Apache Kafka provides a reliable, scalable, and fault-tolerant messaging system that enables the exchange of data streams between multiple applications and microservices. Let us delve into understanding Apache Kafka and its basics.
1. Introduction
- Apache Kafka is a distributed streaming platform.
- It is designed to handle real-time, high-throughput data feeds.
- Kafka provides a publish-subscribe model for data streams.
- It offers fault-tolerant storage and replication of data.
- Kafka is horizontally scalable and allows for distributed processing.
- It is widely used for building real-time data pipelines and streaming applications.
- Kafka integrates well with other Apache frameworks and popular data processing tools.
1.1 Kafka Capabilities
Kafka is a distributed streaming platform that is widely used for building real-time data pipelines and streaming applications. It is designed to handle high-throughput, fault-tolerant, and scalable data streams.
1.1.1 Scalability
Kafka is horizontally scalable, allowing you to handle large volumes of data and high-traffic loads. It achieves scalability by distributing data across multiple nodes in a cluster, enabling you to add more nodes as your needs grow.
1.1.2 Durability
Kafka provides persistent storage for streams of records. Messages sent to Kafka topics are durably stored on disk and replicated across multiple servers to ensure fault tolerance. This ensures that data is not lost even in the event of node failures.
1.1.3 Reliability
Kafka guarantees message delivery with at least one semantics. This means that once a message is published on a topic, it will be delivered to the consumers at least once, even in the presence of failures or network issues.
1.1.4 Real-time streaming
Kafka enables real-time processing of streaming data. Producers can publish messages to Kafka topics in real-time, and consumers can subscribe to these topics and process the messages as they arrive, allowing for low-latency data processing.
1.1.5 High throughput
Kafka is capable of handling very high message throughput. It can handle millions of messages per second, making it suitable for use cases that require processing large volumes of data in real time.
1.1.6 Data integration
Kafka acts as a central hub for integrating various data sources and systems. It provides connectors and APIs that allow you to easily ingest data from different sources, such as databases, messaging systems, log files, and more, into Kafka topics.
1.1.7 Streaming data processing
Kafka integrates well with popular stream processing frameworks like Apache Spark, Apache Flink, and Apache Samza. These frameworks can consume data from Kafka topics, perform advanced processing operations (such as filtering, aggregating, and transforming), and produce derived streams of data.
1.1.8 Message Retention
Kafka allows you to configure the retention period for messages in topics. This means that messages can be retained for a specified period, even after they have been consumed by consumers. This enables the replayability of data and supports use cases where historical data needs to be accessed.
1.1.9 Exactly-once processing
Kafka provides exact-once processing semantics when used with supporting stream processing frameworks. This ensures that data processing is performed exactly once, even in the face of failures and retries, while maintaining data integrity.
1.1.10 Security
Kafka supports authentication and authorization mechanisms to secure the cluster. It provides SSL/TLS encryption for secure communication between clients and brokers and supports integration with external authentication systems like LDAP or Kerberos.
These are some of the key capabilities of Kafka, which make it a powerful tool for building scalable, fault-tolerant, and real-time data processing systems.
1.2 Error Handling and Recovery in Apache Kafka
Error handling and recovery in Apache Kafka are crucial aspects of building robust and reliable data processing pipelines. Kafka provides several mechanisms for handling errors and recovering from failures. Here are some key components and techniques for error handling and recovery in Kafka:
1.2.1 Retries and Backoff
Kafka clients can be configured to automatically retry failed operations, such as producing or consuming messages. Retries can help recover from transient failures, network issues, or temporary unavailability of resources. Backoff strategies can be employed to introduce delays between retries, allowing the system to stabilize before attempting again.
1.2.2 Error Codes
Kafka provides error codes to indicate specific types of failures. Error codes can be used by clients to identify the nature of the error and take appropriate action. For example, a client can handle a “leader not available” error differently than a “message too large” error.
