Apache Kafka is an open-source stream-processing software platform developed by the Apache Software Foundation. Kafka uses topics, partitions, and replication to manage data organization, parallel processing, and fault tolerance. It is designed to handle high-throughput, fault-tolerant, and scalable real-time data streaming. Kafka is often used for building real-time data pipelines and streaming applications. It enables the seamless integration of various data sources and applications, allowing them to communicate and process data in real time.
1. Introduction
Kafka is an open-source distributed streaming platform developed by LinkedIn and later donated to the Apache Software Foundation. It was designed to handle real-time data streams, making it a highly scalable, fault-tolerant, and distributed system for processing and storing large volumes of event data. Kafka is widely used for various use cases, such as log aggregation, event sourcing, messaging, and real-time analytics.
1.1 Key Concepts
- Topics: Kafka organizes data streams into topics, which are similar to categories or feeds. Each topic consists of a stream of records or messages.
- Producers: Producers are applications that publish data to Kafka topics. They write messages to specific topics, and these messages are then stored in the Kafka brokers.
- Brokers: Kafka brokers are the nodes that form the Kafka cluster. They are responsible for receiving, storing, and serving messages. Each broker holds one or more partitions of a topic.
- Partitions: Topics can be divided into multiple partitions, which are essentially ordered logs of messages. Partitions allow data to be distributed and processed in parallel across different brokers.
- Consumers: Consumers are applications that read data from Kafka topics. They subscribe to one or more topics and receive messages from the partitions of those topics.
- Consumer Groups: Consumers can be organized into consumer groups, where each group consists of one or more consumers. Each message in a partition is delivered to only one consumer within a group, allowing parallel processing of data.
1.2 How does Kafka work?
- Data Ingestion: Producers send messages to Kafka brokers. Producers can choose to send messages synchronously or asynchronously.
- Storage: Messages are stored in partitions within Kafka brokers. Each partition is an ordered, immutable sequence of messages.
- Replication: Kafka provides fault tolerance through data replication. Each partition has one leader and multiple replicas. The leader handles read and write operations, while the replicas act as backups. If a broker fails, one of its replicas can be promoted as the new leader.
- Retention: Kafka allows you to configure a retention period for each topic, determining how long messages are retained in the system. Older messages are eventually purged, making Kafka suitable for both real-time and historical data processing.
- Consumption: Consumers subscribe to one or more topics and read messages from partitions. Consumers can process data in real-time or store it in a database for later analysis.
Overall, Kafka has become an essential component in modern data architectures, allowing organizations to handle large-scale event-driven data streams efficiently.
2. What is Docker?
Docker is an open-source platform that enables containerization, allowing you to package applications and their dependencies into standardized units called containers. These containers are lightweight, isolated, and portable, providing consistent environments for running applications across different systems. Docker simplifies software deployment by eliminating compatibility issues and dependency conflicts. It promotes scalability, efficient resource utilization, and faster application development and deployment. With Docker, you can easily build, share, and deploy applications in a consistent and reproducible manner, making it a popular choice for modern software development and deployment workflows. If someone needs to go through the Docker installation, please watch this video. Some benefits of Docker are:
- Portability: Docker containers can run on any platform, regardless of the underlying infrastructure. This makes it easy to move applications between development, testing, and production environments.
- Scalability: Docker allows you to quickly and easily scale your application by adding or removing containers as needed, without having to make changes to the underlying infrastructure.
- Isolation: Docker provides a high level of isolation between applications, ensuring that each container runs independently of others, without interfering with each other.
- Efficiency: Docker containers are lightweight and efficient, consuming fewer resources than traditional virtual machines. This allows you to run more applications on the same hardware.
- Consistency: Docker ensures that applications behave the same way across different environments, making it easier to test and deploy new versions of your application.
- Security: Docker provides built-in security features that help protect your applications from external threats. Docker containers are isolated from each other and the underlying infrastructure, reducing the risk of attacks.
Overall, Docker provides a powerful platform for building, testing, and deploying applications that are both efficient and reliable.
2.1 What is Docker used for?
It is used for –
- For environment replication, while the code runs locally on the machine.
- For numerous deployment phases i.e. Dev/Test/QA.
- For version control and distributing the application’s OS within a team.
3. Setting up Apache Kafka on Docker
Using Docker Compose simplifies the process by defining the services, their dependencies, and network configuration in a single file. It allows for easier management and scalability of the environment. Make sure you have Docker and Docker Compose installed on your system before proceeding with these steps. To set up Apache Kafka on Docker using Docker Compose, follow these steps.
3.1 Creating Docker Compose file
Create a file called docker-compose.yml and open it for editing.
- Zookeeper Service: The
zookeeperservice is defined to run Zookeeper, which is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. The configuration for this service is as follows:- Image: The service uses the latest version of Confluent’s Zookeeper image (
wurstmeister/zookeeper). - Container Name: The name of the container is set to
zookeeper. - Ports: Zookeeper uses port
2181for client connections, which are mapped from the host to the container.
- Image: The service uses the latest version of Confluent’s Zookeeper image (
- Kafka Service: The
kafkaservice is defined to run Apache Kafka, a distributed streaming platform. Here’s how the Kafka service is configured:- Image: The service uses the latest version of Confluent’s Kafka image (
wurstmeister/kafka). - Container Name: The name of the container is set to
kafka. - Ports: Kafka uses port
9092for client connections, which are mapped from the host to the container. - Environment Variables: Several environment variables are set to configure Kafka. Notably,
KAFKA_ZOOKEEPER_CONNECTspecifies the Zookeeper connection string,KAFKA_ADVERTISED_LISTENERSdefines the listener for client connections, andKAFKA_CREATE_TOPICScreates a topic namedmy-topicwith 1 partition and a replication factor of 1. - Depends On: The Kafka service depends on the
zookeeperservice, ensuring Zookeeper is running before Kafka starts.
- Image: The service uses the latest version of Confluent’s Kafka image (
Add the following content to the file and save it once done.
docker-compose.yml
version: '3'
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_LISTENERS: INSIDE://kafka:9092,OUTSIDE://localhost:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_LISTENERS: INSIDE://0.0.0.0:9092,OUTSIDE://0.0.0.0:9093
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_CREATE_TOPICS: "my-topic:1:1"
depends_on:
- zookeeper
3.2 Running the Kafka containers
Open a terminal or command prompt in the same directory as the docker-compose.yml file. Start the Kafka containers by running the following command:
Start containers
docker-compose up -d
This command will start the ZooKeeper and Kafka containers in detached mode, running in the background.
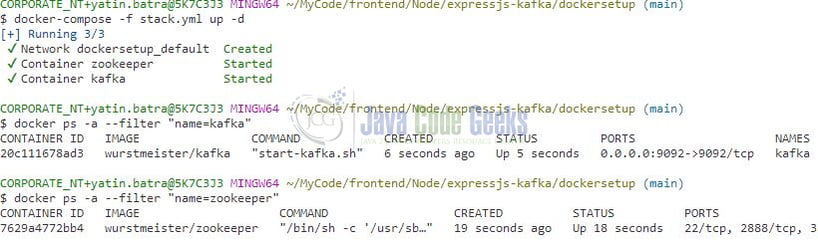
To stop and remove the containers, as well as the network created, use the following command:
Stop containers
docker-compose down
3.3 Creating a Topic
After the Kafka cluster is operational, establish the Kafka topic. Go to the directory containing the docker-compose.yml file and execute the following command. It will establish the jcg-topic topic utilizing a Kafka broker operating on port number 9092.
Kafka Topic
docker-compose exec kafka kafka-topics.sh --create --topic jcg-topic --partitions 1 --replication-factor 1 --bootstrap-server kafka:9092

