In this tutorial, we will look into the administration responsibilities and how to administer the Hadoop Cluster.
1. Introduction
Apache Hadoop Administration includes Hadoop Distributed File System(HDFS) administration as well as MapReduce administration. We will look into both the aspects. MapReduce administration means the admin need to monitor the running applications and tasks, application status, node configurations for running MapReduce tasks etc. while HDFS administration includes monitoring the distributed file structure and availability of the files in HDFS.
2. Hadoop Cluster Monitoring
A MapReduce application running in the cluster is the set of multiple jobs running in parallel or series, these jobs might include Mapper Jobs, Reducer Jobs, Combiner Jobs etc and need a continuous monitoring in order to see if everything is working fine or need more resources or configuration changes etc. Following are some of the tasks which need to be administered:
- Monitoring if namenodes and datanodes are working fine
- Configure the nodes whenever required
- Check if the availability of datanodes and namenodes are sufficient for the applications running or do they need any fine-tuning.
2.1 Overview & Summary of the cluster
Cluster monitoring in the UI interface starts with the overview of the cluster or the single-node hadoop installation running. In this example, I am using the Cloudera Hadoop Distribution Quickstart VM image. And the home page of the running hadoop interface shows the overview with the cluster id, the time it was started, cluster id and other relevant information.
Once we have the Hadoop Framework started either on the cluster of single node, we can access http://localhost:50070 and will see the Hadoop Cluster interface.
Note: Default port for the Hadoop cluster is 500070 but in case you change it in the configuration, you would need to access the localhost on that particular port to see the interface.
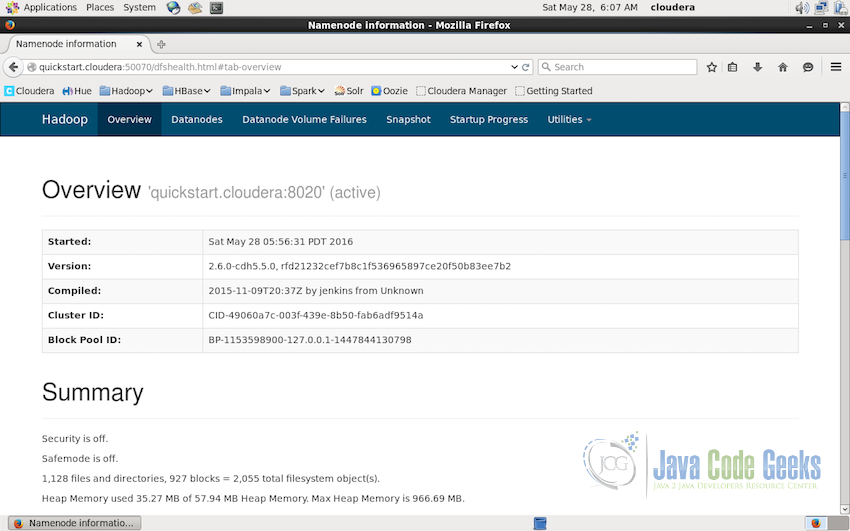
This overview is followed by the summary of the cluster state. In this screenshot below we can see that summary tells the admins the following information:
- The Security if Off, that means that the Hadoop is not running in the secure mode. To learn more about the secure mode, have a look at the office Apache Hadoop Documentation about Secure Mode
- Safe mode is also off. Safe mode if the mode in which the name node is under maintenance and does not allow any changes to the file system. If namenode is in safe-mode it is only read only.
- Then it lists the total number of files, directories and block
- Heap Memory and Non-Heap memory is followed in the summary listing.
- The listing in the summary is followed by the table having the following details:
- Total capacity of the cluster.
