In this example, we will go through most important commands which you may need to know to handle Hadoop File System(FS).
We assume the previous knowledge of what Hadoop is and what Hadoop can do? How it works in distributed fashion and what Hadoop Distributed File System(HDFS) is? So that we can go ahead and check some examples of how to deal with the Hadoop File System and what are some of the most important commands. Following are two examples which can help you if you are not well aware about Apache Hadoop:
Let us get started, as said in this example we will see top and the most frequently used Hadoop File System(fs) commands which will be useful to manage files and data in HDFS clusters.
Table Of Contents
1. Introduction
The Hadoop File System(FS) provides various shell like commands by default which can be used to interact with the Hadoop Distributed File System(HDFS) or any other supported file system using the Hadoop Shell. Some of the most common commands are the once used for operations like creating directories, copying a file, viewing the file content, changing ownership or permissions on the file.
2. Common Commands
In this section, we will see the usage and the example of most common Hadoop FS Commands.
2.1. Create a directory
Usage:
hadoop fs -mkdir <paths>
Example:
hadoop fs -mkdir /user/root/dir1
Command in the second line is for listing the content of a particular path. We will see this command in the next sub-section. We can see in the screenshot that dir1 is created
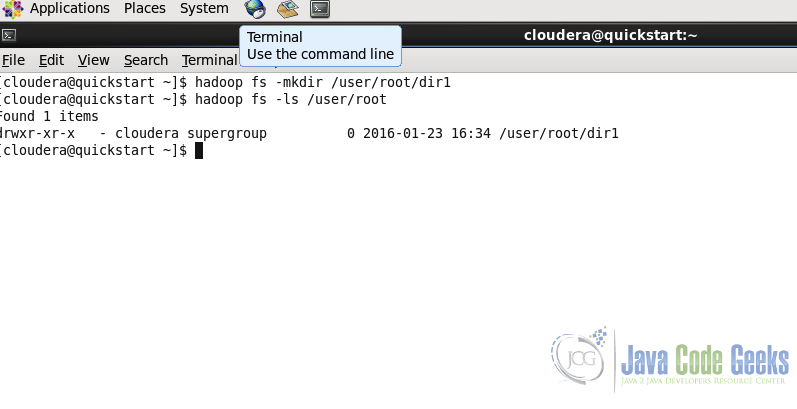
Creating multiple directories with single command
hadoop fs -mkdir /user/root/dir1 /user/root/dir2
As shown in the above example, to create multiple directories in one go just pass multiple path and directory names separated by space.

2.2. List the content of the directory
Usage:
hadoop fs -ls <paths>
Example:
hadoop fs -ls /user/root/
The command is similar to the ls command of the unix shell.
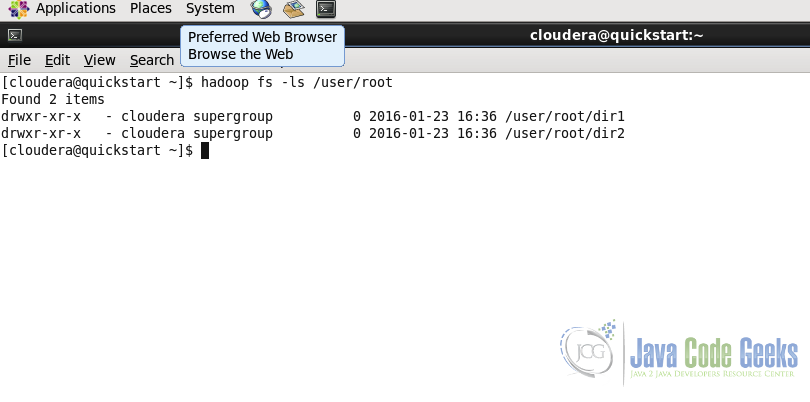
2.3. Upload a file in HDFS
Command is used to copy one or multiple files from local system to the Hadoop File System.