3.4 Publishing and Consuming Messages
With the Kafka topic set up, let’s publish and consume messages. Start by initiating the Kafka consumer –
Kafka Consumer
docker-compose exec kafka kafka-console-consumer.sh --topic jcg-topic --from-beginning --bootstrap-server kafka:9092
The command allows the Kafka consumer to process messages from the jcg-topic topic. Using the --beginning flag ensures the consumption of all messages from the topic’s start.

Initiate the Kafka producer using this command to generate and dispatch messages to the jcg-topic topic.
Kafka Producer
docker-compose exec kafka kafka-console-producer.sh --topic jcg-topic --broker-list kafka:9092

4. Conclusion
In conclusion, mastering the art of creating Kafka topics using Docker Compose is a fundamental skill for modern data engineers and developers. The provided docker-compose.yml explains a streamlined approach to setting up a Kafka cluster with Zookeeper, showcasing the simplicity and power of containerized deployments. By encapsulating Kafka services within Docker containers, developers can ensure consistency across different environments, making development, testing, and deployment more predictable and reliable. This method not only simplifies the setup process but also allows for easy scaling and replication of Kafka topics in real-world applications.

It looks like the docker images from wurstmeister (https://hub.docker.com/u/wurstmeister) are no longer available, breaking this tutorial.
hi. I am not sure where you are checking but it is present. I can download it from the docker hub.