Welcome readers, in this tutorial, we will understand AWS Athena and its related terminology.
1. Introduction to AWS Athena
Amazon Athena is nothing but a data analytics tool that performs complex query operations in relatively less time. Athena performs database automation, parquet file conversion, table creation, SQL operations, partitioning, etc. It a graphical user interface to analyze the S3 data using standard SQL operations.
- It is an infrastructure-less service
- Developers only pay for the queries they run as it is not a dB service
- Offers automatic scaling and faster results while executing on the large dataset or performing complex operations
- Offers to execute different queries in parallel
1.1 Athena features
- Does not require a physical installation and can be directly accessed from the AWS console or CLI
- Does not require an infrastructure or configuration setup and offers automatic scaling
- It only charges for the query we run i.e. the amount of data managed per query
- It’s a fast analytics tool to perform the complex operation(s) in a relatively less time
- Athena provides complete control and isolation over dataset by using IAM policies
- Offers high availability and integration (such as AWS Glue to create better versioning, tables, views, etc.)
1.2 Difference between Microsoft SQL Server and Athena
| Features | Microsoft SQL server | Athena |
|---|---|---|
| Database and an analytics management system | Only used for the dB data manipulation operations | |
| Benefits | Easy to use and offers high performance | Though it is easy to use and offers high performance. The advantage here is that no maintenance and server configuration is required |
| Integration | Presto, SQLDep, etc. | S3, Glue, and Presto |
| Limitations | Limited RDS storage, instances and cannot handle recursions | No data definition language support and works with external tables only. In addition, user-defined functions are not supported |
2. What is Amazon AWS Athena?
Now as well know a brief about Athena, let us take a look at how to query data stored as JSON file in S3 using Athena. It’s a simple 4 step process i.e.
- Create multiple JSON files containing the data
- Store the files to the S3 bucket
- Create an external table for the files stored in the S3 bucket
- Write a query to access the data
But before going for the demo I am hoping that readers have an AWS account and are aware of the cloud computing concepts and its basics.
2.1 Creating a JSON file
Let us create a simple file JSON file containing the data without a newline character. Readers can use the below data for sample file content.
Sample JSON file content
01 02 03 04 05 06 07 08 09 10 | {"id":1,"first_name":"Arlie","last_name":"Backman","gender":"Female","email_address":"abackman0@geocities.com","dob":"14-Dec-1989"}{"id":2,"first_name":"Aeriela","last_name":"Glentworth","gender":"Female","email_address":"aglentworth1@webnode.com","dob":"15-Jul-1990"}{"id":3,"first_name":"Henri","last_name":"Westmarland","gender":"Male","email_address":"hwestmarland2@apple.com","dob":"02-Apr-1994"}{"id":4,"first_name":"Marina","last_name":"Ranklin","gender":"Female","email_address":"mranklin3@ihg.com","dob":"30-Jan-1993"}{"id":5,"first_name":"Aldrich","last_name":"Becom","gender":"Male","email_address":"abecom4@yahoo.co.jp","dob":"07-Jun-1995"}{"id":6,"first_name":"Pearl","last_name":"Speere","gender":"Female","email_address":"pspeere5@sogou.com","dob":"09-Nov-1994"}{"id":7,"first_name":"Lisbeth","last_name":"Beech","gender":"Female","email_address":"lbeech6@statcounter.com","dob":"29-Jun-2000"}{"id":8,"first_name":"Avigdor","last_name":"O'Hara","gender":"Male","email_address":"aohara7@rediff.com","dob":"02-Dec-2001"}{"id":9,"first_name":"Gerta","last_name":"Calderon","gender":"Female","email_address":"gcalderon8@furl.net","dob":"01-Apr-1996"}{"id":10,"first_name":"Ashby","last_name":"Blasoni","gender":"Male","email_address":"ablasoni9@1und1.de","dob":"11-Apr-1991"} |
2.2 Storing the file to the S3 bucket
For storing the file into the S3 bucket we will be using the AWS CLI. Developers can read the existing tutorial available at this link to get a fair understanding. Open the AWS CLI terminal and trigger the commands.
AWS CLI commands
1 2 3 4 5 | # Creating a new s3 bucket (remember the bucket name has to be globally unique)aws s3 mb s3://jcgassignmentathena# Copy files from local directory to the s3 directoryaws s3 cp C:\Users\XXXX\Desktop\Test_data\testdatadb.json s3://jcgassignmentathena |
If everything goes well the file will be successfully uploaded to the s3 bucket.