1.2.3 Dead Letter Queues (DLQ)
DLQs are special Kafka topics where problematic messages are redirected when they cannot be processed successfully. By sending failed messages to a DLQ, they can be stored separately for later inspection and analysis. DLQs allow the decoupling of error handling from the main processing logic, enabling manual or automated recovery processes.
1.2.4 Monitoring and Alerting
Setting up monitoring and alerting systems for Kafka clusters and client applications is crucial for proactive error handling. Monitoring can provide insights into the health and performance of Kafka components, enabling early detection of issues. Alerts can notify administrators or operators about critical failures, high error rates, or other abnormal conditions, allowing them to take corrective actions promptly.
1.2.5 Transactional Support
Kafka supports transactions, which provide atomicity and isolation guarantees for producing and consuming messages. Transactions allow multiple operations to be grouped as a single unit of work, ensuring that either all operations succeed or none of them take effect. In case of failures, transactions can be rolled back to maintain data consistency.
1.2.6 Idempotent Producers
Kafka producers can be configured as idempotent, ensuring that duplicate messages are not introduced even if retries occur. Idempotent producers use message deduplication and sequence numbers to guarantee that messages are either successfully delivered once or not at all, preventing duplicate processing.
1.2.7 Monitoring and Recovery Tools
Various third-party tools and frameworks exist for monitoring and managing Kafka clusters, such as Confluent Control Center and Apache Kafka Manager. These tools provide visual dashboards, alerting capabilities, and automated recovery features, making it easier to detect and resolve errors.
It is important to design error handling and recovery mechanisms specific to your use case, considering factors like fault tolerance requirements, processing semantics, and data consistency. Proper monitoring, observability, and proactive error management practices are crucial for building robust and reliable Kafka-based systems.
1.3 Advantages and Disadvantages of Apache Kafka
| Advantages | Disadvantages |
|---|---|
| High-throughput and low-latency data processing. | Initial setup and configuration complexity. |
| Scalable and fault-tolerant architecture. | The steeper learning curve for beginners. |
| Efficient handling of real-time data streams. | Requires additional infrastructure resources. |
| Reliable data storage and replication. | No built-in security features. |
| Seamless integration with various data processing tools. | Limited built-in monitoring and management capabilities. |
1.4 Use Cases
Apache Kafka is used in various use cases across industries:
- Real-time analytics and monitoring
- Log aggregation and stream processing
- Event sourcing and CQRS (Command Query Responsibility Segregation)
- IoT (Internet of Things) data ingestion and processing
- Transaction processing and microservices communication
1.5 Additional Components
Aside from the core components, the Kafka ecosystem includes various tools and libraries:
- Kafka Connect: Kafka Connect is a framework for building and running connectors that move data between Kafka and other systems.
- Kafka Streams: Kafka Streams is a library for building real-time streaming applications using Kafka as the underlying data source.
- Kafka MirrorMaker: A tool for replicating Kafka topics between clusters, often used for disaster recovery or data migration.
- Kafka Admin Client: A Java API for managing and inspecting Kafka clusters, topics, and partitions programmatically.
- Kafka Manager: A web-based tool for monitoring and managing Kafka clusters, topics, and consumer groups.
- Kafka Streams API: A high-level library for building stream processing applications directly within Kafka, leveraging the Kafka Streams library.
- Kafka Security: Kafka supports various security features such as SSL/TLS encryption, SASL authentication, and ACLs (Access Control Lists) for authorization.
- Confluent Platform: Confluent, the company founded by the creators of Kafka, offers a platform that extends Kafka with additional features and enterprise-grade support.
- Kafka REST Proxy: Kafka REST Proxy allows clients to interact with Kafka using HTTP-based RESTful APIs.
- Schema Registry: Schema Registry manages schemas for data stored in Kafka, ensuring compatibility and consistency across producers and consumers.
- Control Center: A web-based monitoring and management tool for Kafka clusters, providing insights into cluster health, performance, and usage.
- ksqlDB: A streaming SQL engine for Kafka, allowing users to query, transform, and analyze data streams using SQL syntax.