Usage:
hadoop fs -put <local_files> ... <hdfs_path>
Example:
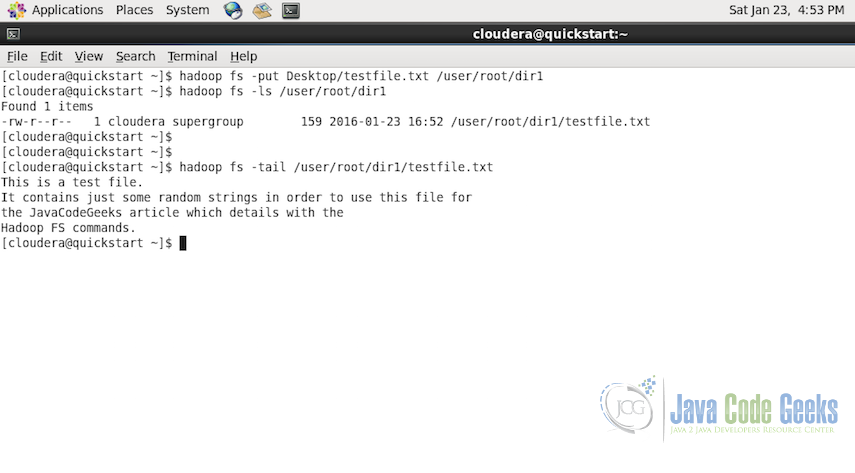
hadoop fs -put Desktop/testfile.txt /user/root/dir1/
In the screenshot below, we put the file testfile.txt from Desktop of the Local File System to the Hadoop File System at the destiantion /user/root/dir1
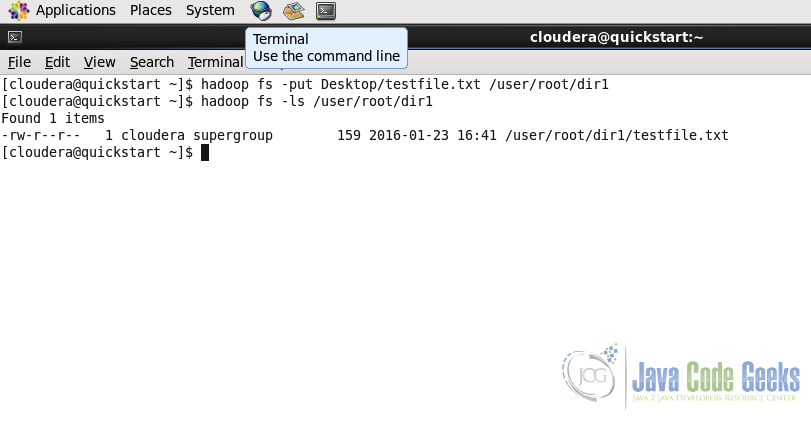
2.4. Download a file from HDFS
Download the file from HDFS to the local file system.
Usage:
hadoop fs -get <hdfs_paths> <local_path>
Example:
hadoop fs -get /user/root/dir1/testfile.txt Downloads/
As with the put command, get command gets or downloads the file from Hadoop File System to the Local File System in the Downloads folder.
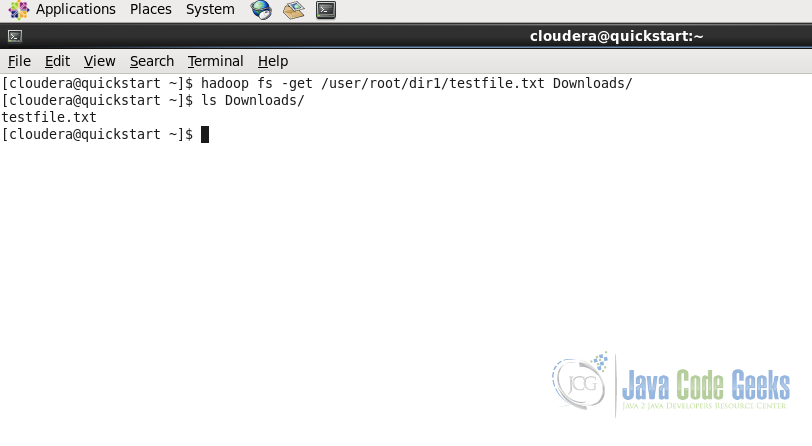
2.5. View the file content
For viewing the content of the file, cat command is available in the Hadoop File System. It is again similar to the one available in the unix shell.
