Apache Hadoop is an open source software used for distributed computing that can process large amount of data and get the results faster using reliable and scalable architecture. Apache Hadoop runs on top of a commodity hardware cluster consisting of multiple systems which can range from couple of systems to thousands of systems.
This cluster and involvement of multiple systems makes understanding Apache Hadoop a big complex. In this article we will try to see how Hadoop works.
1. Introduction
Understanding how Hadoop works under the hood is important if you want to be comfortable with the whole Hadoop ecosystem.
First of all, why was Hadoop created?
Hadoop was created to solve one problem i.e to process large amount of data which can’t be processed by single machines within acceptable time limits to get results. Organizations have large amount of such data which is why we want to process very quickly. So one solution is to divide that large amount of data into smaller sets and distribute them to multiple machines. These machines then, will process these small amount of data and give the results which is finally aggregated and the final result is reached. This is what exactly Hadoop does and this is the problem Hadoop is designed to solve.
We will have a closer look at the architecture and methods of a Hadoop clusters. We will start with the understanding of Hadoop Roles and then will dive deep into Hadoop Cluster.
2. Hadoop Cluster Nodes
In a Hadoop Cluster, machines play three types of roles:
- Client Machines
- Slave Nodes
- Master Nodes
Client machines have Hadoop installed with the cluster settings and are used to load data and to submit the MapReduce jobs for processing. Then once the data is processed as per the MapReduce job client machine retrieve the results for the user to see.
Master Nodes coordinate and perform two types of functions in the cluster. It oversees the storing of data in Hadoop Distributed File System (HDFS) and it manages running parallel computation on this data.
Slave Nodes are the nodes which perform the execution of the actual tasks and stores the data in the HDFS. Each slave node run both a DataNode to store data and a Task Tracker which communicates with the master node and performs as per the instructions.
3. Hadoop Workflow
The typical workflow of the Hadoop while executing a job includes:
- Loading data into the cluster/HDFS
- Perform the computation using MapReduce jobs
- Store the output results again in HDFS
- Retrieve the results from the cluster/HDFS
For example, if we have all the promotional email ever sent to our customers and we want to find to how many people we sent discount coupon “DISCOUNT25” in a particular campaign. We can load this data to HDFS and then write a MapReduce job which will read all the email and see if the email contains the required word and count the number of customers who received such emails. Finally, it stores the result to HDFS and from there we can retrieve the result.
3.1 Loading data into the cluster/HDFS
Hadoop cluster is of no use without data in it. For loading data is the very first step we need to perform before any kind of computation can be processed on the cluster.
Below diagram explains the write operation of HDFS. This is how the data is loaded to the cluster to be used for computation by MapReduce.
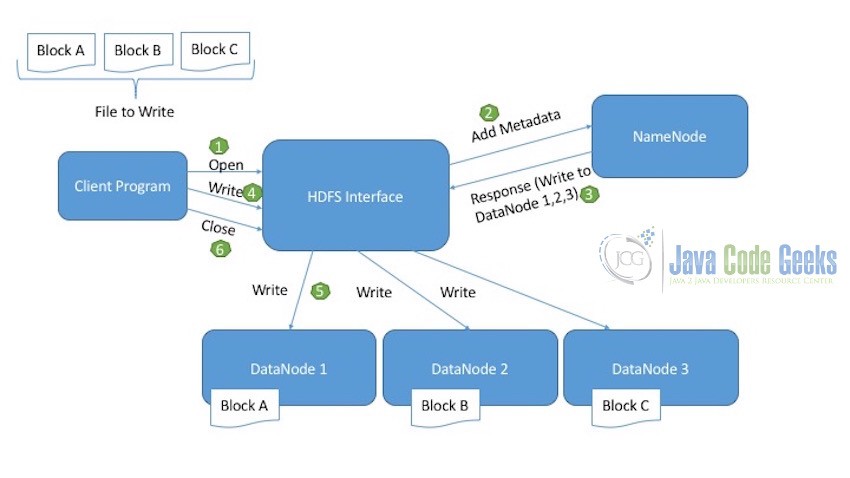
Let’s assume the file we want to write to the HDFS is divided into three blocks: Block A, Block B, Block C.
- Client first of all, initiates the read operation indicated by the open call.
- HDFS interface on receiving the new write request, connects to the NameNode and initiates a new file creation. NameNode at this points makes sure the file does not exist already and that the client program has correct permissions to create this file. If the file is already present in HDFS or the Client Program does not have the necessary permissions to write the file, an IOException is thrown.
- Once the NameNode successfully creates the new record for the file to be written in DataNodes, it tells the client where to write which block. For example, write Block A in DataNode 1, Block B in DataNode 2 and Block C in DataNode 3.