- DFS(Distributed File System) and Non-DFS used already. Followed by the percentage of usage and remaining
- Block pool used and percentage of block pool used
- Percentage amount used by the datanode
- Followed by number of live nodes and decommissioned nodes
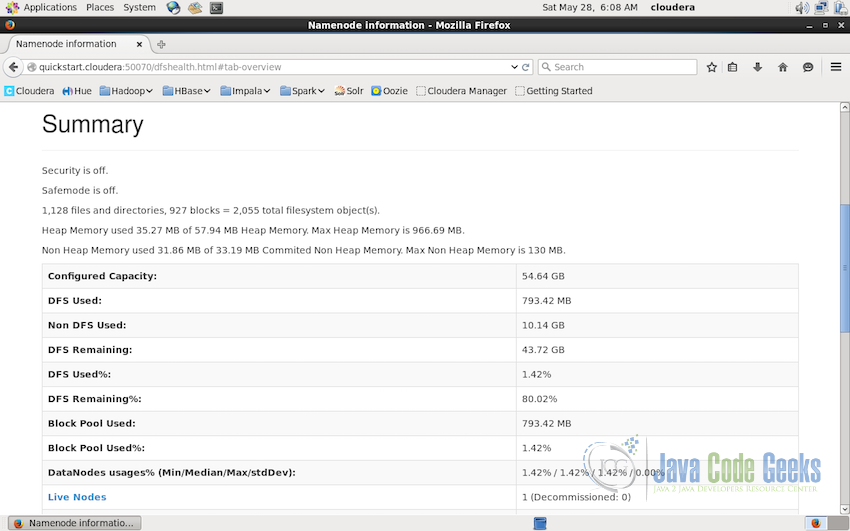
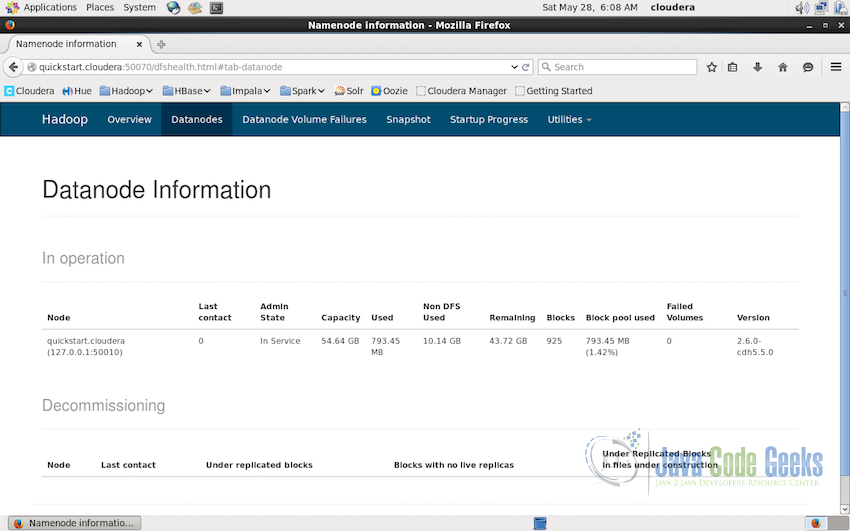
2.2 Datanode Information
Admins can also get the detailed information about datanodes from the interface itself. Datanode information interface provides the details about the nodes which are ‘in operation’ as well as ‘decommissioned’.
As we can see in the screenshot below, there is only one datanode available(as this is a single-node installation). The ip-address of the datanode, its state(‘in service’ in the screenshot), data capacity and other stats along with the version of the Apache Hadoop installation are displayed. In case of multi-node cluster installation, this will show the details of all the datanodes and will also display and nodes which are decommisioned in case if there are any.
3. HDFS Monitoring
Hadoop Distributed File Systems(HDFS) contains the data which is used by the MapReduce application. It is the filesystem which stores all the user directories, files and also the results of the applications. HDFS is the place from where the MapReduce application takes the data for processing. We have discussed in another examples how this data is transfered to the cluster in the HDFS, you can refer to the following articles for detail:
Coming back to the administration portion of HDFS.
3.1 HDFS Browser
We can browse the whole distributed file system from the Admin Interface itself. HDFS can be accessed and more advanced actions can be performed from the command line also, details of which are in the articles mentioned above.
