This article is a tutorial about parallel processing in Spring Batch. We will use Spring Boot to speed our development process.
1. Introduction
Spring Batch is a lightweight, scale-able and comprehensive batch framework to handle data at massive scale. Spring Batch builds upon the spring framework to provide intuitive and easy configuration for executing batch applications. Spring Batch provides reusable functions essential for processing large volumes of records, including cross-cutting concerns such as logging/tracing, transaction management, job processing statistics, job restart, skip and resource management.
Spring Batch has a layered architecture consisting of three components:
- Application – Contains custom code written by developers.
- Batch Core – Classes to launch and control batch job.
- Batch Infrastructure – Reusable code for common functionalities needed by core and Application.
Let us dive into parallel processing of spring batch with examples of partitioning and parallel jobs.
2. Technologies Used
- Java 1.8.101 (1.8.x will do fine)
- Gradle 4.4.1 (4.x will do fine)
- IntelliJ Idea (Any Java IDE would work)
- Rest will be part of the Gradle configuration.
3. Spring Batch Project
Spring Boot Starters provides more than 30 starters to ease the dependency management for your project. The easiest way to generate a Spring Boot project is via Spring starter tool with the steps below:
- Navigate to https://start.spring.io/.
- Select Gradle Project with Java and Spring Boot version 2.0.1.
- Add Batch and HSqlDB in the “search for dependencies”.
- Enter the group name as
com.jcgand artifact asspringBatchParallel. - Click the Generate Project button.
A Gradle Project will be generated. If you prefer Maven, use Maven instead of Gradle before generating the project. Import the project into your Java IDE.
3.1 Gradle File
We will look at the generated gradle file for our project. It has detailed configuration outlining the compile time and run time dependencies for our project.
build.gradle
buildscript {
ext {
springBootVersion = '2.0.1.RELEASE'
}
repositories {
mavenCentral()
}
dependencies {
classpath("org.springframework.boot:spring-boot-gradle-plugin:${springBootVersion}")
}
}
apply plugin: 'java'
apply plugin: 'eclipse'
apply plugin: 'idea'
apply plugin: 'org.springframework.boot'
apply plugin: 'io.spring.dependency-management'
group = 'com.jcg'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = 1.8
repositories {
mavenCentral()
}
dependencies {
compile('org.springframework.boot:spring-boot-starter-batch')
runtime('org.hsqldb:hsqldb')
testCompile('org.springframework.boot:spring-boot-starter-test')
testCompile('org.springframework.batch:spring-batch-test')
}
- We have provided
Mavenas the repository for all our dependencies. - Idea plugin has been applied to support Idea IDE in line 15.
- Spring Boot Batch Starter dependency is applied to enable batch nature in our project.
- HSQL DB is provided as runtime dependency to save spring batch job status in embedded mode. Spring batch needs to track the job execution, results in a reliable manner to survive across job restarts and abnormal terminations. To ensure this, generally they are stored in the database but since our application does not use a persistent store, Hsql DB in embedded mode is utilized for the same.
- Lines 32,33 represent the test configuration.
4. Spring Batch Parallel Processing
We will look at an example of running multiple jobs parallelly. Here, jobs are independent of each other and finish execution in a parallel manner. Below we can look at the java configuration to enable parallel processing.
