In this post, we feature a comprehensive Apache Spark Installation Guide.
1. Introduction
Apache Spark is an open-source cluster computing framework with in-memory data processing engine. It provides API in Java, Scala, R, and Python. Apache Spark works with HDFS and can be up to 100 times faster than Hadoop Map-Reduce.
It also supports other high-level tools like Spark-SQL for structured data processing, MLib for machine learning, GraphX for graph processing and Spark streaming for continuous data stream processing.
Below installation, steps are for macOS. Though steps and properties remain the same for other operating systems, commands may differ especially for Windows.
2. Apache Spark Installation
2.1 Prerequisites for Spark
2.1.1 Java Installation
Ensure Java is installed, before installing and running Spark. Run below command to verify the version of java installed.
$ java -version
If Java is installed, it will show the version of java installed.
java version "1.8.0_51" Java(TM) SE Runtime Environment (build 1.8.0_51-b16) Java HotSpot(TM) 64-Bit Server VM (build 25.51-b03, mixed mode)
If the above command is not recognized then install java from Oracle Website, depending upon the operating system.
2.1.2 Scala Installation
Installing Scala is mandatory before installing Spark as it is important for implementation. Check the version of scala, if installed already.
$scala -version
If installed, the above command will show the version installed.
Scala code runner version 2.13.1 -- Copyright 2002-2019, LAMP/EPFL and Lightbend, Inc.
If not installed then it can be installed either by installing IntelliJ and following steps as described here. It can also be installed by installing sbt or Scala Built Tool, following steps as described here
Scala can also be installed by downloading scala binaries.
On macOS, homebrew can also be used to install scala using below command,
brew install scala
2.1.3 Spark Installation
Download Apache Spark from the official spark site. Make sure to download the latest, stable build of spark.
Also, the central maven repository hosts number of spark artifacts and can be added as a dependency in the pom file.
PyPi can be used to install pySpark. Run command pip install pyspark to install.
For this example, I have downloaded Spark 2.4.0 and installed it manually.
In order to verify that spark has been set up properly, run below command from spark HOME_DIRECTORY/bin,
$ ./spark-shell
2019-12-31 13:00:35 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://192.168.10.110:4040
Spark context available as 'sc' (master = local[*], app id = local-1577777442575).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_51)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
3. Launching Spark Cluster
There are multiple options to deploy and run Spark. All these options differ in how drivers and workers are running in spark. Just to introduce the terms,
A Driver is the main process of spark. It converts the user programs to tasks and assigns those tasks to workers.
A Worker is the spark instance where executor resides and it executes the tasks assigned by driver.
We will discuss them in detail below.
- Client Mode
- Cluster Mode
3.1 Client Mode
In client mode, drivers and workers not only run on the same system but they use the same JVM as well. This is mainly useful while development, by when the clustered environment is not ready. Also, it makes the implementation and testing of the tasks faster.
Spark comes with a bundled-in resource manager, so while running in client mode, we can use the same to avoid running multiple processes.
Another way is to use YARN as the resource manager, which we will see in detail when speaking about the Cluster mode of Spark.
3.1.1 Standalone Mode
Standalone mode is a simple cluster manager bundled with Spark. It makes it easy to set up a self-managed Spark cluster.
Once the spark is downloaded and extracted, run below command from spark HOME_DIRECTORY/sbin to start the master,
$ ./start-master.sh starting org.apache.spark.deploy.master.Master, logging to /Users/aashuaggarwal1/Softwares/spark-2.4.0-bin-hadoop2.7/logs/spark-aashuaggarwal1-org.apache.spark.deploy.master.Master-1-Aashus-MacBook-Pro.local.out
The above command will start spark master at localhost:8080 where the spark portal can be accessed on the browser.

Only Master
Here you can see that still, no worker is running. So this is time to start a worker. If you see in the above image, the URL of the spark master is displayed. This is the URL we will use to map already running master with the slave. Run below command from spark HOME_DIRECTORY/sbin,
$ ./start-slave.sh spark://Aashus-MacBook-Pro.local:7077 starting org.apache.spark.deploy.worker.Worker, logging to /Users/aashuaggarwal1/Softwares/spark-2.4.0-bin-hadoop2.7/logs/spark-aashuaggarwal1-org.apache.spark.deploy.worker.Worker-1-Aashus-MacBook-Pro.local.out
Now if we visit localhost:8080, then we will see that 1 worker thread has started as well. Since we have not given the number of cores and memory explicitly, the worker has taken up all of the cores (8 in this case) and memory (15 GB) for the execution of tasks.
