In this example, we will discuss and understand Hadoop Mappers, which is the first half of the Hadoop MapReduce Framework. Mappers are the most evident part of any MapReduce application and a good understanding of Mappers is required for taking full advantage of the MapReduce capabilities.
1. Introduction
Mapper is the base class which is used to implement the Map tasks in Hadoop MapReduce. Maps are the individual tasks which run before reducers and transforms the inputs into a set of output values. These output values are the intermediate values which act as the input to the Reduce task.
We will understand the mappers in details in the example.
2. Background
Before going into details of the Mappers, we need to do some background reading and understand some terms which we will use later in the article. Following are the terms we need to know:
- Input Format: Input format is the class which defines the input specifications for the Hadoop MapReduce job. It performs the splits on the input data so that the data can be logically assigned to multiple mappers. For example, in case of a file being the input of the MapReduce task. Input Format usually split the input based on the total size of the file and number of splits being decided based on the total number of available map tasks running with blocksize of the file being considered the maximum limit a single Input Split can be.
- Input Split: Input Split contains the data which is to be processed by an individual mapper. Input Format as discussed above is responsible for producing Input Splits and assigning each Input Split to the mapper for further processing.
Now with the background understanding of the terms and classes used by Mappers, we will go ahead and look into the workflow of the Mapper in the next section.
3. Workflow
Workflow of any individual mapper is not that complex and is quite easy to understand. A given input pair can generate zero to multiple output pairs. The workflow of mapper is as below:
- The Hadoop MaReduce framework first calls the
setupmethod for performing all the required activities to initiate themaptask. - After
setup,mapis called to perform the actual task. - Finally
cleanupis called for performing the closing functionality. - Output values of mapper are grouped together for a particular key and are then passed to the reducer for further processing which provides the final output of the MapReduce task
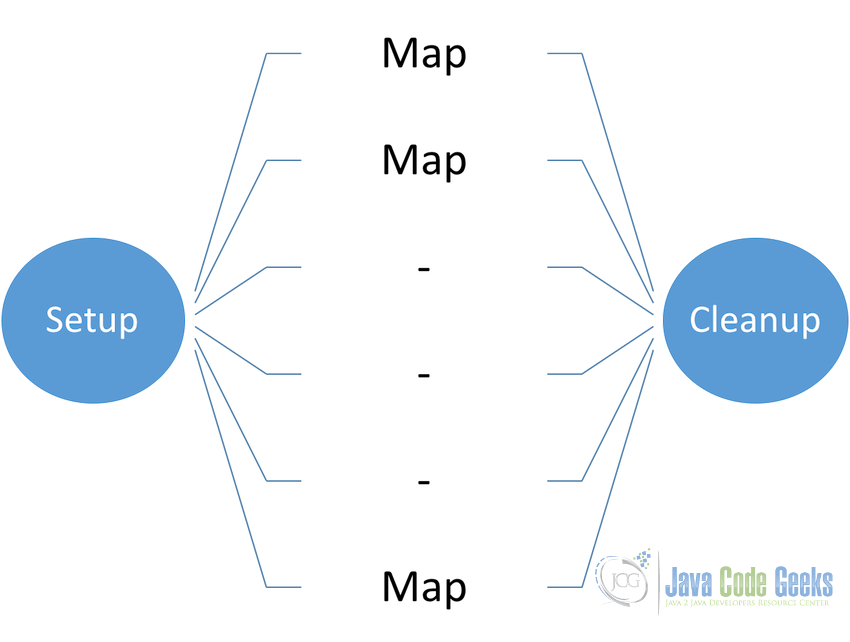
Note: In case the job have zero reducers and only mappers then the output is written to the OutputFormat directly.
4. Mapper Internals
In this section, we will go through the internals of Mapper, what are the methods available to use, how to use them and how the flow works.
Following are the methods available in the Mapper class:
- setup
- map
- run
- cleanup
Let’s see each one of these in details:
4.1 Setup
Setup method as the name indicates is used to setup the map task and is used only once at the beginning of the task. All the logic needed to run the task is initialized in this method. Most of the time, it is not required to modify or overwrite this method.