Spring Batch Parallel Flow Configuration
package com.jcg.springbatchparallel.config;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.job.builder.FlowBuilder;
import org.springframework.batch.core.job.flow.Flow;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.core.partition.support.MultiResourcePartitioner;
import org.springframework.batch.core.partition.support.Partitioner;
import org.springframework.batch.core.step.tasklet.TaskletStep;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.UrlResource;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.core.task.SimpleAsyncTaskExecutor;
import java.net.MalformedURLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.stream.IntStream;
@Configuration
@EnableBatchProcessing
public class BatchConfiguration {
Logger logger = LoggerFactory.getLogger(BatchConfiguration.class);
@Autowired
JobBuilderFactory jobBuilderFactory;
@Autowired
StepBuilderFactory stepBuilderFactory;
private TaskletStep taskletStep(String step) {
return stepBuilderFactory.get(step).tasklet((contribution, chunkContext) -> {
IntStream.range(1, 100).forEach(token -> logger.info("Step:" + step + " token:" + token));
return RepeatStatus.FINISHED;
}).build();
}
@Bean
public Job parallelStepsJob() {
Flow masterFlow = new FlowBuilder("masterFlow").start(taskletStep("step1")).build();
Flow flowJob1 = new FlowBuilder("flow1").start(taskletStep("step2")).build();
Flow flowJob2 = new FlowBuilder("flow2").start(taskletStep("step3")).build();
Flow flowJob3 = new FlowBuilder("flow3").start(taskletStep("step4")).build();
Flow slaveFlow = new FlowBuilder("slaveFlow")
.split(new SimpleAsyncTaskExecutor()).add(flowJob1, flowJob2, flowJob3).build();
return (jobBuilderFactory.get("parallelFlowJob")
.incrementer(new RunIdIncrementer())
.start(masterFlow)
.next(slaveFlow)
.build()).build();
}
}
- In Line 36, We have configured a simple
TaskletStep. The step includes aTaskletwhich iterates from numbers 1 to 100 and prints to the console. In the tasklet, we returnRepeatStatus.FINISHEDto indicate successful execution. - In Lines 56-76, We are parallelizing multiple jobs. For our example, each job is going to use the simple
Taskletwe configured earlier in line 36. - Masterflow is configured using
FlowBuilderand this holds theTaskletconfigured as step1.FlowBuilderis used to construct flow of steps that can be executed as a job or part of a job. Here, we are constructing a flow as part of our example. - We create three different Flow with reference to taskletsteps as step2, step3 and step4.
- A simple
SlaveFlowis configured to hold all three flow jobs. We configure theSlaveFlowwith aSimpleAsyncTaskExecutorthat executes multiple threads parallelly. We have not defined a thread pool, soSpringwill keep spawning threads to match the jobs provided. This ensures the parallel execution of jobs configured. There are multipleTaskExecutorimplementations available, butAsyncTaskExecutorensures that the tasks are executed in parallel.AsyncTaskExecutorhas aconcurrencyLimitproperty which can be used to throttle the number of threads executing parallelly. - We build a job which starts with masterflow and then
SlaveFlow. The entire configuration creates aFlowJobBuilderfrom which we can create a Job. - Spring Batch Infrastructure will run the job when the application is started.
Let us dive ahead and run the code in our Java IDE to observe the results.
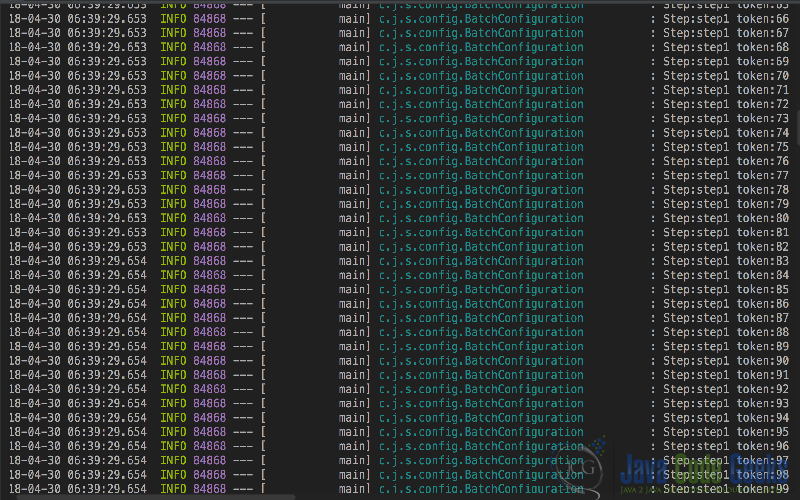
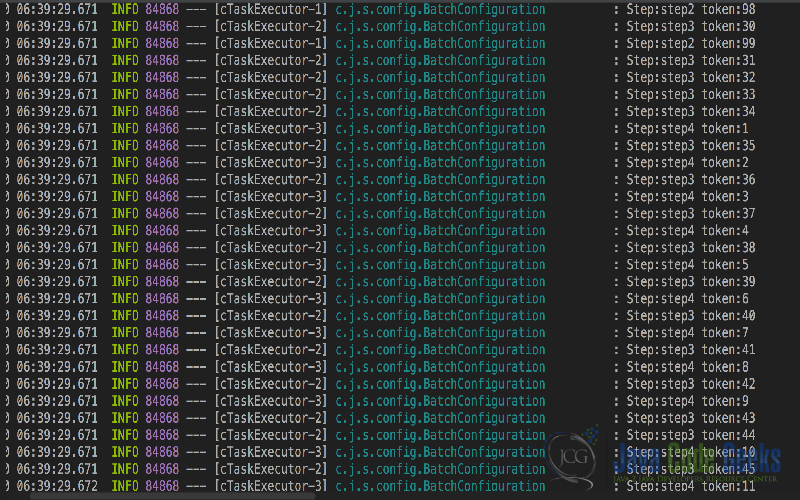
- We can observe that MasterStep has completed execution sequentially.