- Client then having the sufficient information regarding where to write the file blocks, calls the write method.
- HDFS interface on receiving the write call, writes the blocks in the corresponding DataNodes.
- Once the writing of all the blocks in the corresponding DataNodes is completed, the client sends the close request to indicate that the write operation is completed successfully.
Note: For further reading and understanding of HDFS, I recommend reading Apache Hadoop Distributed File System Explained
In the diagram it is shown that data chunks are stored only once, this is just to make it easy to understand. In reality, as the Hadoop clusters use commodity hardware, which is more prone to failures, we need this data to be replicated in order to provide fault-tolerance. So each block of data will be replicated in the cluster as it is loaded. The standard setting for Hadoop is to have three copies of each block in the cluster. These three copies also need to be in different racks and to do so, Hadoop needs to maintain the record of where all the data nodes are. This is the work of NameNode, it maintains the metadata regarding the position of all the DataNodes in the racks and makes sure that atleast one replica copy is on the different rack. This replication policy can also be manually configured in the HDFS configuration with setting the parameter dfs.replication in the file hdfs-site.xml
3.2 Perform the computation using MapReduce jobs
In this step, once the data is in the cluster, Client machine submits the MapReduce job to the Job Tracker. This MapReduce task contains the information how the data need to be processed and what information need to be taken out of this data. In the example, we discussed above it will be to process the email and find out the word “DISCOUNT25” in the emails.
The execution processes of Map and Reduce tasks is controlled by two types of entities:
- Jobtracker: Job tracker is the master component which is responsible for the complete execution of the overall MapReduce job. For a submitted job, there will always be a one jobtracker running on the Namenode.
- Tasktrackers: Tasktrackers are the slave components they are responsible for the execution of the individual jobs on the Datanodes.
Now when the Job Tracker receives the MapReduce job, it contacts the NameNode to ask about the DataNodes which contains this data to be processed. On receiving the information, the Job Tracker contacts the Task Trackers on the slave machines which contains the data and provide them with the Map code which need to run on the data. In this way the data is locally available on the machines which increases the processing speed.
The Task Tracker then starts the Map task and monitors the progress. It is the job of the Task Tracker to provide heartbeat and the status of the task back to the Job Tracker to keep it aware of the situation. On completion of the Map tasks, the results are also stored on the local Data Nodes. These are not the final results as Reduce tasks are still pending, these are the intermediate results and will be used by the Reduce task for final processing.
Note: Job Tracker will always try to assign the tasks in a way to maintain the data locality but this may not be always possible. For example, if the machine is already running map tasks and is not able to take any more task it will not be possible. In such cases, the Job Tracker again contacts the Name Node and see which other slave machines can be used. Machines in the same rack are preferred as the transfer of data will be comparably fast in the same rack. Name Node due to its rack awareness will be able to provide information about the free machines where Map task can be performed and then Job Tracker assigns the task to the Task Tracker on that node.

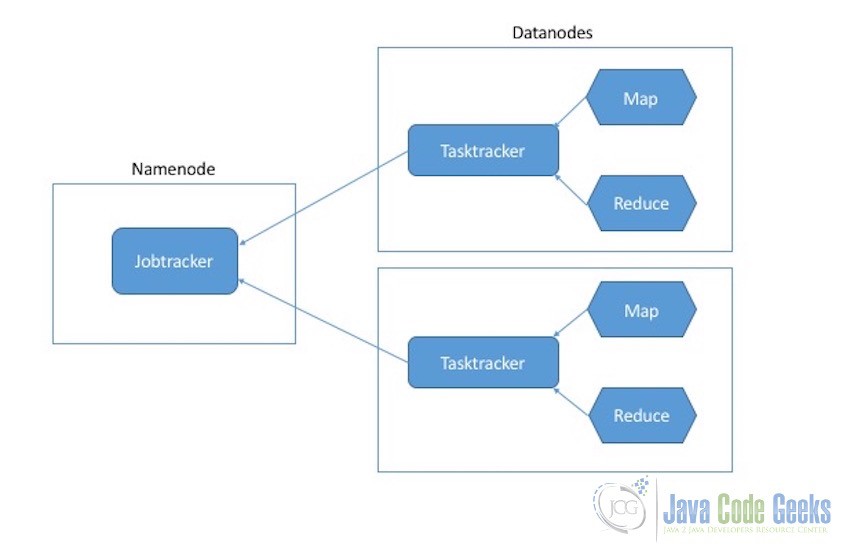
Now it is time for the Reduce task to be executed. The Job Tracker starts reduce task on any one of the free nodes in the cluster and informs the Reduce task about the location of the intermediate results generated by the Map tasks. Reduce task on receiving all the data it requires start the final processing which is to reduce and aggregate this intermediate results to produce the final result. For our example case, reduce task will aggregate the data based on the marketing campaigns and calculate how many people were sent the discount coupons in a particular campaign. Then this final result is stored in the HDFS again followed by reading of these result which we will see in the next section.
