In this example article, we will go through Apache Hadoop Distributed Cache and will understand how to use it with MapReduce Jobs.
1. Introduction
Distributed Cache as the name indicates is the caching system to store files or data which is required frequently and this mechanism is distributed in nature as all other components of Hadoop are.
It can cache read-only text files, archives, jar files etc. Which are needed by the application. So if there is a file which is needed by let us say map tasks. So it needs to be present on all the machines which will run Map tasks, This is what distributed cache is used for.
2. Working
Application which needs to use distributed cache to distribute a file should make sure that the file is available and can be accessed via urls. Urls can be either hdfs:// or http://.
Now once the file is present on the mentioned url and user mention it to be a cache file to the distributed cache API, the Map-Reduce framework will copy the necessary files on all the nodes before initiation of the tasks on those nodes.
Notes: In case the files provided are archives, these will be automatically unarchived on the nodes after transfer.
3. Implementation
For understanding how to use the distributed cache API we will see an example in which we will write a modified version of the word count program.
For the basic word count example and if you like to understand the basics of how MapReduce job works, please refer to the article Apache Hadoop Wordcount Example
In this program, we will provide an input file to the Map-Reduce job with the words we need to count but we will also provide another file which contains stop words which we need to remove from the input text before counting the word occurrences.
So let’s start looking into the code:
3.1 The Driver Class
The driver class is the main entry point of the system and the class which set up the Map-Reduce job.
package com.javacodegeeks.examples.distributedcache;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* The entry point for the WordCount example,
* which setup the Hadoop job with Map and Reduce Class
*
* @author Raman
*/
public class Driver extends Configured implements Tool{
/**
* Main function which calls the run method and passes the args using ToolRunner
* @param args Two arguments input and output file paths
* @throws Exception
*/
public static void main(String[] args) throws Exception{
int exitCode = ToolRunner.run(new Driver(), args);
System.exit(exitCode);
}
/**
* Run method which schedules the Hadoop Job
* @param args Arguments passed in main function
*/
public int run(String[] args) throws Exception {
if (args.length != 3) {
System.err.printf("Usage: %s needs two arguments files\n",
getClass().getSimpleName());
return -1;
}
//Initialize the Hadoop job and set the jar as well as the name of the Job
Job job = new Job();
job.setJarByClass(Driver.class);
job.setJobName("Word Counter With Stop Words Removal");
//Add input and output file paths to job based on the arguments passed
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
//Set the MapClass and ReduceClass in the job
job.setMapperClass(MapClass.class);
job.setReducerClass(ReduceClass.class);
DistributedCache.addCacheFile(new Path(args[2]).toUri(), job.getConfiguration());
//Wait for the job to complete and print if the job was successful or not
int returnValue = job.waitForCompletion(true) ? 0:1;
if(job.isSuccessful()) {
System.out.println("Job was successful");
} else if(!job.isSuccessful()) {
System.out.println("Job was not successful");
}
return returnValue;
}
}
Above is the complete code of the driver class. You can see is the main() method we set up and initialize a Hadoop Job(). First of all this code checks for the arguments passed to the method. Arguments need to be 3 in number:
- Input text file path which containc the text for word count
- Output path for storing the output of the program
- File path and name containing the stop words which we will distribute through the Hadoop Distributed Cache
The code:
if (args.length != 3) {
System.err.printf("Usage: %s needs two arguments files\n",
getClass().getSimpleName());
return -1;
}
checks for the number fo arguments and make sure we have the required number of arguments present otherwise it stops the program then and there.
After this the Job is initialized:
//Initialize the Hadoop job and set the jar as well as the name of the Job Job job = new Job();
followed by all the necessary configuration settings including configuring the jar file, map and reduce classes, input and output methods and input and output paths.
Out main focus here is on the line number 61, which is:
DistributedCache.addCacheFile(new Path(args[2]).toUri(), job.getConfiguration());
This line of code calls the DistributedCache API and adds the cache file URL which we passed as the third argument to the program. Before passing this argument, it need to be converted to the path url. Second argument needs to be the configurations of the Hadoop job we are setting up.
The above code will set up the Hadoop Job and sets up the required file as the cache file in the Hadoop cluster. It is as easy as calling a single function. The main task is how to retrieve this cache file and how to use it to remove stop words from the processing text. That we will see in the map class in the following section.
