In this article, we will explain Web Scraping in Python.
1. Introduction
Web scraping is a way of extracting data from websites. While web scraping can be done manually by a software user, the term typically refers to automated processes implemented using a bot or web crawler. It is a form of copying in which specific data is gathered and copied from the web, typically into a central local database or spreadsheet, for later retrieval or analysis.
First, the web scraper will be given one or more URLs to load before scraping. The scraper then loads the entire HTML code for the page in question. More advanced scrapers will render the entire website, including CSS and Javascript elements. Then the scraper will either extract all the data on the page or specific data selected by the user before the project is run.
You can also check this tutorial in the following video:

2. Python Web Scraping Example
Let us first define a very basic HTML page which we will use for scraping. Below is the code of that HTML:
<html>
<head>
<title>Java Code Geeks</title>
</head>
<body>
<a href="https://www.javacodegeeks.com/">Link Name</a> is a link to another nifty site
<h1>Python web scraping tutorial</h1>
<h2>Tutorial to learn about web scaping using Python</h2>
Send me mail at <a href="mailto:mohammad.zia@javacodegeeks.com">mohammad.zia@javacodegeeks.com</a>.
<p> This is a new paragraph! </p>
<p>
This is a new paragraph!
<br> <b><i>This is a new sentence without a paragraph break, in bold italics.</i></b>
</p>
</body>
</html>
HTML is the standard markup language for Web pages. It stands for HyperText Markup Language. It is the standard markup language for creating Web pages. It consists of a series of elements that tell the browser how to display the content. The <html> element is the root element of an HTML page. The <head> element contains meta-information about the HTML page. The <title> element specifies a title for the HTML page (which is shown in the browser’s title bar or in the page’s tab). The <body> element defines the document’s body and is a container for all the visible contents, such as headings, paragraphs, images, hyperlinks, tables, lists, etc. The <h1>, <h2> elements define the headings. <p> is used for paragraphs, <br> to put a new line, <b> for bold and <i> for italics.
When you open the above HTML in a browser you will see something like the below:
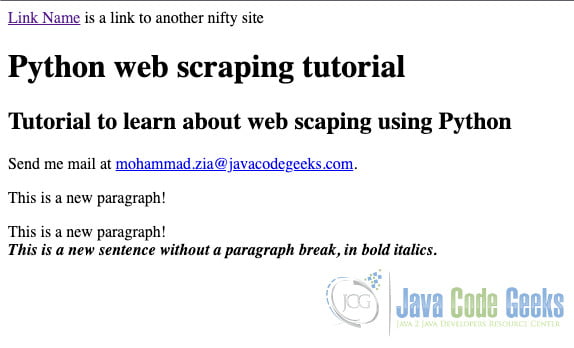
2.1 Install BeautifulSoup
For this example, we will make use of a library called BeautifulSoup for web scrapping. First, we need to install it. I am using Mac so I will use pip to install it. Run the below command to install beautifulsoup
pip3 install beautifulsoup4
Below is the output of the command:
~$ pip3 install beautifulsoup4
Collecting beautifulsoup4
Downloading beautifulsoup4-4.10.0-py3-none-any.whl (97 kB)
|████████████████████████████████| 97 kB 339 kB/s
Collecting soupsieve>1.2
Downloading soupsieve-2.3.1-py3-none-any.whl (37 kB)
Installing collected packages: soupsieve, beautifulsoup4
Successfully installed beautifulsoup4-4.10.0 soupsieve-2.3.1
Now the next thing that I would like to install is something that the BeautifulSoup uses to parse the HTML code. When you use the BeautifulSoup you need to tell the method you are going to use to parse the HTML. There are lots of methods which you can use – we will use lxml. The lxml parser handles the broken HTML code as well. To install the lxml run the below code:
~$ pip3 install lxml
Collecting lxml
Downloading lxml-4.7.1-cp38-cp38-macosx_10_14_x86_64.whl (4.5 MB)
|████████████████████████████████| 4.5 MB 979 kB/s
Installing collected packages: lxml
Successfully installed lxml-4.7.1
2.2 Python code
In this section, we will use the BeautifulSoup library (which we installed above) in our python code. To import the library use the below command:
from bs4 import BeautifulSoup
To scrape the HTML file which we created above we need to work with the file object. Use the below command to open the file in the read mode:
with open('example.html', 'r') as html_file:
The first argument of the open method is the file name. Since the HTML file which we created is in the same folder as our python file we don’t need to give the whole path. The second argument tells you in which mode you want o open your file. In our case, we just want to read the file. The html_file is the variable name that we will use to access the file object.