2.3 Creating Table in Athena
There are two ways of creating a table in Amazon Athena and in this tutorial we will explore the manual one. Open the Athena service in the AWS console and select the option to Create a table from S3 bucket data. Once the option is clicked we will need the following details as shown in Fig. 2.
- Either create a new database or select the existing database
- Enter the table name
- Enter the location of the input data step (i.e. the path of the file containing the JSON data)
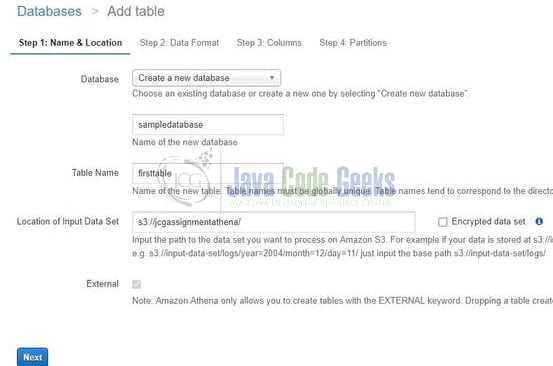
Once done click Next and enter the type of file you will be working with (such as CSV, TXT, JSON, etc.) In our case, we have selected the JSON file and click Next. At Step 3 we will create the architecture of the data (i.e. the key becomes the column and the value becomes the data-type of the column). For instance – The id key in the JSON file will correspond to a column name and the data-type for this column will be a string and so on.
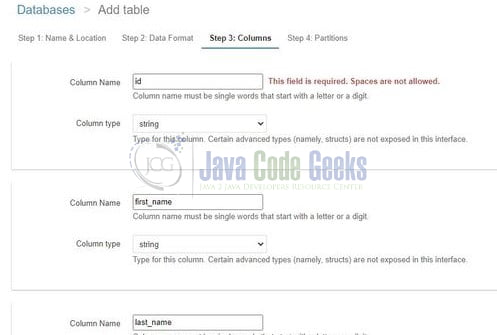
Note: The image is cropped for the simplicity purpose.
Once done click Next and click on the Create Table button. As the data in the JSON file is not complexed, so we don’t need the partition. Now if everything goes you will be shown the image as in Fig. 4 where one can verify the column names and the location of the s3 bucket from where-in the data will be created in the table.
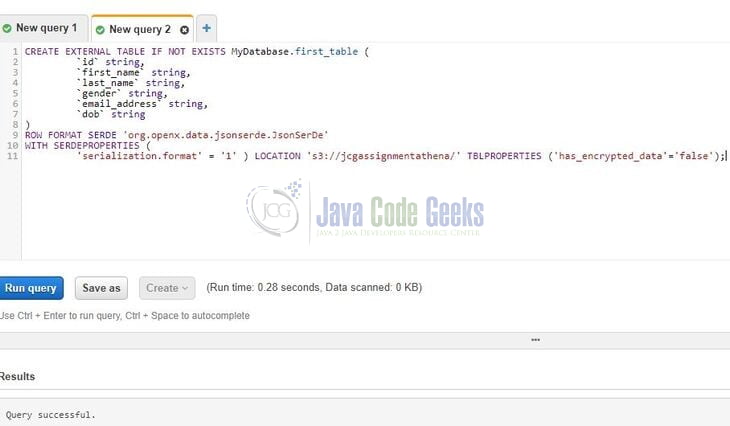
Click on the Run Query and the table will be successfully created as shown in the above figure.
2.4 Viewing Data
Now to get all the data from the table we will use the SQL SELECT query. Open the new query console and enter the query.
SQL SELECT query
1 2 3 4 5 | # Query syntaxSELECT * from <table_name># Example querySELECT * FROM first_table; |
Click on the Run query and we will have all in the information in our table as shown in Fig. 5.
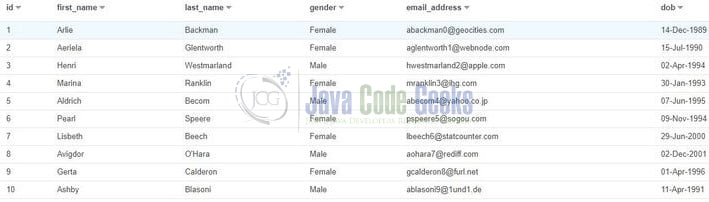
That is all for this tutorial and I hope the article served you whatever you were looking for. Happy Learning and do not forget to share!
3. Summary
In this section, we covered the following:
- Introduction to Amazon Athena and its characteristics
- A sample demo of inserting the data into the Athena table from the S3 bucket and query the data.
4. Download the source code
You can download the sample JSON file and commands used in this example from here: What is Amazon AWS Athena
