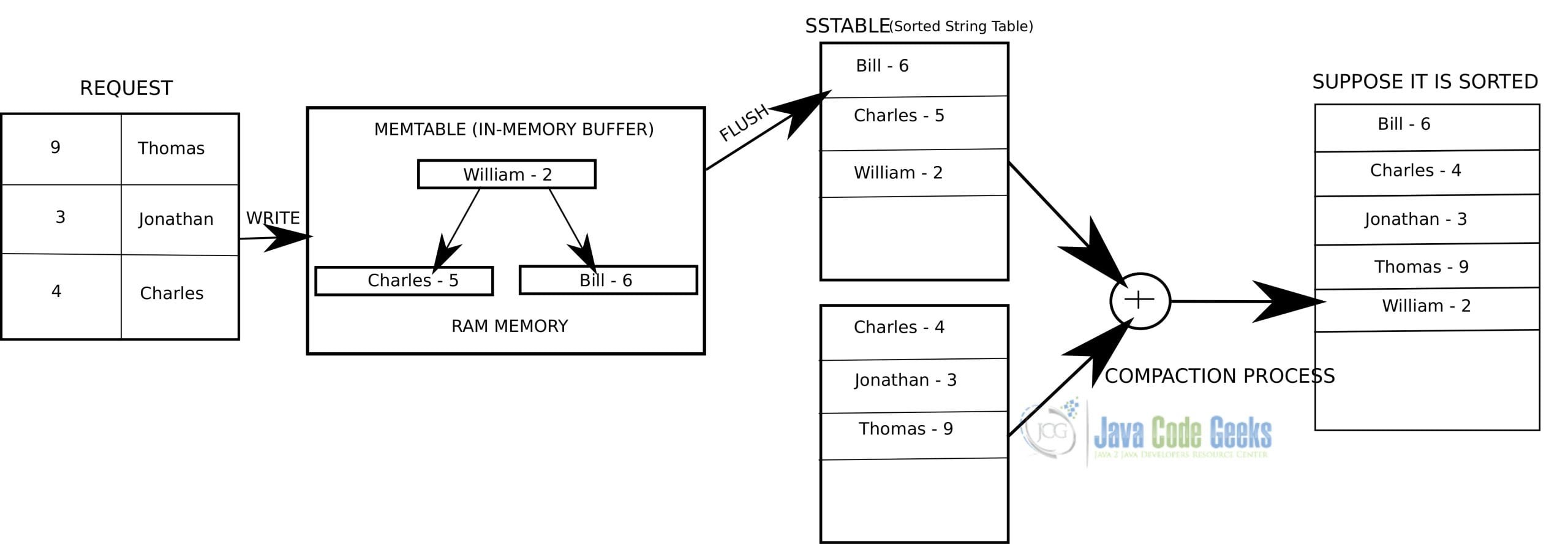
A data structure that temporarily stores data in memory prior to its transfer to disk.
A memtable (memory table) serves as an in-memory buffer that temporarily holds recently written data before it is persisted to disk in a more permanent format. Incoming write operations are first stored in a memtable. A memtable is a crucial component for achieving fast write performance in systems that manage large volumes of data.
Some key characteristics of a memtable are:
- In-Memory Storage: A memtable is an in-memory data structure where new data is first stored before being flushed to disk.
- Write-Ahead Logging (WAL): A write-ahead log is often used alongside a memtable to ensure data durability. Data is first written to the WAL, providing a record of changes that can be used for crash recovery. Once the data is safely in the WAL, it is then written to the memtable.
- Frequent Flushing: A memtable can become full relatively quickly, especially in write-intensive workloads. In such occurrences, the contents are flushed to disk as an immutable structure as a Sorted String Table (SSTable).
- Temporary Storage: The memtable is a temporary storage structure. Its purpose is to hold recently written data until it can be persisted to disk in a more structured and permanent format.
- Sequential Writes: Data is added to the end of the memtable sequentially, making write operations efficient and minimizing the overhead of updating existing data.
- Crash Recovery: In case of system failures, the data stored in the WAL and memtable can be used to restore the most recent consistent state of the data. This contributes to data durability and reliability.
2.2 SSTables (Sorted String Tables)
A data structure that stores a large number of key-value pairs sorted by their keys and remains unchangeable after creation. (An Immutable data structure)
Periodically, the data in a memtable is flushed to disk as immutable SSTables. These SSTables are sorted by keys and stored on a disk in an organized manner, making it efficient for read operations and enabling data to be accessed in a predictable order.
SSTables provide many key advantages. Some key benefits of SSTables are:
- Efficient Data Retrieval: SSTables are sorted by keys, enabling efficient data retrieval through optimized search algorithms thereby reducing the time complexity of data retrieval operations.