Following is the content of the file which is uploaded to the Hadoop file system at the path /user/root/dir1/ in the previous steps.
Usage:
hadoop fs -cat <paths>
Example:
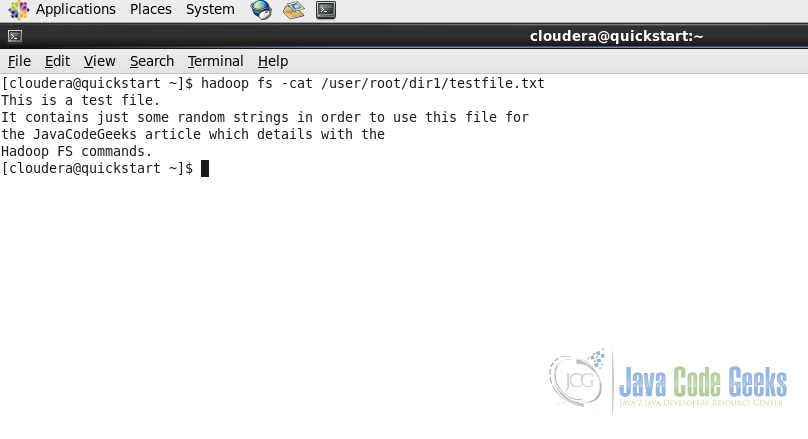
hadoop fs -cat /user/root/dir1/testfile.txt
We can see that the content displayed in the screenshot below is same as the content in the testfile.txt
2.6. Copying a file
Copying a file from one place to another within the Hadoop File System is same syntax as cp command in unix shell.
Usage:
hadoop fs -cp <source_path> ... <destination_path>
Example:
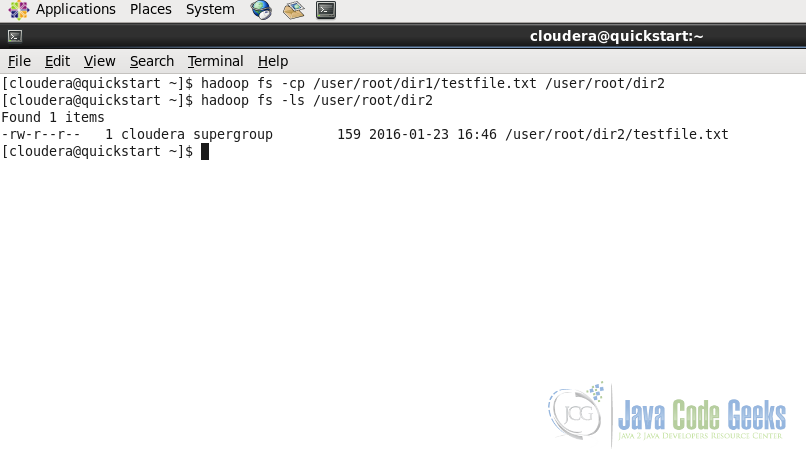
hadoop fs -cp /user/root/dir1/testfile.txt /user/root/dir2
In copying file from source to destination, we can provide multiple files in source also.
2.7. Moving file from source to destination
Following is the syntax and the example to move the file from one directory to another within Hadoop File System.