Now let us read the content of the HTML file:
html_content = html_file.read()
Now let us create an object of the BeautifulSoup which we will use for our scaping purpose:
soup = BeautifulSoup(html_content, 'lxml')
The first argument is the HTML content and the second argument is the parser method. You can use the prettify method to display the HTML in a pretty way:
print(soup.prettify)
2.3 Finding a tag
In this section, we will see how we can use the BeautifulSoup library to find particular information for the given HTML file. We will use the find method of the BeautifulSoup library for this purpose:
h2_tags = soup.find('h2')
The code above will return the code which is contained inside the <h2> tags. For our HTML it will return:
<h2>Tutorial to learn about web scaping using Python<h2>
The find method searches the element and stops searching once it has found the first one. If you want to find all the h2 tags then use the find_all method:
h2_tags = soup.find_all('p')
print(h2_tags)
Running the above code will print all the lines having h2 tags. If you want to print the text contained inside this tag you can iterate through the list and call the text attribute.
The above code was very simple because we were dealing with a very simple example of a web page. In real life, the web page is going to be a lot more complex. So in order to handle the HTML code of a complex website we need to use the inspect of the browser.
3. Challenges
In this section, we will see the most common challenges you will face when you try to scrape a website.
3.1 Captha
CAPTCHA(Completely Automated Public Turing test to tell Computers and Humans Apart) is often used to separate humans from scraping tools by displaying images or logical problems that humans find easy to solve but scrapers don’t. A lot of websites now use Captcha so it becomes very difficult for a bot to access them. You can implement captcha solvers into the bot but it’s not that easy and it also makes the scraping slow.
3.2 Slow network
Sometimes websites can be very slow to respond. As a user, you can wait and reload the website but as a scaping bot, it’s very difficult to handle this situation. You will need to implement an auto-retry and reloading logic in your bot to handle this situation.
3.3 Authentication
Some website requires you to log in before you can access anything. After you submit your login credentials, your browser automatically appends the cookie value to multiple requests you make the way most sites, so the website knows you’re the same person who just logged in earlier. For these kinds of websites, you will need to send the cookies for every request you make.
3.4 Access
The first thing to check is to find out whether the website you are trying to scrape allows it. If you find out that it doesn’t you can ask the owner to give you the access.
3.5 IP blocking
IP blocking is a common method to stop web scrapers from accessing the data of a website. It typically happens when a website detects a high number of requests from the same IP address. The website would either totally ban the IP or restrict its access to break down the scraping process.
3.6 Honeypot traps
Honeypot is a trap the website owner puts on the page to catch scrapers. The traps can be links that are invisible to humans but visible to scrapers. Once a scraper falls into the trap, the website can use the information it receives(e.g. its IP address) to block that scraper.
3.7 Dynamic content
Many websites apply AJAX to update dynamic web content. Examples are lazy loading images, infinite scrolling, and showing more info by clicking a button via AJAX calls. It is convenient for users to view more data on such kinds of websites but not for scrapers.
4. Web scraping APIs
Instead of writing your own web scraper, you can use APIs which are specifically designed to tackle the challenges of web-scraping which we discussed above. There are many options available and in this section, we will look at some of the most commonly used ones.
4.1 WebScrapingAPI
WebScrapingAPI is a tool that allows you to scrape any online source without getting blocked. It collects the HTML from any web page using a simple API. It provides ready-to-process data whether you want to use it to extract price and product information, gather and analyze real estate, HR, and financial data, or monitor valuable information for any specific market.
4.2 Scraper API
ScraperAPI is a tool for developers building web scrapers — as they say — the tool that scrapes any page with a simple API call. The web service handles proxies, browsers, and CAPTCHAs so that developers can get the raw HTML from any website.
4.3 ScrapingBee
ScrapingBee offers the opportunity to web scrape without getting blocked, using both classic and premium proxies. It focuses on extracting any data you need rendering web pages inside a real browser (Chrome). Thanks to their large proxy pool, developers and companies can handle the scraping technique without taking care of proxies and headless browsers.
4. Summary
In this article, we learned what web scraping is and what it is used for. We looked at a very simple example of using the BeautifulSoup library to scrape web pages in Python. We also looked at some of the most common challenges which we could face if we want to build a web-scraping tool. In the end, we looked at some of the most commonly used web scraping APIs.