2. Setting up Apache Kafka on Docker
Docker is an open-source platform that enables containerization, allowing you to package applications and their dependencies into standardized units called containers. These containers are lightweight, isolated, and portable, providing consistent environments for running applications across different systems. Docker simplifies software deployment by eliminating compatibility issues and dependency conflicts. It promotes scalability, efficient resource utilization, and faster application development and deployment. With Docker, you can easily build, share, and deploy applications in a consistent and reproducible manner, making it a popular choice for modern software development and deployment workflows. If someone needs to go through the Docker installation, please watch this video.
Using Docker Compose simplifies the process by defining the services, their dependencies, and network configuration in a single file. It allows for easier management and scalability of the environment. Make sure you have Docker and Docker Compose installed on your system before proceeding with these steps. To set up Apache Kafka on Docker using Docker Compose, follow these steps.
2.1 Creating a Docker Compose file
Create a file called docker-compose.yml and open it for editing.
- Zookeeper Service: The
zookeeperservice is defined to run Zookeeper, which is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. The configuration for this service is as follows:- Image: The service uses the latest version of Confluent’s Zookeeper image (
wurstmeister/zookeeper). - Container Name: The name of the container is set to
zookeeper. - Ports: Zookeeper uses port
2181for client connections, which are mapped from the host to the container.
- Image: The service uses the latest version of Confluent’s Zookeeper image (
- Kafka Service: The
kafkaservice is defined to run Apache Kafka, a distributed streaming platform. Here’s how the Kafka service is configured:- Image: The service uses the latest version of Confluent’s Kafka image (
wurstmeister/kafka). - Container Name: The name of the container is set to
kafka. - Ports: Kafka uses port
9092for client connections, which are mapped from the host to the container. - Environment Variables: Several environment variables are set to configure Kafka. Notably,
KAFKA_ZOOKEEPER_CONNECTspecifies the Zookeeper connection string,KAFKA_ADVERTISED_LISTENERSdefines the listener for client connections, andKAFKA_CREATE_TOPICScreates a topic namedmy-topicwith 1 partition and a replication factor of 1. - Depends On: The Kafka service depends on the
zookeeperservice, ensuring Zookeeper is running before Kafka starts.
- Image: The service uses the latest version of Confluent’s Kafka image (
Add the following content to the file and save it once done.
docker-compose.yml
version: '3'
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_LISTENERS: INSIDE://kafka:9092,OUTSIDE://localhost:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_LISTENERS: INSIDE://0.0.0.0:9092,OUTSIDE://0.0.0.0:9093
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_CREATE_TOPICS: "my-topic:1:1"
depends_on:
- zookeeper
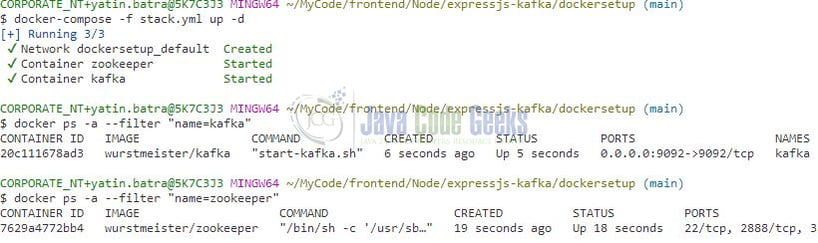
2.2 Running the Kafka containers
Open a terminal or command prompt in the same directory as the docker-compose.yml file. Start the Kafka containers by running the following command:
Start containers
docker-compose up -d
This command will start the ZooKeeper and Kafka containers in detached mode, running in the background.
To stop and remove the containers, as well as the network created, use the following command:
Stop containers
docker-compose down
2.3 Creating a Topic
After the Kafka cluster is operational, establish the Kafka topic. Go to the directory containing the docker-compose.yml file and execute the following command. It will establish the jcg-topic topic utilizing a Kafka broker operating on port number 9092.