- Write Performance: SSTables contribute to efficient write operations. Data is first written to in-memory buffers (memtable) and then flushed to disk as an SSTable.
- Reduced Disk Seeks: The sorted nature of SSTables means that disk seeks can be minimized during read operations.
- Historical Snapshots: Each SSTable represents a snapshot of the data at a specific point in time. This historical representation is useful for maintaining versioned data.
- Scalability: SSTables can be efficiently distributed across different storage devices or nodes in a distributed system. This scalability allows storage systems to handle large datasets.
- Immutable Structure: Once data is written to an SSTable, it is typically considered immutable. This simplifies concurrent read and write operations since there’s no need to worry about data modification.
2.3 Compaction Process
The compaction process is a fundamental mechanism that helps maintain efficient data storage and retrieval while managing the trade-offs between read and write performance. Compaction involves merging and organizing data stored in multiple levels of an LSM Tree to eliminate duplicate keys, improve data locality, and optimize disk space usage.
2.3.1 Motivation for Compaction
As new data is written and flushed to disk in an LSM Tree, multiple SSTables accumulate in different levels. These levels contain overlapping data, and duplicate keys may exist in multiple SSTables, leading to inefficiencies in read operations.
Here is how the compaction process works:
- Identification of Overlapping Data: The compaction process begins by identifying SSTables in the same level or across levels that have overlapping key ranges. These are the SSTables that need to be merged and organized.
- Merge and Sorting: During compaction, the data from overlapping SSTables is merged into a new SSTable at a higher level or the same level, depending on the compaction strategy. Data is sorted based on keys during the merge process to ensure consistent ordering.
- Duplicate Elimination: During the merge, duplicate keys are detected and resolved. The most recent version of a key is retained, and older versions are discarded. Eliminating duplicate keys reduces the chances of redundant data in the LSM Tree.
- Writing Compact SSTables: The merged data is written to a new SSTable, which is created as a result of compaction. This new SSTable contains a subset of the data from the original SSTables but is organized in a more efficient manner.
- Cleaning Up Old SSTables: After successful compaction, the original overlapping SSTables become obsolete and can be safely deleted to free up disk space.
3. Advantages and Disadvantages of LSM (Log Structured Merge) Tree
3.1 Advantages of LSM Tree
LSM Trees offer several advantages for managing data in various storage systems and databases, particularly in scenarios with write-intensive workloads and large volumes of data. Listed below are some of the key advantages of LSM Trees.
- Write Performance: By initially storing new data in an in-memory buffer (memtable) and then flushing it to disk, LSM Trees provide fast and sequential write performance. Also, the separation of write operations from read operations results in faster write performances.
- Scalability: LSM Trees are useful for handling large volumes of data and scaling across distributed systems. They can be distributed across multiple nodes, making them suitable for applications that need to grow over time.
- Versioning and Snapshots: LSM Trees support versioning and snapshots of data due to their immutability and multi-level structure.
- High Write Throughput: Applications that require high write throughput, such as real-time event tracking, can benefit from LSM Trees’ ability to handle frequent write operations.
- Sequential Disk Writes: Write operations in LSM Trees are often sequential, leading to more efficient disk writes.
3.2 Disadvantages of LSM (Log Structured Merge) Tree
While LSM Trees offer many advantages, they also come with some disadvantages that need to be considered when using them. Some of the disadvantages of LSM Trees include:
- Complex Read Operations: The multi-level structure of LSM Trees can make read operations more complex compared to traditional data structures. Data must be searched across multiple levels, potentially resulting in higher latency for some read operations.
- Read Amplification: The need to search through multiple levels during read operations can lead to read amplification. In some cases, multiple SSTables may need to be accessed to retrieve a single piece of data potentially impacting read performance.
- Write Amplification: The compaction process in LSM Trees can lead to write amplification. When data is merged and compacted, it might be written multiple times, which increases the total number of write operations performed.
- Memory Consumption: LSM Trees often use in-memory components like memtables, which can consume a significant amount of memory.
- Limited Support for Range Queries: Range queries that span multiple SSTables can be less efficient in LSM Trees compared to traditional B-trees. This is because range queries may involve searching through multiple levels thereby impacting performance.
4. Conclusion
In this article, we have discussed and explored the key concepts and components of LSM Trees such as Memtables, SSTables, and Compaction.
In conclusion, the Log Structured Merge Tree (LSM Tree) is a data structure that has changed the way modern databases and storage systems manage data. LSM Tress addresses the challenges created by write-intensive workloads and large datasets and offers a very good approach to data storage and retrieval through the use of memtables (in-memory buffers), disk-based storage, and a multi-level organization.