3.2 Map Class
Map class contains the mapper method which is the main focus which contains the code regarding how to use the cache files in the MapReduce Tasks.
package com.javacodegeeks.examples.distributedcache;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
import java.util.StringTokenizer;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* Map Class which extends MaReduce.Mapper class
* Map is passed a single line at a time, it splits the line based on space
* and generated the token which are output by map with value as one to be consumed
* by reduce class
* @author Raman
*/
public class MapClass extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
private Set stopWords = new HashSet();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
try{
Path[] stopWordsFiles = DistributedCache.getLocalCacheFiles(context.getConfiguration());
if(stopWordsFiles != null && stopWordsFiles.length > 0) {
for(Path stopWordFile : stopWordsFiles) {
readFile(stopWordFile);
}
}
} catch(IOException ex) {
System.err.println("Exception in mapper setup: " + ex.getMessage());
}
}
/**
* map function of Mapper parent class takes a line of text at a time
* splits to tokens and passes to the context as word along with value as one
*/
@Override
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer st = new StringTokenizer(line," ");
while(st.hasMoreTokens()){
String wordText = st.nextToken();
if(!stopWords.contains(wordText.toLowerCase())) {
word.set(wordText);
context.write(word,one);
}
}
}
private void readFile(Path filePath) {
try{
BufferedReader bufferedReader = new BufferedReader(new FileReader(filePath.toString()));
String stopWord = null;
while((stopWord = bufferedReader.readLine()) != null) {
stopWords.add(stopWord.toLowerCase());
}
} catch(IOException ex) {
System.err.println("Exception while reading stop words file: " + ex.getMessage());
}
}
}
Now this is where this code varies significantly from the standard word count MapReduce code. The map class contains a setup method which is the first method called when a node is setup to perform the map task.
@Override
protected void setup(Context context) throws IOException, InterruptedException {
try{
Path[] stopWordsFiles = DistributedCache.getLocalCacheFiles(context.getConfiguration());
if(stopWordsFiles != null && stopWordsFiles.length > 0) {
for(Path stopWordFile : stopWordsFiles) {
readFile(stopWordFile);
}
}
} catch(IOException ex) {
System.err.println("Exception in mapper setup: " + ex.getMessage());
