1. Introduction
In this post, we feature a comprehensive Hadoop Hello World Example. Hadoop is an Apache Software Foundation project. It is the open source version inspired by Google MapReduce and Google File System.
It is designed for distributed processing of large data sets across a cluster of systems often running on commodity standard hardware.
Hadoop is designed with an assumption that all hardware fails sooner or later and the system should be robust and able to handle the hardware failures automatically.
Apache Hadoop consists of two core components, they are:
- Distributed File System called Hadoop Distributed File System or HDFS for short.
- Framework and API for MapReduce jobs.
In this example, we are going to demonstrate the second component of Hadoop framework called MapReduce and we will do so by Word Count Example (Hello World program of the Hadoop Ecosystem) but first we shall understand what MapReduce actually is.
MapReduce is basically a software framework or programming model, which enable users to write programs so that data can be processed parallelly across multiple systems in a cluster. MapReduce consists of two parts Map and Reduce.
- Map: Map task is performed using a
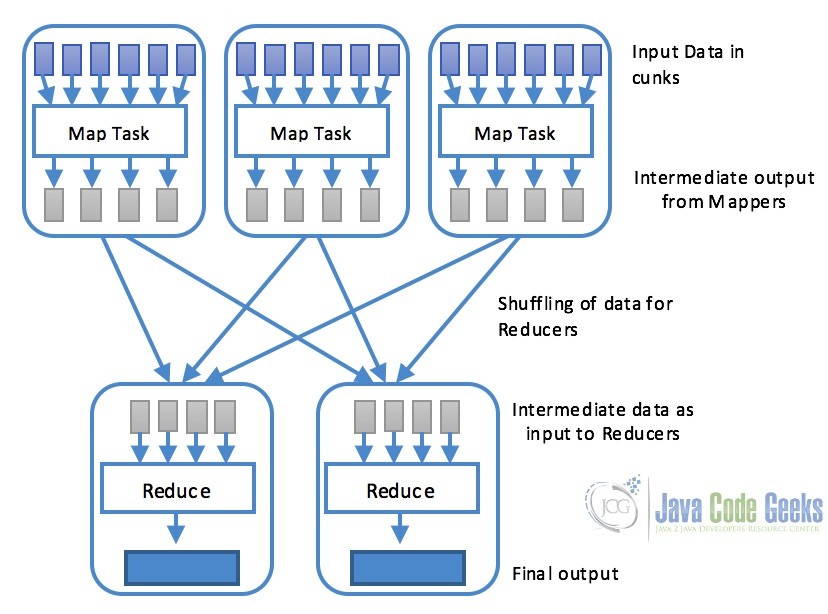
map()function that basically performs filtering and sorting. This part is responsible for processing one or more chunks of data and producing the output results which are generally referred as intermediate results. As shown in the diagram below, map task is generally processed in parallel provided the maping operation is independent of each other. - Reduce: Reduce task is performed by
reduce()function and performs a summary operation. It is responsible for consolidating the results produced by each of the Map task.
2. Hadoop Word-Count Example
Word count example is the “Hello World” program of the Hadoop and MapReduce. In this example, the program consists of MapReduce job that counts the number of occurrences of each word in a file. This job consists of two parts Map and Reduce. The Map task maps the data in the file and counts each word in data chunk provided to the map function. The outcome of the this task is passed to reduce which combines the data and output the final result on the disk.
2.1 Setup
We shall use Maven to setup a new project for Hadoop word count example. Setup a maven project in Eclipse and add the following Hadoop dependency to the pom.xml. This will make sure we have the required access to the Hadoop core library.
pom.xml
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
After adding the dependency, we are ready to write our word count code.
2.2 Mapper Code
The mapper task is responsible for tokenizing the input text based on space and create a list of words, then traverse over all the tokens and emit a key-value pair of each word with a count of one, for example, <Hello, 1>. Following is the MapClass, it needs to extends the MapReduce Mapper class and overrides the map() method. This method will receive a chunk of the input data to be processed. When this method is called the value parameter of the function will tokenize the data into words and context will write the intermediate output which will then be sent to one of the reducers.
MapClass.java
package com.javacodegeeks.examples.wordcount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MapClass extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer st = new StringTokenizer(line," ");
while(st.hasMoreTokens()){
word.set(st.nextToken());
context.write(word,one);
}
}
}
2.3 Reducer Code
Following code snippet contains ReduceClass which extends the MapReduce Reducer class and overwrites the reduce() function. This function is called after the map method and receives keys which in this case are the word and also the corresponding values. Reduce method iterates over the values, adds them and reduces to a single value before finally writing the word and the number of occurrences of the word to the output file.
ReduceClass.java
package com.javacodegeeks.examples.wordcount;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class ReduceClass extends Reducer{
@Override
protected void reduce(Text key, Iterable values,
Context context)
throws IOException, InterruptedException {
int sum = 0;
Iterator valuesIt = values.iterator();
while(valuesIt.hasNext()){
sum = sum + valuesIt.next().get();
}
context.write(key, new IntWritable(sum));
}
}
2.4 Putting it all together, The Driver Class
So now when we have our map and reduce classes ready, it is time to put it all together as a single job which is done in a class called driver class. This class contains the main() method to setup and run the job. Following code checks for the correct input arguments which are the paths of the input and output files. Followed by setting up and running the job. At the end, it informs the user if the job is completed successfully or not. The resultant file with the word counts and the corresponding number of occurrences will be present in the provided output path.