It takes the Mapper.Context object as the parameter and throws IOException and InteruptedException.
mapper.java
protected void setup(Mapper.Context context)
throws IOException,
InterruptedException
4.2 Map
This is the most important method and is the once a developer should be most aware of. Map method is called once for every key/value pair in the input to the mapper task. This is the method which we need to overwrite in any of the application we develop and it should contain all the logic need to be performed in the map task.
mapper.java
protected void map(KEYIN key, VALUIN value, Mapper.Context context)
throws IOException,
InterruptedException
This method takes the key and the value from the key-value pair in the input split and context. Map method can throw two kind of exception IOException and InterruptedException
4.3 Run
If we want to take more control of how the map task runs/executes this is the method we need to overwrite.
Run is the method which should not be modified without proper knowledge, it is the method which is responsible for running/execution of the map task. That is the reason extreme care is required in case the developer want to overwrite this method.
mapper.java
public void run(Mapper.Context context)
throws IOException,
InterruptedException
run method takes only one argument i.e. Mapper.Context and can throw two excetions similar to other methods i.e. IOException or InterruptedException
4.4 Cleanup
Cleanup is the method which is called only once at the end of the task. This method as the name indicates is responsible for the cleanup of the task residues if any.
mapper.java
proptected void cleanup(Mapper.Context context)
throws IOException,
InterruptedException
Similar to all other method this method also takes Mapper.Context as argument and can throw IOException and InterruptedException
4.5 Other Common Methods
Besides the four main methods of the Mapper class, there are some other common methods which are inherited from the java.lang.Object class as Mapper is inherited from the Object class. These methods are as following:
- clone
- equals
- finalize
- getClass
- hashCode
- notify
- notifyAll
- toString
- wait
These are quite common methods used in java and in case you want to know more about these methods, java.lang.Object is a good place to start with.
5. Hadoop Mapper Code
In this section, we will write and understand a MapReduce application with the concentration on Mapper. We will not have any Reducer class implemented for this application. So the application will be “Mapper Only Hadoop Application”.
5.1 Setup
We shall use Maven to setup a new project. Setup a maven project in Eclipse and add the following Hadoop dependency to the pom.xml. This will make sure we have the required access to the Hadoop core library.
pom.xml
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
After adding the dependency, we are ready to write our actual application code.
5.2 Mapper Class
In this mapper only application, we will create a mapper which reads the lines from an input file, each line contains the id of the pages visited on the website separated by space. So line is split and total number of pages are counted in that line. If they are more than 500, those lines are written to the context.
This is not a big use case but sufficient to clarify how mappers work.
MapClass.java
package com.javacodegeeks.examples.hadoopMapper;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* Map Class which extends MaReduce.Mapper class
* Map is passed a single line at a time, it splits the line based on space
* and calculates the number of page visits(each line contains the number corresponding to page number)
* So total length of the split array are the no. of pages visited in that session
* If pages are more then 500 then write the line to the context.
*
* @author Raman
*/
public class MapClass extends Mapper{
private Text selectedLine = new Text();
private IntWritable noOfPageVisited = new IntWritable();
/**
* map function of Mapper parent class takes a line of text at a time
* performs the operation and passes to the context as word along with value as one
*/
@Override
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] pagesVisited = line.split(" ");
if(pagesVisited.length > 500) {
selectedLine.set(line);
noOfPageVisited.set(pagesVisited.length);
context.write(selectedLine, noOfPageVisited);
}
}
}
Lines 22-23, defines the data types for the output key value pair.
Lines 29-42, overwrite the map method of Mapper class and contains the main logic.
Line 35 splits the input and followed by the check if the condition is met line 40 writes the output in the context

5.3 Driver Class
Driver class is the entry point of every MapReduce application. This is the class which sets the configuration of the MapReduce job.
Driver.java
package com.javacodegeeks.examples.hadoopMapper;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* The entry point for the WordCount example,
* which setup the Hadoop job with Map and Reduce Class
*
* @author Raman
*/
public class Driver extends Configured implements Tool{
/**
* Main function which calls the run method and passes the args using ToolRunner
* @param args Two arguments input and output file paths
* @throws Exception
*/
public static void main(String[] args) throws Exception{
int exitCode = ToolRunner.run(new Driver(), args);
System.exit(exitCode);
}
/**
* Run method which schedules the Hadoop Job
* @param args Arguments passed in main function
*/
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.printf("Usage: %s needs two arguments files\n",
getClass().getSimpleName());
return -1;
}
//Initialize the Hadoop job and set the jar as well as the name of the Job
Job job = new Job();
job.setJarByClass(Driver.class);
job.setJobName("LogProcessor");
//Add input and output file paths to job based on the arguments passed
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
//Set the MapClass and ReduceClass in the job
job.setMapperClass(MapClass.class);
//Setting the number of reducer tasks to 0 as we do not
//have any reduce tasks in this example. We are only concentrating on the Mapper
job.setNumReduceTasks(0);
//Wait for the job to complete and print if the job was successful or not
int returnValue = job.waitForCompletion(true) ? 0:1;
if(job.isSuccessful()) {
System.out.println("Job was successful");
} else if(!job.isSuccessful()) {
System.out.println("Job was not successful");
}
return returnValue;
}
}
All the settings and configurations of the Driver class are explained properly with comments but we should look specifically at line no. 57 which sets out MapClass as the Mapper and line no. 61 sets the number of reducers to be zero which makes it a mapper only application without any reducer.