- Next we see the parallelization happening between the steps Step2, Step3 and Step4.
- All the Jobs part of
SlaveFloware running in parallel. - We have configured three jobs for parallel execution and dual core machines will produce the effect similar to the logs above.
Use case above is used in places where a set of jobs are dependent on an initial job for completion after which they can be completely parallelized. An initial job can be a tasklet doing minimal processing to provide a baseline while the slave jobs execute the actual logic in parallel. Spring batch waits for all the jobs in SlaveFlow to provide aggregated exit status.

5. Spring Batch Partitioning
There is another use case of parallel processing in Spring which is via partitioning. Let us consider the scenario with the example of a huge file. Multiple threads reading the same file will not ensure increased performance as the I/O resource is still one and may even lead to performance degradation. In such cases, we split a single file into multiple files and each file can be processed in the same thread. In our example, a single file person.txt containing 50 records has been split into 10 files each containing 5 records. This can be achieved by using the split command
split -l 5 person.txt person
The above command creates files with names like personaa, personab etc. We will then configure Spring Batch to process these files parallelly for faster execution. Below is the batch configuration for the same.
Spring Batch Partitioning Configuration
@Bean
public Job partitioningJob() throws Exception {
return jobBuilderFactory.get("parallelJob")
.incrementer(new RunIdIncrementer())
.flow(masterStep())
.end()
.build();
}
@Bean
public Step masterStep() throws Exception {
return stepBuilderFactory.get("masterStep")
.partitioner(slaveStep())
.partitioner("partition", partitioner())
.gridSize(10)
.taskExecutor(new SimpleAsyncTaskExecutor())
.build();
}
@Bean
public Partitioner partitioner() throws Exception {
MultiResourcePartitioner partitioner = new MultiResourcePartitioner();
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
partitioner.setResources(resolver.getResources("file://persona*"));
return partitioner;
}
@Bean
public Step slaveStep() throws Exception {
return stepBuilderFactory.get("slaveStep")
.<Map<String, String>, Map<String, String>>chunk(1)
.reader(reader(null))
.writer(writer())
.build();
}
@Bean
@StepScope
public FlatFileItemReader<Map<String, String>> reader(@Value("#{stepExecutionContext['fileName']}") String file) throws MalformedURLException {
FlatFileItemReader<Map<String, String>> reader = new FlatFileItemReader<>();
reader.setResource(new UrlResource(file));
DefaultLineMapper<Map<String, String>> lineMapper = new DefaultLineMapper<>();
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer(":");
tokenizer.setNames("key", "value");
lineMapper.setFieldSetMapper((fieldSet) -> {
Map<String, String> map = new LinkedHashMap<>();
map.put(fieldSet.readString("key"), fieldSet.readString("value"));
return map;
});
lineMapper.setLineTokenizer(tokenizer);
reader.setLineMapper(lineMapper);
return reader;
}
@Bean
public ItemWriter<Map<String, String>> writer() {
return (items) -> items.forEach(item -> {
item.entrySet().forEach(entry -> {
logger.info("key->[" + entry.getKey() + "] Value ->[" + entry.getValue() + "]");
});
});
}
- We are creating a
JobparallelJob with a singleStepmasterStep. - MasterStep has two Partitioners – one provides the data as partitions, while another handles the partitioned data.
