Hello in this tutorial, we will understand how to use the NLTK (Natural Language Toolkit) in python programming.
1. Introduction
NLTK is a powerful artificial intelligence subset present in python programming. This technique helps in manipulation and working with the text or speech with the help of programming magic. NLTK toolkit also provides an off box support to identify the named entities and do a part of speech (also known as pos) tagging for the grammar.
1.1 Setting up Python
If someone needs to go through the Python installation on Windows, please watch this link. You can download the Python from this link.
1.2 Setting up NLTK in Python
Once the python is successfully installed on your system you can install the nltk toolkit using a simple pip command. You can fire the below command from the command prompt and it will successfully download the module from nltk and install it.
Installation command
pip install nltk
2. NLTK (Natural Language Toolkit) Tutorial in Python
Before going any deeper in the practical let us download important nltk packages.
2.1 Downloading packages
The approximate package size would be around ~3GB. To download the other packages we will use a simple python program which upon execution will open a dialogue box and you can click the download button to download and automatically install the packages.
downloadnltkpackages.py
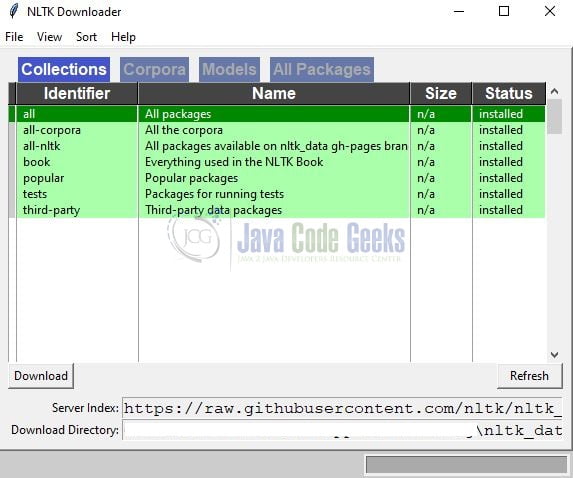
# download nltk packages # nltk stands for Natural Language Tool Kit import nltk # command will open the download window for nltk # click the download button to download the dataset as shown in fig1 nltk.download()
If everything goes well the following window would open where you can click the download button to download and install the packages (like collections, corpora, models, or all packages). My recommendation is to choose all packages as will require a majority of them in other practical implementations.
2.2 Tokenizing sentences
Tokenizing is a simple process of breaking up a sentence into a list of words and these words are known as tokens. There are 2 main tokenization techniques i.e.
- Sentence tokenization – Refers to breaking up a sentence into paragraphs
- Word tokenization – Refers to breaking up the words in a sentence
Let us see a code implementation of how sentence tokenization works in python programming and for this, we will use the sent_tokenize(…) method from the nltk.tokenize.punkt module. This method is well known to mark the beginning and end of sentences at character and punctuation.
tokenizingsentences.py
# sentence tokenization
# process of splitting up the sentence into a list of words and this list of words are known as tokens
from nltk.tokenize import sent_tokenize
random_text = "Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has " \
"been the industry's standard dummy text ever since the 1500s, when an unknown printer took " \
"a galley of type and scrambled it to make a type specimen book. It has survived not only five " \
"centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It " \
"was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum " \
"passages, and more recently with desktop publishing software like Aldus PageMaker including " \
"versions of Lorem Ipsum."
# sent_tokenize(...) uses an instance of PunktSentenceTokenizer
tokenized_sentences = sent_tokenize(random_text)
# print(tokenized_sentences)
for idx, tokenized_sentence in enumerate(tokenized_sentences):
print('{} : {}'.format(idx, tokenized_sentence))
If everything goes well the following output will be shown in the IDE console.