}
}
So this is the place where we read the file stored in the distribute cache using the DistributedCache API and getLocalCacheFiles() method as shown in the line number 4 of the above code snippet. If you notice the methods return an array of the type Path. So for each file(we have only one in this case) we will call another method called readFile() and pass the path of the file to this method.
readFile() is the method which reads the content of the file and adds the stop words in the global Set of stopWords. The details of the method are in line numebr 67-77 of the Map class.

Now in the map() method, after splitting the lines into word tokens, we will check if a particular word is present in the stop words set, if it is present we skip that word and move to the next but if it is not a stop word then we pass it on to the context to be executed in the Reduce class as shown in the code snippet below:
StringTokenizer st = new StringTokenizer(line," ");
while(st.hasMoreTokens()){
String wordText = st.nextToken();
if(!stopWords.contains(wordText.toLowerCase())) {
word.set(wordText);
context.write(word,one);
}
}
3.3 Reduce Class
Reduce class in this article is exactly same as it is in the standard word count example, the reduce() method will contain only those words which are not stop words and reduce will count only the good words. Following is the code of the reduce class:
package com.javacodegeeks.examples.distributedcache;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* Reduce class which is executed after the map class and takes
* key(word) and corresponding values, sums all the values and write the
* word along with the corresponding total occurances in the output
*
* @author Raman
*/
public class ReduceClass extends Reducer{
/**
* Method which performs the reduce operation and sums
* all the occurrences of the word before passing it to be stored in output
*/
@Override
protected void reduce(Text key, Iterable values,
Context context)
throws IOException, InterruptedException {
int sum = 0;
Iterator valuesIt = values.iterator();
while(valuesIt.hasNext()){
sum = sum + valuesIt.next().get();
}
context.write(key, new IntWritable(sum));
}
}
4. Executing the Hadoop Job
We will execute the MapReduce task we discussed in the previous section on the Hadoop cluster. But before we do so, we need two files
- Input file
- Stop Words file
So following is the dummy text file which we will use for the example:
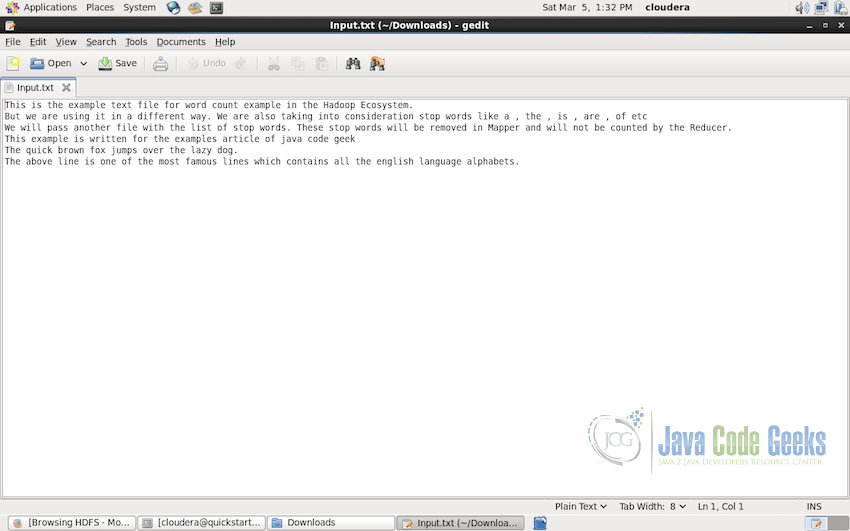
and following is the file containing stop words:
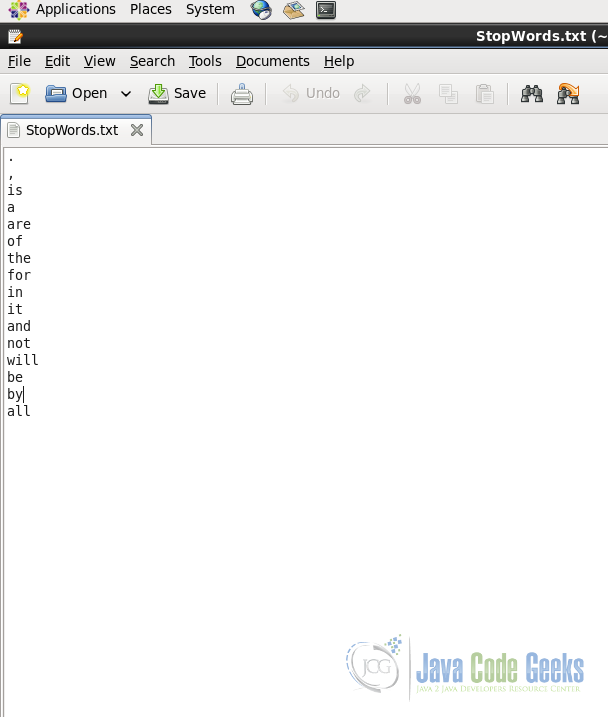
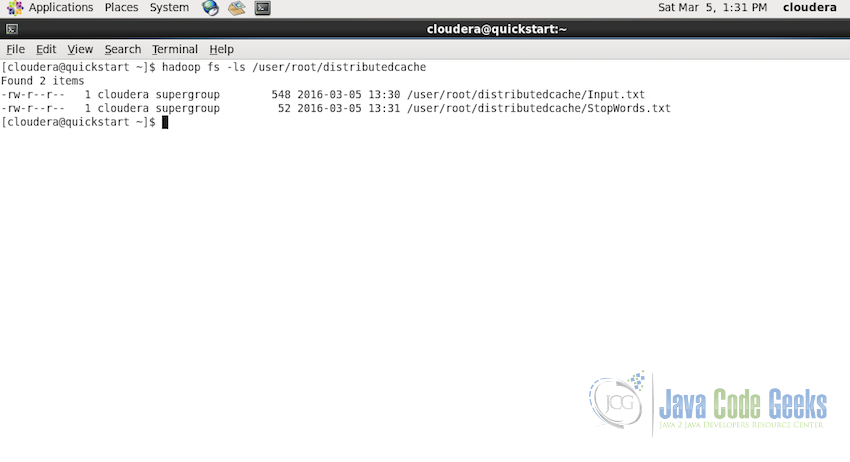
Make sure that both the files are present in the Hadoop Distributed File System. If you would like to read about the basics of HDFS and Hadoop File System including how to put files in HDFS, please refer to the article Apache Hadoop FS Commands Example
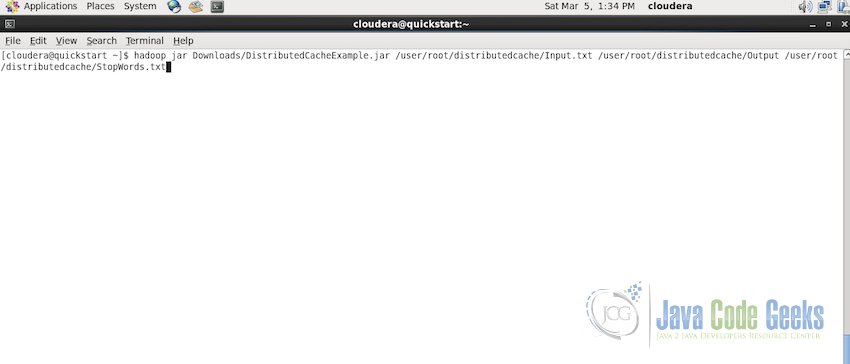
Now, to execute the Distributed Cache Example Task on the Hadoop Cluster, we have to submit the jar file along with the URLs of the input and stopwords files to the Hadoop Cluster. Following is the command to do so:
hadoop jar DistributedCacheExample.jar /user/root/distributedcache/Input.txt /user/root/distributedcache/Output /user/root/distributedcache/StopWords.txt
First argument mentions the input file to be used, second argument tells about the path where the output should be stored and the third argument tells the path of the stop words file.
Once the job is successfully executed we will a console output something similar to:
Notice the last line which says “Job was successful”. This is the line we printed from the Driver class on successful execution of the job. You can check the other details in the console output to know more about the job execution.
The output of the Hadoop job will be present on the HDFS path /user/root/distributedcache/Output in the Output folder as mentioned in the execution argument, this folder can be downloaded on the system from the HDFS. Following is how the output file looks like:
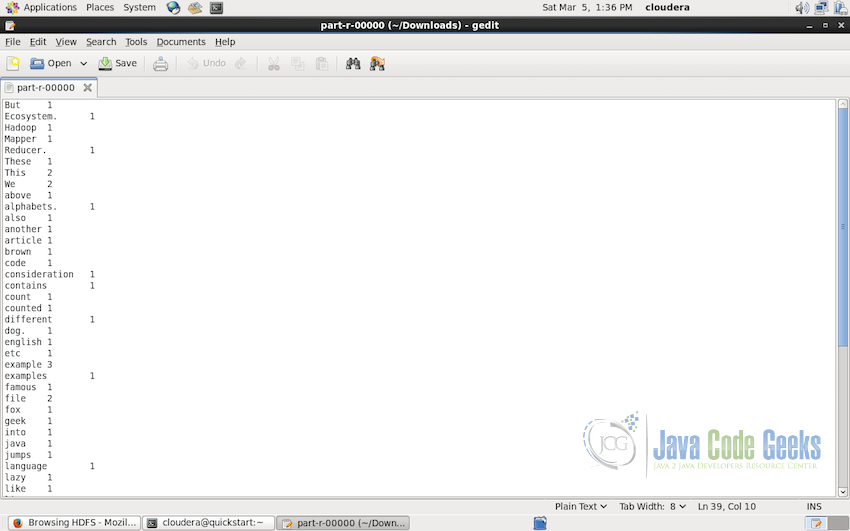
5. Conclusion
In this example article, we talked about the Distributed Cache API of Apache Hadoop. We started with the introduction of what exactly distributed cache is and then understood the basic workflow of the distributed cache. Then we dived into the implementation section where we saw how we can use the Distributed Cache API to pass the common files, jars and other archives to the nodes executing the Hadoop Job.
6. Download the Eclipse Project
Complete code of the example and the dummy input and stop words text file can be useful for experimentation.
You can download the full source code of this example here: DistributedCacheExample

Nice Tutorial but seems DistributedCache is deprecated form hadoop 2.2.0
https://stackoverflow.com/questions/21239722/hadoop-distributedcache-is-deprecated-what-is-the-preferred-api