To access the HDFS browser, click on the “Utilities->Browse the file system”. It will display the browser similar to the screenshot below:
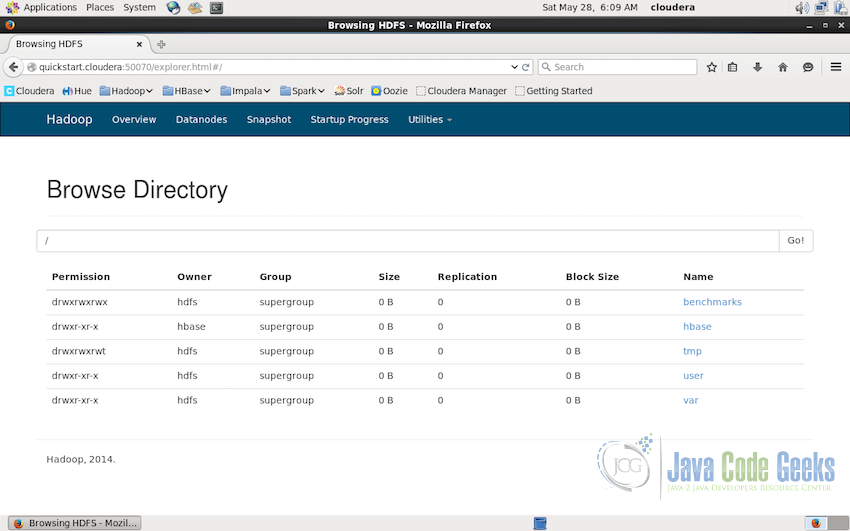
File system browser displays all the directories in the HDFS along with the details like owner, permissions, size and replication etc.
File system can be explored further by clicking on the directory names or passing the path in the textbox and clicking GO. In the screenshot below, we are in the subdirectory cloudera on the path /user/cloudera. Note that the replication of the file index.txt is 1 which is set in the setting and replication of the output is shown as zero because it if the directory, replication counts are only shown for the files which are in actuality replicated. In the production environments, it is recommended that the replication should be set to 3.

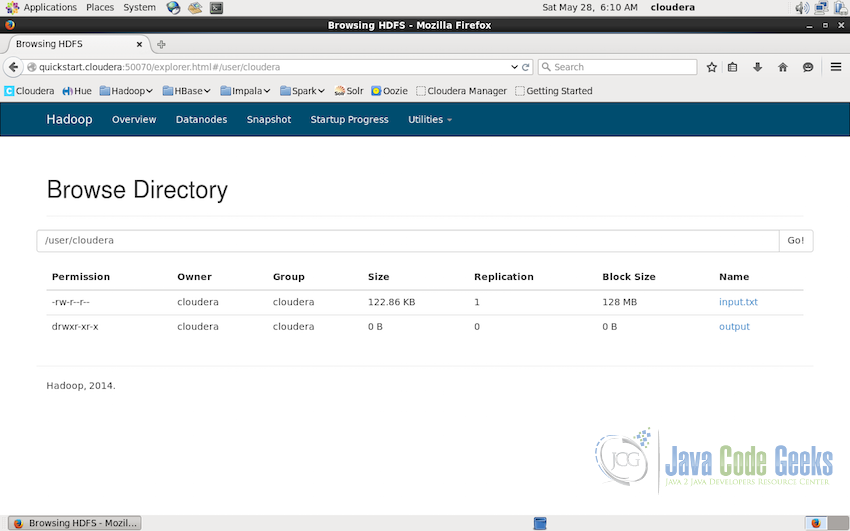
3.2 File Details & Download in HDFS
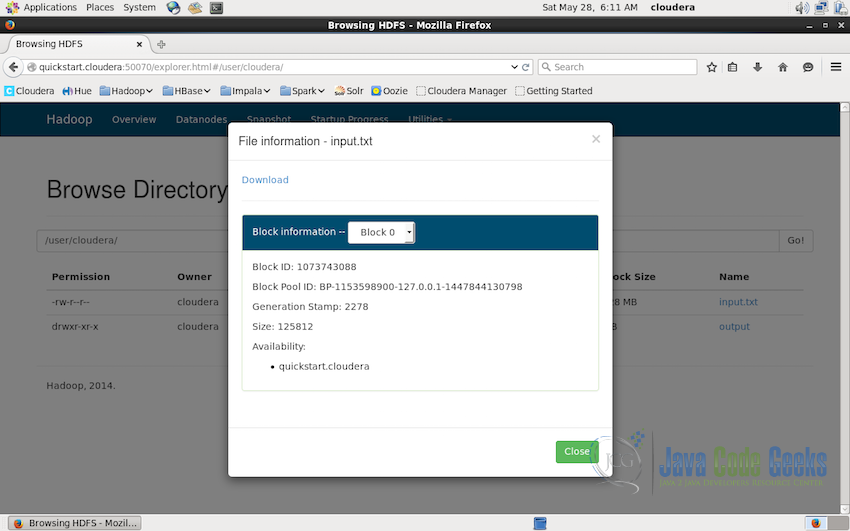