3.3 Retrieve the results from the cluster/HDFS
Once the processing of the data is done and we have our results stored in the HDFS on the Hadoop cluster, Client machine now need to retrieve this final result so that it can be used. The below diagram shows how this read operation is performed:
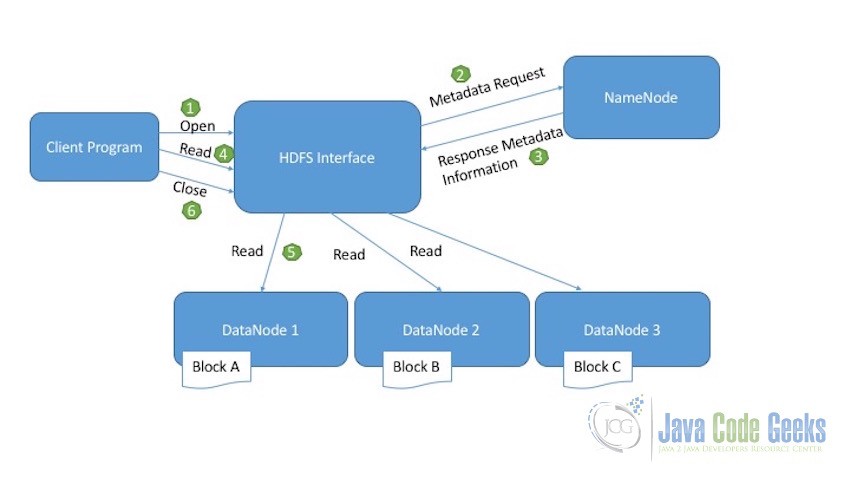
- Client Program which needs to read the file from HDFS initiates the read request by calling the open method.
- HDFS Interface receive the read request and connects to the NameNode to get the metadata information of the file. This metadata information includes location of the blocks of file.
- NameNode sends the response back with all the required metadata information required to access the blocks of data in the DataNodes.
- On receiving the location of the file blocks, the client initiates the read request for the DataNodes provided by the NameNode.
- HDFS interface now performs the actual read activity. It connects to the first DataNode which contains the first block of data. The data is returned from the DataNode as a stream. This continues till the last block of the data is read.
- Once the reading of the last block of data is finished, client send the close request to indicate the read operation is completed.
4. Dealing with Failures and Slow Tasks
Failure in the hardware is one of the most common issues in a Hadoop cluster, especially when the cluster consists of the commodity hardware. But providing fault-tolerance is one of the highest priority of the Hadoop Cluster. So lets assume a MapReduce task is in the process and there are hardware failures, how does Hadoop deal with such situations?
If a machine fails or breakdown, the Task Tracker will also stop and will not be able to send the heartbeat to the Job Tracker. Job Tracker will be able to know about the failure. In such scenario here are some strategies which are adopted by Hadoop to handle failures:
- Try again to assign the task to the same machines if it is not clear that the machine is complete brokedown. As the failure to execute the task can also be possible because of idempotence. So maybe trying again can help and the task can be executed on the same machine.
- If that doesn’t work, the task can be reassigned to another machine which have one of the replica copies of the data and any other nearby machine in the same rack.
- The final option can be to report the failure and stop the execution of the job if there are no ways to finish the computation
Now this is the case of failures but what about the slow tasks, as a single slow task can slow down the whole computation which will follow. In case of slow execution of tasks, Job Tracker initiates a new similar task in parallel on another node having a replica of the data and wait for any one of the task to finish. Whichever tasks finishes first and provides the results, those results will be used for further processing in needed and the other task and its output is abandoned.
5. Conclusion
This brings us to the end of the article, in this article we tried to understand the working of Apache Hadoop and MapReduce a little deeper. We started with understanding what are the different parts of the cluster and how they are related. Then we have seen what are the different parts of phases of which is executed on the Hadoop cluster. This help us to understand the working of Hadoop and its complete workflow.
Finally, we finished with addressing a very common issue faced in the cluster i.e. the failures and slow process and we saw what are the ways in which Hadoop Cluster handle those issues.
In hope this article helps in clearing out the the air around how Apache Hadoop works and How MapReduce runs on top of Hadoop Cluster.
