1. What is Pandas in Python?
Pandas is an open-source library in Python, created data analysis in Python. Wes McKinney created the first version in 2008. It is built on top of the Numpy library, and it provides several utilities to clean, analyze and manipulate datasets in Python.
You can also check this tutorial in the following video:

2. How to Install it?
The pre-requisites for installing Pandas is that we need to have Python and Pip installed on your system. The source code for Pandas is available in a GitHub repository.
To install Pandas on our system, we use the command:
pip install pandas
After we have installed Pandas, we need to import Pandas to use it. To import
import pandas
3. What can we do with a Pandas Dataframe
Pandas DataFrame is a mutable, two-dimensional structure that can hold various types of data. A DataFrame is a table-like structure with rows and columns. DataFrames are an integral part of the Numpy and Pandas ecosystem since they are lightweight and faster to use than Spreadsheets or tables. Using DataFrames we can:
- We can modify the row and column labels as sequences.
- Analyze the size of the data frame objects and converts them to other forms.
- We can convert other data types to data frames.
4. Working with DataFrames
Here we will see how to create a DataFrame using Pandas. We can create Pandas DataFrame using Dictionaries, Lists, NumPy arrays, CSVs, and many other options. First, we look at a few examples of creating and importing CSV as a Pandas Dataframe.
4.1 Creating a Pandas dataframe from a Dictionary
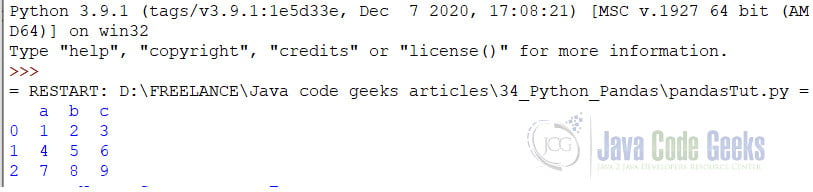
To create a dataframe from a Dictionary we use the DataFrame method where we pass the dictionary. For example:
someDict = [{'a': 1, 'b': 2, 'c': 3},
{'a': 4, 'b': 5, 'c': 6},
{'a': 7, 'b': 8, 'c': 9}]
dfDict = pd.DataFrame(someDict)
4.2 Creating Pandas dataframe from a List
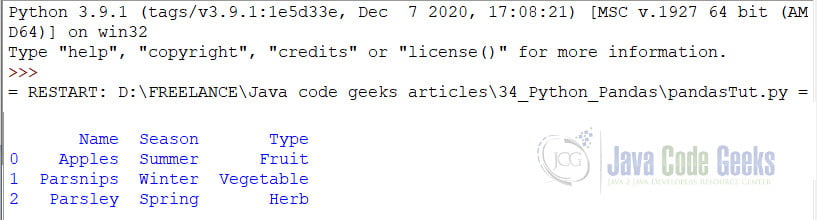
Similar to a Dictionary, we can also create a DataFrame using a Nested List. We do so as follows:
someList = [['Apples','Summer','Fruit'],
['Parsnips','Winter','Vegetable'],
['Parsley','Spring','Herb']]
dfList = pd.DataFrame(someList,columns=['Name','Season','Type'])
4.3 Creating Pandas dataframe by reading CSV
For analysis, we generally require large datasets, and they need to be in the dataFrame format for easy manipulation. To create a DataFrame from a CSV, we use the read_csv method. For example, if we have a CSV file of plant traits, we can create a dataFrame using the CSV as follows:
dfCSV = pd.read_csv("D:/Datasets/plantTraits.csv") Optionally we can also give the name of the column to be indexed as
dfCSV = pd.read_csv("D:/Datasets/plantTraits.csv",index_col =”Name”)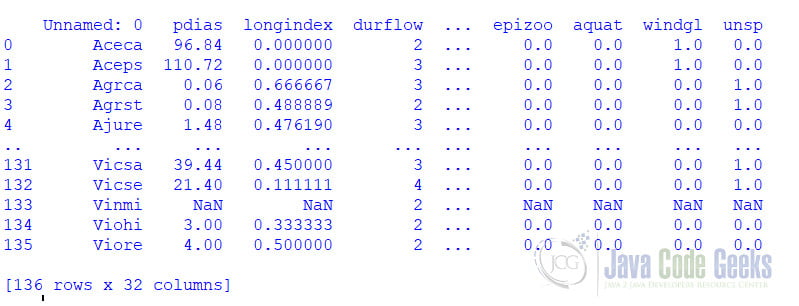
5. Indexing DataFrames
Indexing or Subset Selection means selecting a subset of specific rows and columns from a DataFrame. There are multiple ways in which we can index a Pandas DataFrame. We will look at each one by one
5.1 Indexing using .loc[]
If we have indexed the dataframe using a non-numerical index column, we can use the .loc[] method. The Basic syntax of the .loc is:
pandas.DataFrame.loc[“”]
The method returns either the row from the dataframe if they exist or the KeyError error. For example:
dfCSV = pd.read_csv("D:/Datasets/plantTraits.csv",index_col = "Name")
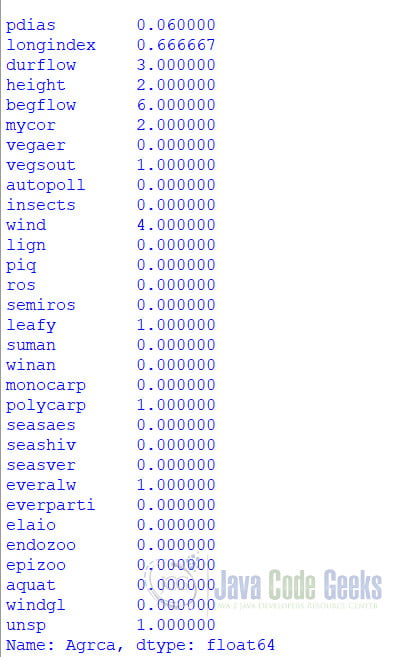
data1 = dfCSV.loc["Agrca"]
print(data1)
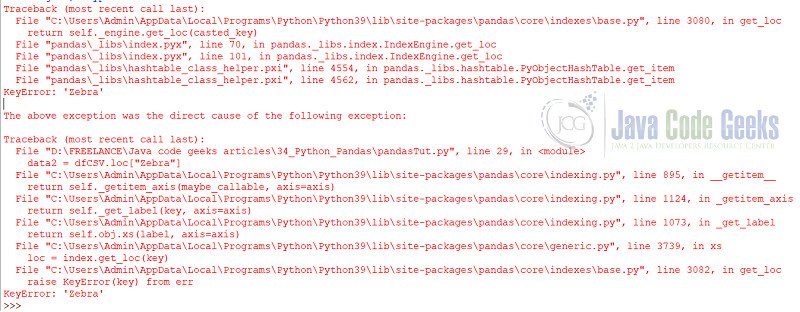
data2 = dfCSV.loc["Zebra"]
print(data2)
In the above scenario, the first index, “Agcra,” exists, and so it returns the entire row of the dataframe.
In the other example, the index, “Zebra,” does not exist, so it returns an error.
If we index based on multiple values or a single index returns multiple rows, then the result is a data frame.
data3 = dfCSV.loc[["Agrca","Vinmi","Viohi"]] print(data3)