Usage:
hadoop fs -mv <source_path> <destination_path>
Example:

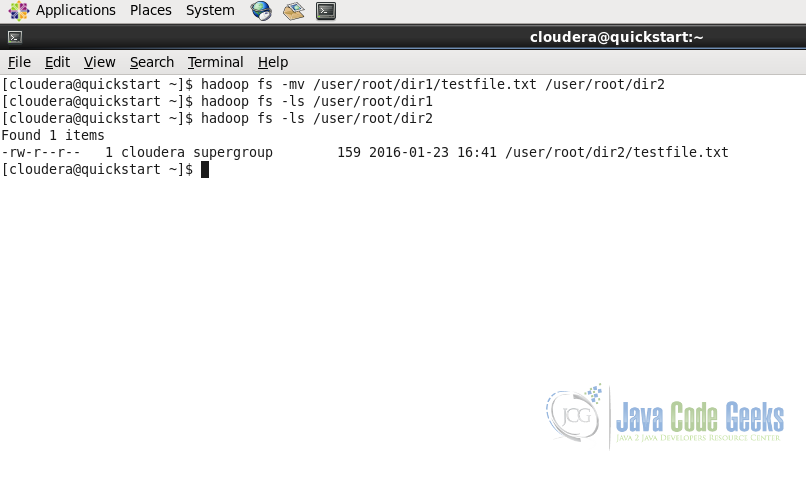
hadoop fs -mv /user/root/dir1/testfile.txt /user/root/dir2
2.8. Removing the file or the directory from HDFS
Removing a file or directory from the Hadoop File System is similar to the unix shell. It also have two alternatives, -rm and -rm -r
Usage:
hadoop fs -rm <path>
Example:
hadoop fs -rm /user/root/dir2/testfile.txt
The above command will only delete the particular file or in case of directory, only if it is empty. But if we want to delete a directory which contains other file, we have a recursive version of the remove command also.
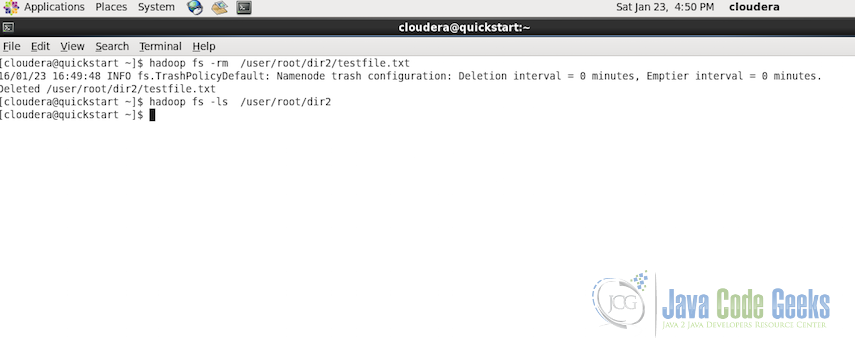
In case, we want to delete a directory which contains files, -rm will not be able to delete the directory. In that case we can use recursive option for removing all the files from the directory following by removing the directory when it is empty. Below is the example of the recursive operation:
Usage:
hadoop fs -rm -r <path>
Example:
hadoop fs -rm -r /user/root/dir2
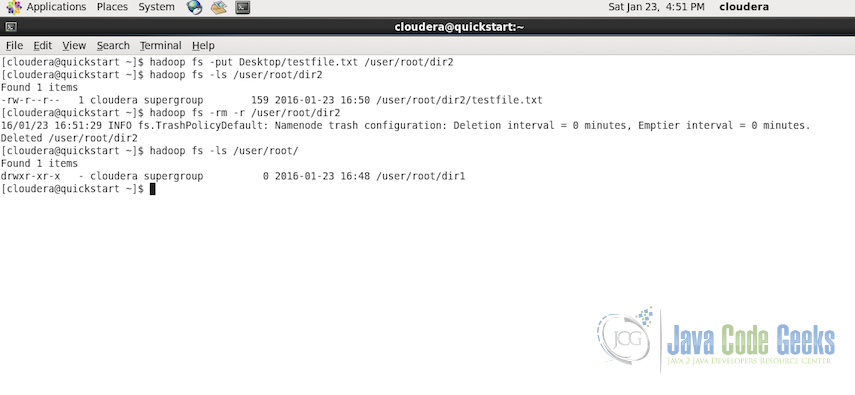
2.9. Displaying the tail of a file
The command is exactly similar to the unix tail command.