WordCount.java
package com.javacodegeeks.examples.wordcount;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCount extends Configured implements Tool{
public static void main(String[] args) throws Exception{
int exitCode = ToolRunner.run(new WordCount(), args);
System.exit(exitCode);
}
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.printf("Usage: %s needs two arguments, input and output
files\n", getClass().getSimpleName());
return -1;
}
Job job = new Job();
job.setJarByClass(WordCount.class);
job.setJobName("WordCounter");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapperClass(MapClass.class);
job.setReducerClass(ReduceClass.class);
int returnValue = job.waitForCompletion(true) ? 0:1;
if(job.isSuccessful()) {
System.out.println("Job was successful");
} else if(!job.isSuccessful()) {
System.out.println("Job was not successful");
}
return returnValue;
}
}
3. Running the example
To test the code implementation. We can run the program for testing purpose from Eclipse itself. First of all, create an input.txt file with dummy data. For the testing purpose, We have created a file with the following text in the project root.

input.txt
This is the example text file for word count example also knows as hello world example of the Hadoop ecosystem. This example is written for the examples article of java code geek The quick brown fox jumps over the lazy dog. The above line is one of the most famous lines which contains all the english language alphabets.
In Eclipse, Pass the input file and output file name in the project arguments. Following is how the arguments looks like. In this case, the input file is in the root of the project that is why just filename is required, but if your input file is in some other location, you should provide the complete path.
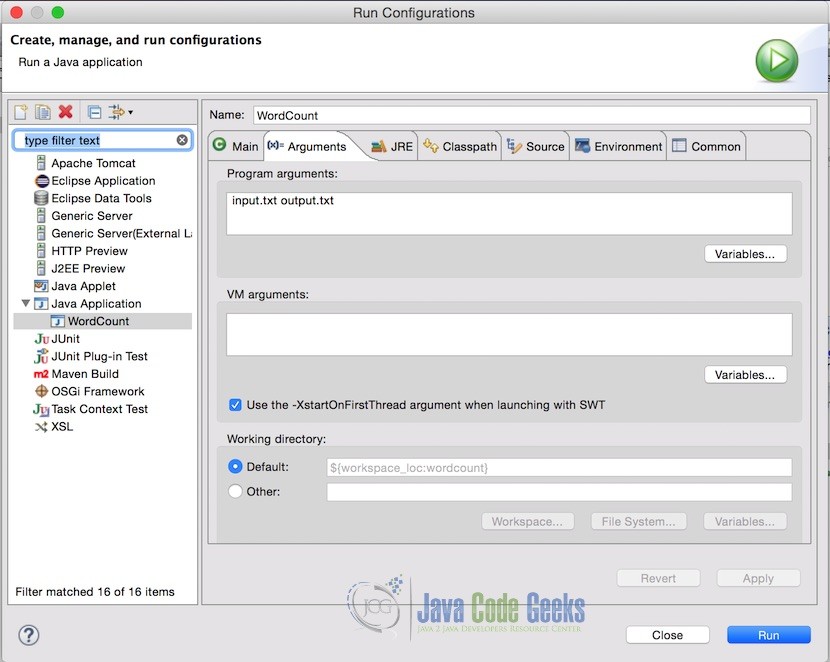
Note: Make sure the output file does not exist already. If it does, the program will throw an error.
After setting the arguments, simply run the application. Once the application is successfully completed, console will show the output
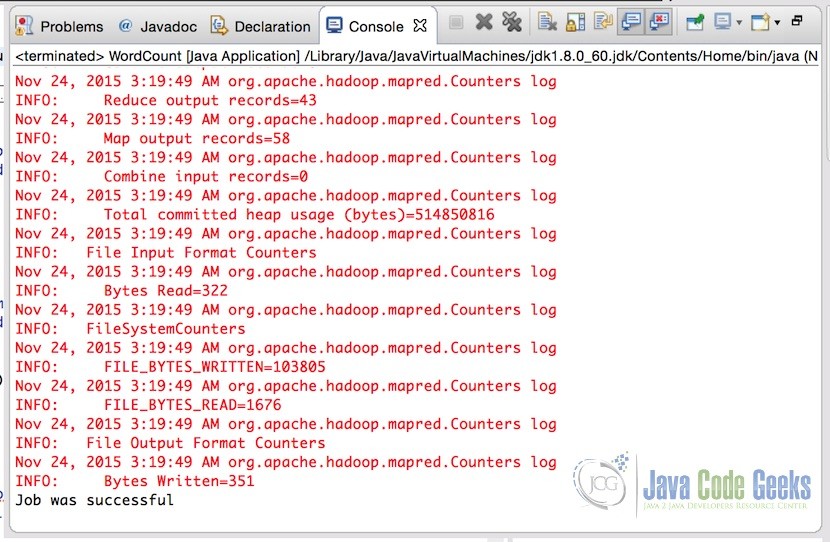
We are specifically interested in the last line:
Job was successful
That indicates the successful execution of the MapReduce job. This means that the output file is written in the destination provided in the arguments. Following is how the output file of the provided input looks like.
output
Hadoop 1 The 2 This 2 above 1 all 1 alphabets. 1 also 1 article 1 as 1 brown 1 code 1 contains 1 count 1 dog. 1 ecosystem. 1 english 1 example 4 examples 1 famous 1 file 1 for 2 fox 1 geek 1 hello 1 is 3 java 1 jumps 1 knows 1 language 1 lazy 1 line 1 lines 1 most 1 of 3 one 1 over 1 quick 1 text 1 the 6 which 1 word 1 world 1 written 1
4. Download the Complete Source Code
This was an example of Word Count(Hello World) program of Hadoop MapReduce.
You can download the full source code of this example here: Hadoop Hello World Example

very good explanation for beginner. Thanks
Very nice explanation for beginners like me. Another good resource and bunch of examples I could find here.
http://zgrepcode.com/examples/hadoop
Thank you so much. How can I continue? Plz help me.