File can be downloaded to local system using the interface. Downloading the file is as simple as accessing the file using the path and clicking on the name of the file. In the screenshot, we want to download the file input.txt to look at the data input file. We access the file by going to the path /user/cloudera and click on the file system. It shows the details of the file including the block id which contains this file, block pool id, size of the file etc. At the top there is a download link, click on which will download the file in the local-system.
3.3 Checking cluster logs
Logs can tell a lot about the state of the system and are quite helpful in solving the issues faced in the working of the system. In Hadoop cluster, it is quite straightforward to access the logs. The option is provided under the Utilities in the interface.
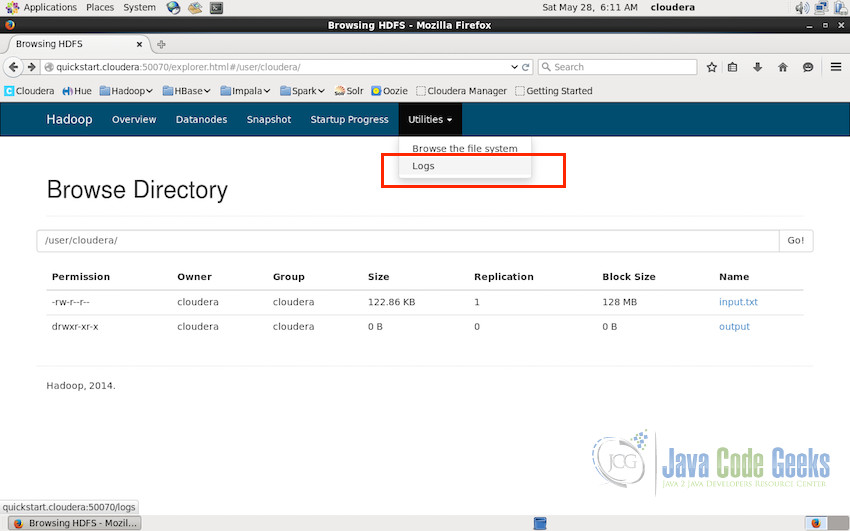
Clicking on Utilities->Logs will take us to the interface similar to the one shown in the screenshot below.