Usage:
hadoop fs -tail <path>
Example:
hadoop fs -tail /user/root/dir1/testfile.txt
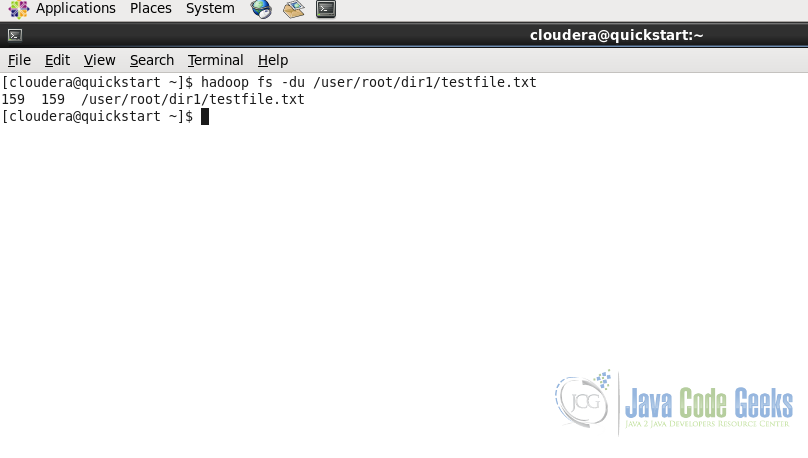
2.10. Displaying the aggregate length of a particular file
In order to check the aggregate length of the content in a file, we can use -du. command as below. If the path is of the file, then the length of the file is shown and if it is the path to the directory, then the aggregated size of the content if shown is shown including all files and directories.
Usage:
hadoop fs -du <path>
Example:
hadoop fs -du /user/root/dir1/testfile.txt
2.11. Count the directories and files
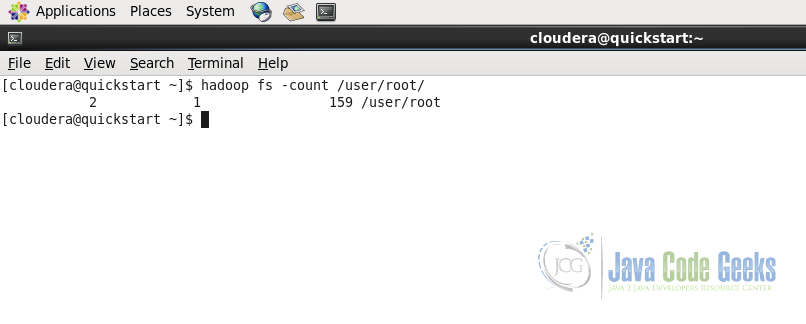
This command is to count the number of files and directories under the specified path. As in the following screenshot, the output shows the number of directories i.e. 2, number of files i.e. 1, the total content size which is 159 bytes and the path to which these stats belong to.
hadoop fs -count <path>
Example:
hadoop fs -count /user/root/
2.12. Details of space in the file system
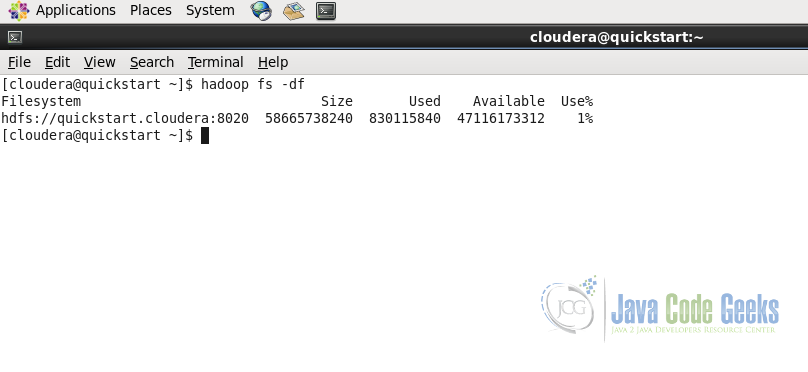
To get all the space related details of the Hadoop File System we can use df command. It provides the information regarding the amount of space used and amount of space available on the currently mounted filesystem
hadoop fs -df <path>
Command can be used without the path URI or with the path URI, when used without the path URI, it provides the information regarding the whole file system. When path URI id provided it provides the information specific to the path.
Example:
hadoop fs -df hadoop fs -df /user/root
Following screenshot displays the Filesystem, Size of the filesystem, Used Space, Available Space and the Used percentage.
3. Conclusion
This brings us to the conclusion of the example. These Hadoop File System commands will help you in getting a head start in dealing with the files and directories in the Hadoop Ecosystem.