Logs
0 : Lorem Ipsum is simply dummy text of the printing and typesetting industry. 1 : Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. 2 : It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. 3 : It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
2.3 Tagging sentences
Tagging is a simple process of reading a word and assigning it a specific token (popularly known as the part of speech). For tagging to work we use the DefaultTagger class. Some of them are –
| Abbreviation | Description |
| CC | coordinating conjunction |
| DT | determiner |
| FW | foreign word |
| IN | preposition/subordinating conjunction |
| JJ | adjective (large) |
| JJR | adjective,comparative (larger) |
| JJS | adjective,superlative (largest) |
| NN | noun,singular (cat,tree) |
| NNS | noun plural (desks) |
| NNP | a proper noun, singular |
| NNPS | a proper noun, plural |
| RB | adverb (occasionally, swiftly) |
| RBR | adverb,comparative (greater) |
| TO | infinite marker (to) |
| UH | interjection (goodbye) |
| VB | verb (ask) |
Let us see a code implementation of word tagging in python programming.
taggingsentences.py
# tagging sentences
# tagging is responsible for reading a text in the language and assigning a specific token known to each word
# pos tagger is used to assign grammatical information to each word in a sentence
# importing part of speech tagging module
from nltk import pos_tag
random_text = "Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has " \
"been the industry's standard dummy text ever since the 1500s, when an unknown printer took " \
"a galley of type and scrambled it to make a type specimen book. It has survived not only five " \
"centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It " \
"was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum " \
"passages, and more recently with desktop publishing software like Aldus PageMaker including " \
"versions of Lorem Ipsum.".split()
tags = pos_tag(random_text)
# print(tags)
for idx, tag in enumerate(tags):
print('{} : {}'.format(idx, tag))
If everything goes well the following output will be shown in the IDE console.
Logs
0 : ('Lorem', 'NNP')
1 : ('Ipsum', 'NNP')
2 : ('is', 'VBZ')
3 : ('simply', 'RB')
4 : ('dummy', 'JJ')
5 : ('text', 'NN')
6 : ('of', 'IN')
7 : ('the', 'DT')
8 : ('printing', 'NN')
9 : ('and', 'CC')
10 : ('typesetting', 'NN')
11 : ('industry.', 'NN')
12 : ('Lorem', 'NNP')
// other statement omitted for brevity . . .
2.4 Counting tags
As in the previous section, we saw how we can use tagging. Once the tagging of words is done it is important to understand the counting as well. Let us see a code implementation of how one can count tags.
countingtags.py
# tagging sentences and counting them
# importing the counter module for counting the elements
from collections import Counter
# importing part of speech tagging module
from nltk import pos_tag
random_text = "Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has " \
"been the industry's standard dummy text ever since the 1500s, when an unknown printer took " \
"a galley of type and scrambled it to make a type specimen book. It has survived not only five " \
"centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It " \
"was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum " \
"passages, and more recently with desktop publishing software like Aldus PageMaker including " \
"versions of Lorem Ipsum.".split()
tags = pos_tag(random_text)
# print(tags)
# counting tags are important for the natural language operations
# counter is a container that keeps the count of each element present in the container
counts = Counter(tag for word, tag in tags)
print(counts)
If everything goes well the following output will be shown in the IDE console.
Logs
Counter({'NN': 20, 'NNP': 11, 'IN': 10, 'DT': 9, 'RB': 7, 'JJ': 5, 'CC': 4, 'NNS': 4, 'VBZ': 3, 'VBN': 3, 'VBD': 3, 'PRP': 3, 'VBG': 3, 'CD': 2, 'WRB': 1, 'TO': 1, 'VB': 1, 'RBR': 1})
That is all for this tutorial and I hope the article served you with whatever you were looking for. Happy Learning and do not forget to share!
3. Summary
In this tutorial, we learned:
- Introduction to nltk module in Python
- Sample program to understanding sentence tokenization, tagging, and counting of tags in python programming via nltk module
You can download the source code of this tutorial from the Downloads section.
4. Download the Project
This was a tutorial to understand the NLTK (Natural Language Toolkit) in python programming.
You can download the full source code of this example here: NLTK (Natural Language Toolkit) Tutorial in Python