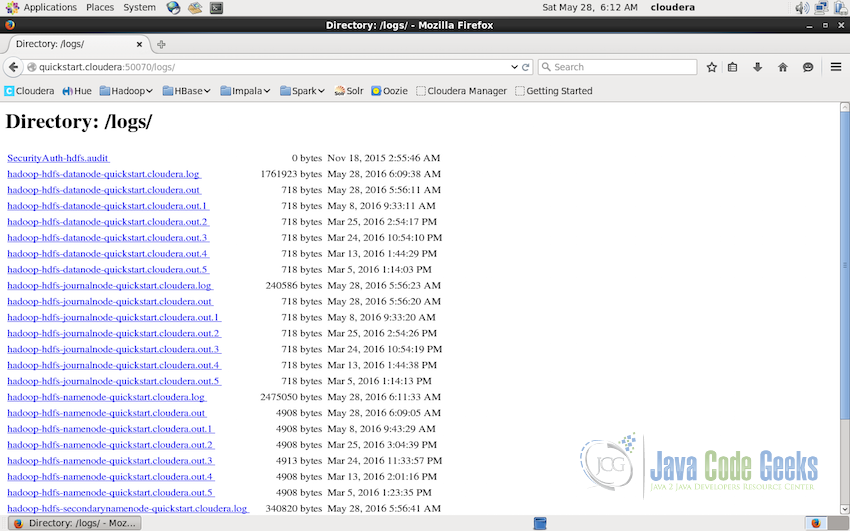
The interface lists all the logs of the Hadoop Cluster with the link to access the log, the size of the log file and the date when the log was created. These logs can come handy while troubleshooting the issues in the cluster.
4. MapReduce Application Monitoring
Monitoring the running application and the relative stats is also the part of the Apache Hadoop Administration. Similar to the Hadoop Cluster monitoring interface there is also an interface provided for monitoring the running applications. The application monitoring interface is available at the port 8088 in quickstart VM. This can also be configured in the setting to map to any other port.
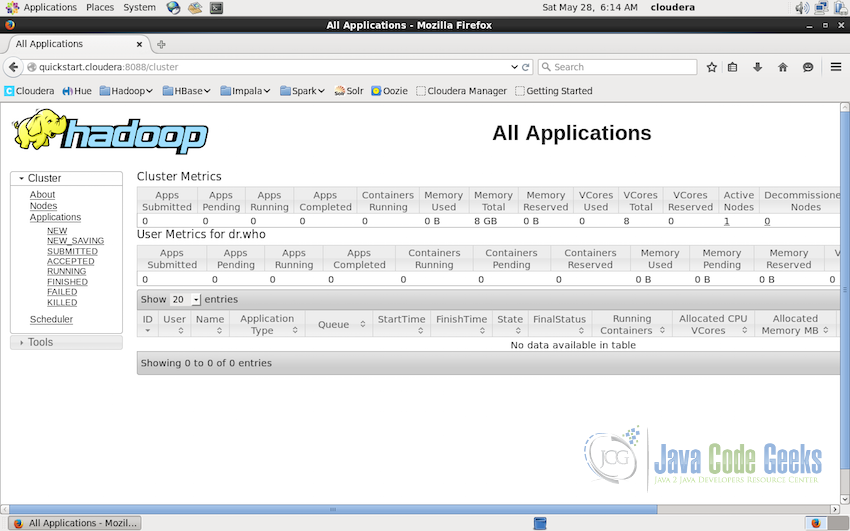
In the above screenshot, you can see 3 tables, the cluster matrics, the User matrics for ‘dr.who’ (dr.who is the default user in this VM) and the third table which should contain all the running application. We do not have any application running at the moment but we can see all the columns in the table.
- The ID of the running application.
- User on which the current application is running.
- The name of the application.
- Application type. For example, MAPREDUCE application etc.
- Queue if aynthing is in queue.
- Start and the Finish time of the application.
- Current state of the application i.e. STARTING, RUNNING, FINISHED etc.
- Final status of the application i.e. SUCCEEDED or FAILED etc.
- Containers allocated to this application.
- Allocated Virtual Cores of the CPU to this application.
- Allocated memory to this application in MegaBytes.
This gives the overall view of the running applications to the administrator.
5. Conclusion
In this tutorial, we learned about the administrator interface of the Hadoop Cluster and the Application Interface of the Cluster. What kind of information Administrators can gather from the interface related to the Cluster Nodes, Hadoop Distributed File System(HDFS) and the running applications. This is the basic introduction to the tasks of the administrators for Apache Hadoop but these interfaces gives an overall information regarding the complete cluster setup.