5.4 Dataset
Dataset used for this example is available on the UCI Machine Learning Repository
The dataset describes the page visits of users who visited msnbc.com on September 28, 1999. Visits are recorded at the level of URL category and are recorded in time order. Each single line contains the pages/urls visited in one session by the user. Data is anonymized for contains only integers, one integer representing one page.
5.5 Running the application
For testing purpose, it is possible to run the application in local in Eclipse itself and we will do the same. In Eclipse, Pass the input file and output file name in the project arguments. Following is how the arguments looks like. In this case, the input file is in the root of the project that is why just filename is required, but if your input file is in some other location, you should provide the complete path.
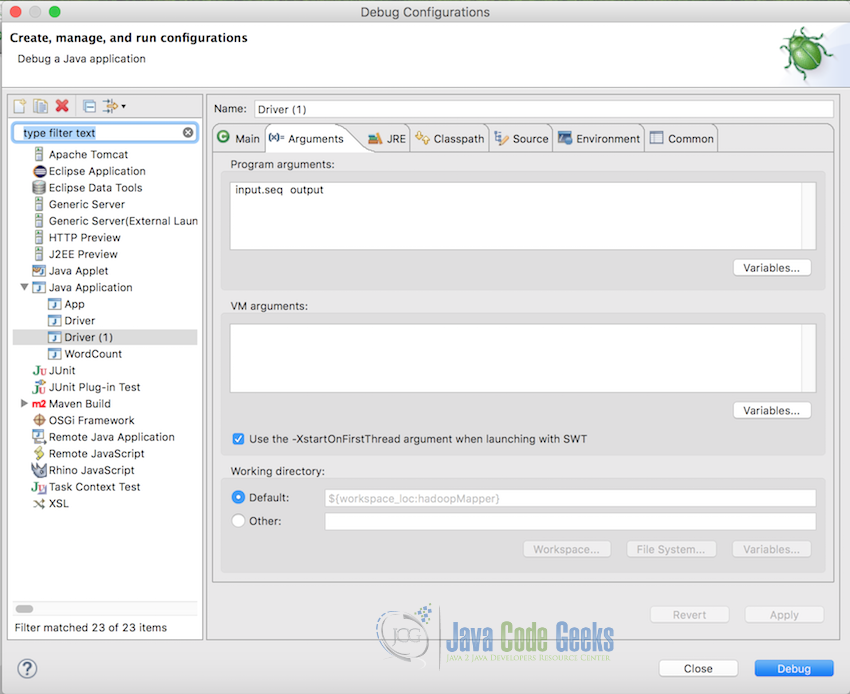
Note: Make sure the output file does not exist already. If it does, the program will throw an error.
After setting the arguments, simply run the application. Once the application is successfully completed, console will show the output as “Job Successful”. We can then check the output directory for the output result.
Hadoop applications are designed to run on the cluster in actuality. In case you want to know how to run the application on Hadoop Cluster, be it single node cluster or multiple nodes, please refer to the article Apache Hadoop Wordcount Example
6. Conclusion
This example explains the Mapper class and concept with respect to Apache Hadoop MapReduce framework. We looked into the details of the Mapper class and its workflow. Followed by understanding the methods available in the Mapper Class for implementationand in the application. Then we wrote a mapper only application for hands-on experience followed by learning how to execute the application in Eclipse itself for the testing purpose. I hope, this article serves the purpose of explaining the Mapper Class of the Hadoop MapReduce Framework and provides you with the solid base for understanding Apache Hadoop and MapReduce.
7. Download the code
Download the code and the dataset file discussed in the article.
You can download the full source code of this example here: HadoopMapper

what is the context object of type Mapper.context that is passed to each of the imp methods of the mapper class.?