MultiResourcePartitioneris used to provide the partitioned data. It looks for files in the current directory starting withpersonaand returns each file as a separate partition.- Each partition contains a
StepExecutionContextwith filename stored in the keyfileName. gridSizeis used to specify an estimate for the number of partitions to be created but number of partitions can exceedgridSizealso.- Each partition is then fed into slaveStep which has a reader and writer.
chunkSizeis provided as 1 to ensure writer gets called after every record is read. Ideally, it would be better to specify a larger number as chunk of records will get processed on each pass.- In our example, we have used
FlatFileReaderwith the filename provided by thePartitioner. Our file is split by : which has just a key and value. Each line is read and fed to our customlineMapperwritten inline as lambda function.LineMappertransforms the read tokens into aMapwith key and value. - This chunk of lines is fed into our custom writer which is another anonymous class implementation. Our custom writer iterates through the chunk of maps fed into it and logs out the key/value pair.
- We have specified the executor as
AsyncTaskExecutorwhich starts creating number of threads equal to number of partitions. If the number of threads exceed OS cores, context switching will happen and there will be concurrency.
Below is the output of running the parallelJob.
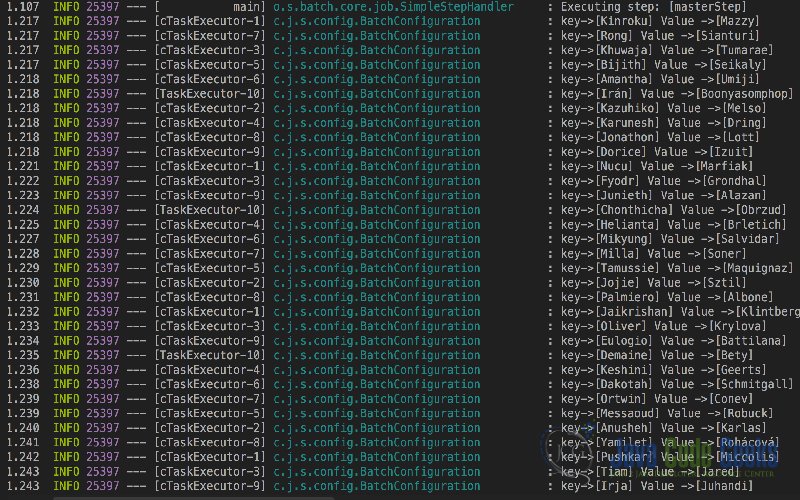
We can clearly see the task executor context switching as each task executor concurrently logs people names.
6. Summary
In this example, we have demonstrated parallel processing features of Spring Batch. We saw two approaches to parallel processing with Spring Batch. Partitioning has seen widespread use in many of the applications. The former is parallelizing multiple jobs, while partitioning is parallelizing a single job. Both have its own use in applications.
7. Download the Source Code
You can download the full source code of this example here: Spring Batch Parallel Processing

if i want transaction management for this. like parallel there are 2 steps are running and if one fails then the transaction committed in the other should get roll back.
Please help how to implement transaction management in this.
There is no straightforward way as per my knowledge. You need to use afterJob to coordinate these kind of scenarios. Basically in each afterstep signal completion and if one fails rollback the steps . Also it depends on the step configuration etc.
Hi, thanks for this helpfull tutorial. Please i want to know how to Launch this application.
If you are using IDE,Import the project as Gradle Project and run the main class SpringBatchParallelApplication.java
Else use gradle to assemble the jar and run the jar with main class option
Read a pipe delimiter file with 20 million data, perform mapping processing and write output to another flat file in the least time could you please suggest, will spring batch will work