5.3 Indexing with iloc[]
If our primary index is an integer value, we can use the iloc method for indexing. However, the iloc method is only applicable for Integer values and not for all numerical values. The iloc method returns the record based on location and not the actual value. For example, if we write:
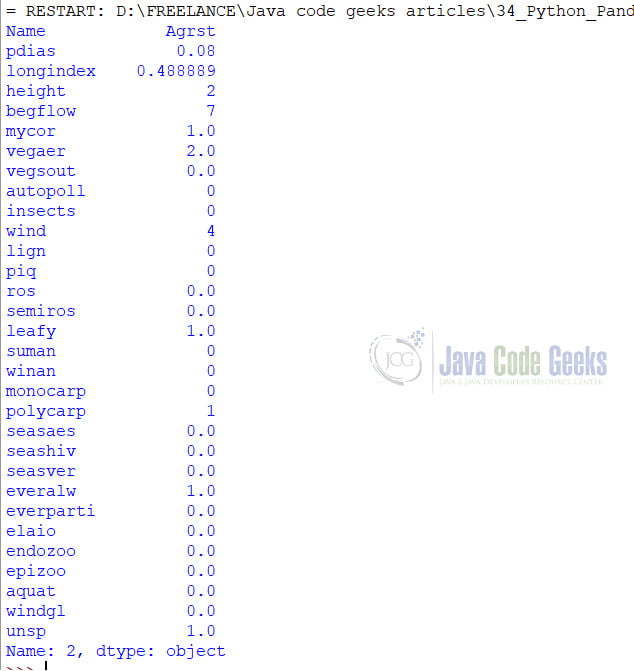
dfCSV2 = pd.read_csv("D:/Datasets/plantTraits.csv",index_col = "durflow")
print(dfCSV2.iloc[3])
The above command returns the third record from the dataframe.
We can also index records using slicing.
dfCSV2 = pd.read_csv("D:/Datasets/plantTraits.csv",index_col = "durflow")
print(dfCSV2.iloc[:3])

6. Reading JSON
We can also create a dataframe using JSON data. To use JSON data, we use the read_json data method. The options for read_json are:
pandas.read_json (path_or_buf=None, orient = None, typ=’frame’, dtype=True, convert_axes=True, convert_dates=True, keep_default_dates=True, numpy=False, precise_float=False, date_unit=None, encoding=None, lines=False, chunksize=None, compression=’infer’)
json_data = '{"col1":{"Red":1,"Blue":2,"Green":3},"col2":{"Purple":"a","Maroon":"b","Black":"z"}}'
# read json to data frame
df = pd.read_json(json_data)
print(df)

We can also convert dataframe to JSON data
7. Summary
In this article, we saw what the Pandas library is and what it can do in Python. Pandas is one of the most popular libraries in Python and is used extensively for data analysis, cleansing, and manipulation.
8. More articles
- Python Tutorial for Beginners (with video)
- Queue in Python
- Python RegEx Tutorial
- Introduction to the Flask Python Web App Framework
9. Download the Source Code
Attached below if the code used in the examples and also the csv file.
You can download the full source code of this example here: Python Pandas Tutorial
Last updated on Feb. 24th, 2022