Kafka Topic
docker-compose exec kafka kafka-topics.sh --create --topic jcg-topic --partitions 1 --replication-factor 1 --bootstrap-server kafka:9092

2.4 Publishing and Consuming Messages
With the Kafka topic set up, let’s publish and consume messages. Start by initiating the Kafka consumer –
Kafka Consumer
docker-compose exec kafka kafka-console-consumer.sh --topic jcg-topic --from-beginning --bootstrap-server kafka:9092
The command allows the Kafka consumer to process messages from the jcg-topic topic. Using the --beginning flag ensures the consumption of all messages from the topic’s start.

Initiate the Kafka producer using this command to generate and dispatch messages to the jcg-topic topic.
Kafka Producer
docker-compose exec kafka kafka-console-producer.sh --topic jcg-topic --broker-list kafka:9092

3. Apache Kafka Ecosystem & Working
At the core of Apache Kafka are several key concepts:
- Topics: Topics are logical categories or feeds to which messages are published by producers and from which consumers consume messages. They represent a particular stream of data. Each message published to Kafka is associated with a topic. Topics are identified by their unique names and can be thought of as similar to a table in a database or a folder in a filesystem.
- Partitions: Each topic in Kafka is divided into one or more partitions. Partitions allow for parallelism and scalability within Kafka. Messages within a partition are ordered, meaning that Kafka guarantees the order of messages within a partition. Partitions are the unit of parallelism in Kafka; they enable Kafka to scale out by allowing multiple consumers to read from a topic concurrently. Each partition is an ordered, immutable sequence of messages that is continually appended.
- Partitions also enable Kafka to distribute the data across multiple brokers in a cluster. Each partition can be stored on a separate broker, providing fault tolerance and allowing Kafka to handle large volumes of data by distributing the data processing load across multiple servers.
- By having multiple partitions for a topic, Kafka ensures that producers and consumers can achieve high throughput and scalability. Additionally, partitions enable Kafka to provide fault tolerance and durability by replicating partition data across multiple brokers.
- Brokers: Kafka runs as a cluster of servers called brokers. Brokers are responsible for handling data storage, replication, and serving consumer requests.
- Producers: Producers publish messages to Kafka topics. They can choose which topic to publish to and may partition messages based on certain criteria.
- Consumers: Consumers read messages from Kafka topics. They can subscribe to one or more topics and consume messages in real time.
- ZooKeeper: Kafka uses Apache ZooKeeper for distributed coordination, leader election, and storing metadata about brokers, topics, and partitions.
3.1 Message Lifecycle
When a message is produced to Kafka, it goes through several stages in its lifecycle:
- Producer Publishes Message: The producer sends the message to a Kafka broker, specifying the topic and optionally the partition.
- Message Storage: The broker appends the message to the end of the partition’s log file. Each partition maintains its offset to track the position of the latest message.
- Consumer Reads Message: Consumers subscribe to topics and read messages from partitions. They maintain their offset, indicating the last message they have consumed.
- Message Retention: Kafka retains messages for a configurable period or until a certain size threshold is reached. Once messages expire or are no longer needed, they are deleted.
- Replication: Kafka replicates data across multiple brokers to ensure fault tolerance and durability. Each partition has one leader and one or more followers.
3.2 Cluster and Partition Replicas
In Apache Kafka, clusters and partition replicas are crucial components that contribute to the reliability, fault tolerance, and scalability of the system.
3.2.1 Clusters
A Kafka cluster is a group of one or more Kafka brokers (servers) that work together to serve the Kafka topics and handle the associated data. The cluster typically consists of multiple brokers distributed across different machines or servers. Each broker in the cluster is identified by a unique numeric ID.
The Kafka cluster architecture allows for horizontal scalability, meaning that additional brokers can be added to the cluster to handle increased data load and processing requirements. It also provides fault tolerance by replicating data across multiple brokers within the cluster.
3.2.2 Partition Replicas
Partitions in Kafka are replicated across multiple brokers in the cluster to ensure fault tolerance and high availability. Each partition has one leader replica and zero or more follower replicas.
