In the previous tutorial we learned the installation process and basics of MongoDB. In this example we shall learn how to create, manage and delete Databases in MongoDB.
1. Create Database
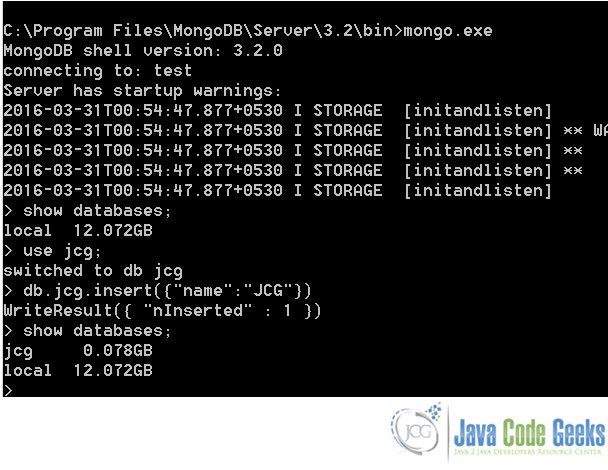
Creating a database is simple in MongoDB. We just need to select the database name using the below command :
use <database_name>
We use the show databases command to see all the available databases. However, we cannot see the new database with the show command immediately after creating it. We need to add some document to the database to be able to view it.
Here’s a sample screen-capture:
2. Drop Database
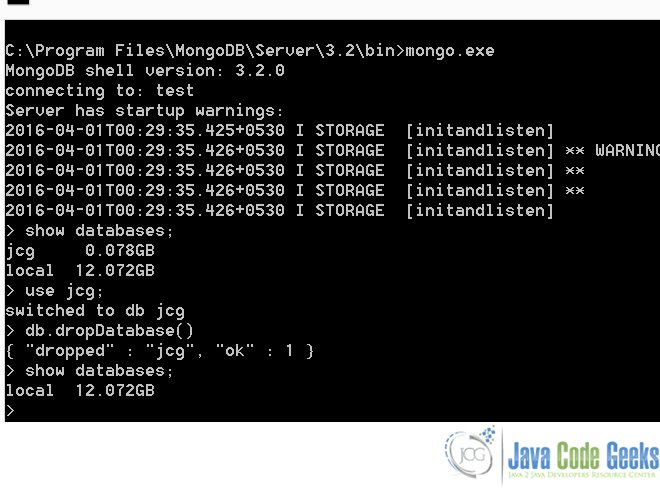
Dropping the database is simple. We just need to select the database using the use command and then execute the below command:
db.dropDatabase();
Executing the above command will now delete the selected database.
3. Database Replication
When the traffic to a single server increases the throughput starts decreasing as there are only a limited number of requests the server can service at a time. To address this problem, we replicate the MongoDb server.
Replica Set A replica set is basically a group of Mongod running instances. In this set, exactly one node(instance) can be a primary node. The write operations are performed on this node. When a new secondary node is added to the replica set, it replicates the primary’s dataset. Subsequently, to maintain the non-stale data-set, the secondary nodes asynchronously copy the operations log from the primary server and apply it to their data-sets. A client cannot write to the secondary nodes, but it can read from the secondary set.
To create a MongoDb replica server we follow the below steps:-
1. Start a Mongodb node:
mongod.exe --dbpath C:\MongoDb\Data --replSet rs0
2. Next step is to connect to this mongod instance using the below command and initiate the replica set.
rs.initiate();
This completes the set up of replica set. To check the status of the replica set we use the rs.status() command. To review the configuration information of this set we use rs.conf() command.
We can add more nodes to this replica set using rs.add(HOST_NAME:PORT) command.
To change the priority of the nodes we add the store the config info in a variable and then modify the priority.
conf = rs.conf(); conf.members[0].priority = 2 rs.reconfig(conf)
Whenever the primary node in the set becomes available, one of the Non-Priority 0 secondary nodes becomes the primary by the voting. A node with a priority zero cannot become a Primary node.
4. Sharding
Sharding is breaking up the data-set into different parts and hosting these parts on different nodes. Whenever, the size of data-set grows too big the data is split and stored across multiple nodes. We can create shard node using the below command:
mongod.exe --configsvr --replSet configReplSet --dbpath C:\MongoDb\Data
Then we need to initiate the shard using the rs.initiate() command after connecting to this mongod instance with a mongo shell
The next step is to start a mongos instance. The mongos instances are like routers used to route the traffic to the appropriate shard. We start such an instance by following command:
mongos --configdb configReplSet/localhost:27019,localhost:27059
The config servers are separated by a comma ,. We may add more shards with the sh.addShard( "HOST_NAME:PORT" ) command.
Usually, each shard should have at least one secondary replica so that the data is available even when the primary shard node goes down.
5. MongoDB Dump and restoration
Dump facility is used to create a replica of an existing data-set or to store a snapshot of the data-set at any particular point in time. Mongodb supports this facility with the mongodump command. This creates a mongo dump.
To restore the data-set from this data-dump, simply run the below command and specify the location of the dump file.
mongorestore --dir dumpfilelocation
Also note that it is possible to dump and restore only a particular collection or a database instead of the whole data-set. This can be achieved by specifying the --collection --db arguments.
6. Conclusion
In this example, we studied advanced concepts like Sharding, Replication which help drastically improve the performance of MongoDB.