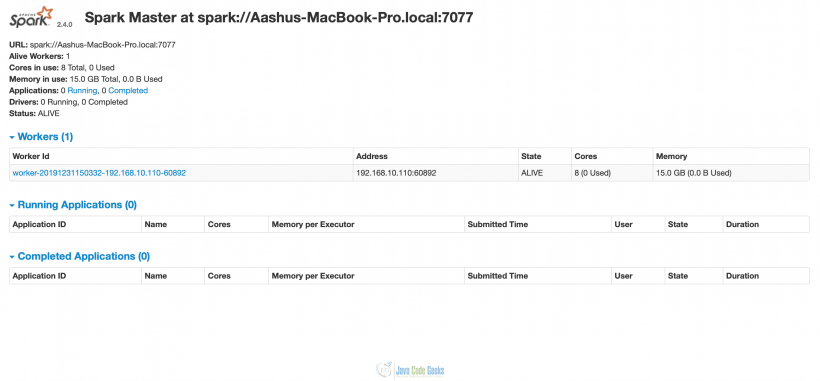
Master with one slave
3.2 Cluster Mode
Client mode helps in development, where changes can be made and tested quickly on a local desktop or laptop. But to harness the real power of Spark, it must be distributed.
Here is the typical infrastructure of a Spark in production.
While default resource negotiator bundled with Spark can be used in clustered mode too but YARN (Yet Another Resource Negotiator) is the most popular choice. Let’s see it in detail.
3.2.1 Hadoop YARN
YARN is a generic resource-management framework for distributed workloads. It is part of the Hadoop ecosystem but it supports multiple other distributed computing frameworks like Tez and Spark.
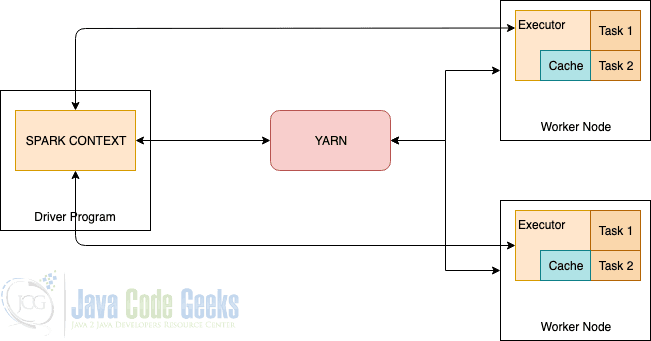
As we see in the above diagram, YARN, and worker nodes form the data computation framework.
YARN takes care of resource arbitration for all of the applications in the system while executor monitors the individual machine resource usage and sends this information back to the resource manager.
There are a couple of YARN configurations which we need to take care,
arn.nodemanager.resource.memory-mb
yarn.nodemanager.resource.memory-mb – It is the amount of physical memory, in MB, that can be allocated for containers in a node. This value must be lower than the memory available on the node.
yarn.scheduler.minimum-allocation-mb – This is the minimum memory that the resource manager needs to allocate for every new request for a container.
yarn.scheduler.maximum-allocation-mb – Maximum memory that can be allocated for a new container request.
Below are a couple of spark configurations from the viewpoint of running spark job within YARN.
spark.executor.memory – Since every executor runs as a YARN container, it is bound by the Boxed Memory Axiom. Executors will use memory allocation equal to the sum of spark.executor.memory + spark.executor.memoryOverhead
spark.driver.memory – In cluster deployment mode, since the driver runs in the ApplicationMaster which in turn is managed by YARN, this property decides the memory available to the ApplicationMaster. The memory allocated is equal to the sum of spark.driver.memory + spark.driver.memoryOverhead.
4. Summary
This article explains how to run Apache spark in client and cluster mode using standalone and YARN resource manager. There are othe resource managers like Apache Mesos and Kubernetes available, which can be explored as well.