- Leader Replica: Each partition has one broker designated as the leader replica. The leader replica is responsible for handling all read and write requests for the partition. When a producer publishes a message to a partition, it is written to the leader replica first.
- Follower Replicas: Follower replicas are exact copies of the leader replica for a partition. They replicate the data stored in the leader replica and stay in sync with it. Follower replicas serve as backups in case the leader replica fails. If the leader replica becomes unavailable, one of the follower replicas is automatically elected as the new leader to continue serving read and write requests.
3.2.2.1 Importance of Partition Replicas
Partition replicas play a crucial role in ensuring the durability and fault tolerance of Kafka. By replicating data across multiple brokers, Kafka can continue to operate smoothly even if some brokers or individual nodes fail. If a broker hosting a leader replica fails, one of the follower replicas can take over as the new leader, ensuring continuous availability of data.
Partition replicas also enable Kafka to handle increased read throughput by allowing multiple brokers to serve read requests for a partition concurrently. This distribution of read requests across replicas enhances the overall performance and scalability of Kafka clusters.
3.3 Scalability and Performance
Kafka is designed for horizontal scalability and high performance:
- Partitioning: By partitioning data and distributing it across brokers, Kafka can handle large volumes of data and support parallel processing.
- Replication: Replicating data across multiple brokers ensures fault tolerance and enables automatic failover.
- Zero Copy Transfer: Kafka uses efficient disk structures and zero-copy transfer mechanisms to achieve high throughput with low latency.
4. Best Practices for Apache Kafka
- Proper Topic Design: Design your Kafka topics carefully, considering factors such as message size, throughput requirements, and consumer behavior. Avoid creating too many topics, as it can lead to increased management overhead and decreased performance.
- Optimal Partitioning: Partition your Kafka topics effectively to distribute the data evenly across brokers and maximize parallelism. Consider the expected data volume and throughput when determining the number of partitions for each topic.
- Replication Factor: Set an appropriate replication factor for your Kafka topics to ensure data durability and fault tolerance. Typically, a replication factor of at least 3 is recommended to tolerate up to two broker failures without data loss.
- Monitoring and Alerting: Implement robust monitoring and alerting systems to track the health, performance, and usage of your Kafka clusters. Monitor key metrics such as broker throughput, consumer lag, and partition under-replication to identify and address issues proactively.
- Security: Ensure proper security measures are in place to protect your Kafka clusters from unauthorized access and data breaches. Enable SSL/TLS encryption, authentication mechanisms like SASL and authorization controls using ACLs to safeguard your data.
- Capacity Planning: Perform thorough capacity planning to size your Kafka clusters appropriately based on expected data volumes, throughput requirements, and retention policies. Consider factors such as disk storage, CPU, memory, and network bandwidth to ensure optimal performance and scalability.
- Version Upgrades: Plan and execute Kafka version upgrades carefully, following the recommended upgrade paths and testing procedures. Consult the Kafka release notes and documentation for any breaking changes, deprecated features, or new configurations introduced in the newer versions.
5. Conclusion
In conclusion, Apache Kafka stands as a distributed streaming platform designed to handle high-throughput, fault-tolerant, and scalable data streaming across multiple systems. Its core components, including topics, partitions, brokers, producers, and consumers, form the backbone of its functionality, facilitating seamless data flow.
The ecosystem surrounding Kafka enriches its capabilities further. Tools like Kafka Connect and Kafka Streams empower developers to integrate Kafka with other systems and build real-time streaming applications efficiently. Moreover, offerings such as Confluent Platform and Schema Registry enhance Kafka’s functionality, providing enterprise-grade support and ensuring data compatibility and consistency.
In today’s data-driven world, Apache Kafka has become indispensable, enabling organizations to construct resilient, scalable, and real-time data pipelines. Its versatility and robustness make it a cornerstone of modern data architectures, driving innovation and empowering businesses to unlock the full potential of their data.
