In this example of Solr Zookeeper, we will discuss about how to use the Zookeeper embedded with Solr for performing the distributed search. Solr provides the Sharding option to distribute the Index across multiple servers. Zookeeper helps us in performing the distributed search and retrieve the resultset as if the query was performed on a single server. In this example, we will show you how to set up the Zookeeper and also show how distributed search works.
To demonstrate the Solr Zookeeper Example, we will install Solr and also create another copy of Solr. Our preferred environment for this example is Windows with solr-5.3.0. Before you begin the Solr installation make sure you have JDK installed and Java_Home is set appropriately.
1. Install Apache Solr
To begin with, lets download the latest version of Apache Solr from the following location:
http://lucene.apache.org/solr/downloads.html
In this example we will run two Solr servers, so we need two instances of Solr. Now make a folder called node1 and extract the zip file. Once the Solr zip file is downloaded, unzip it into a folder. The extracted folder will look like the below:
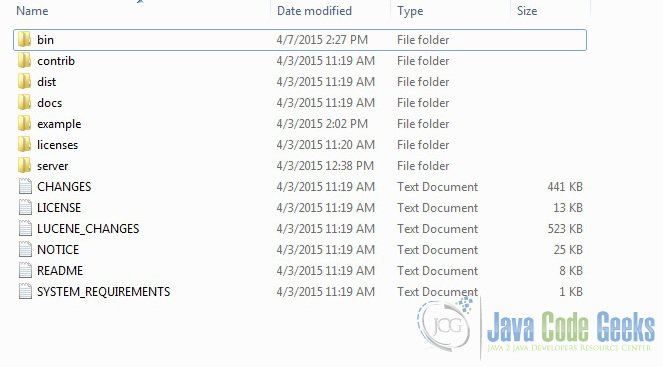
The bin folder contains the scripts to start and stop the server. The example folder contains few example files. We will be using one of them to demonstrate how Solr indexes the data. The server folder contains the logs folder where all the Solr logs are written. It will be helpful to check the logs for any error during indexing. The solr folder under server holds different collection or core. The configuration and data for each of the core/ collection are stored in the respective core/ collection folder.
Apache Solr comes with an inbuilt Jetty server. But before we start the solr instance we must validate the JAVA_HOME is set on the machine.
Now make another copy of Solr under the folder node2. You could copy the already extracted version of solr-5.3.0 folder or unzip the downloaded file again under node2.
2. Configuring Solr with Zookeeper
In this example we will use the embedded zookeeper that comes along with Solr. We can start the server using the command line script. Lets go to the bin directory from the command prompt and issue the following command:
solr start -c
The -c option will start the Solr in the SolrCloud mode which will also launch the embedded ZooKeeper instance included with Solr. If we want to use already running ZooKeeper then we have to pass the -z parameter which we will see when we start the second node.
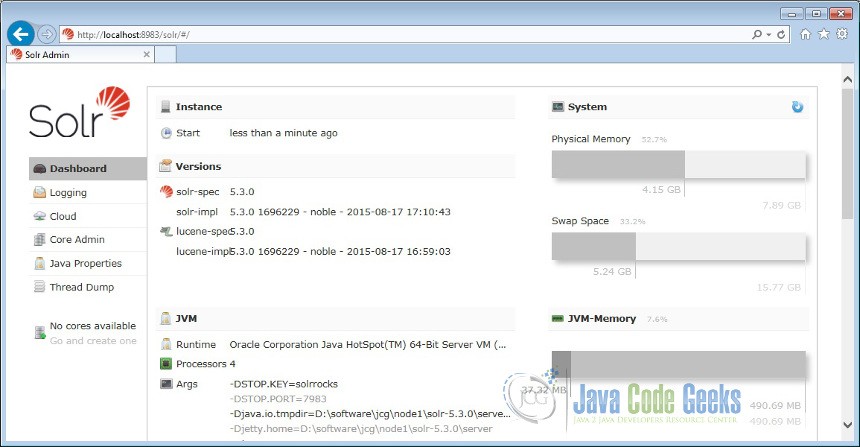
Now lets open the following URL and see the solr is running.
http://localhost:8983/solr/#/
Now navigate to the second node, \node2\solr-5.3.0\bin from the command prompt and issue the following command.
solr start -c -p 7574 -z localhost:9983
Here, we again start with the -c option but instead of starting another embedded ZooKeeper we will use the ZooKeeper started part of node 1. Note, we have used the -z parameter and given the value as localhost:9893 the ZooKeeper for the node 1. The ZooKeeper of node 1 was started with default port which is 1000 added to the default port of Solr (8983).
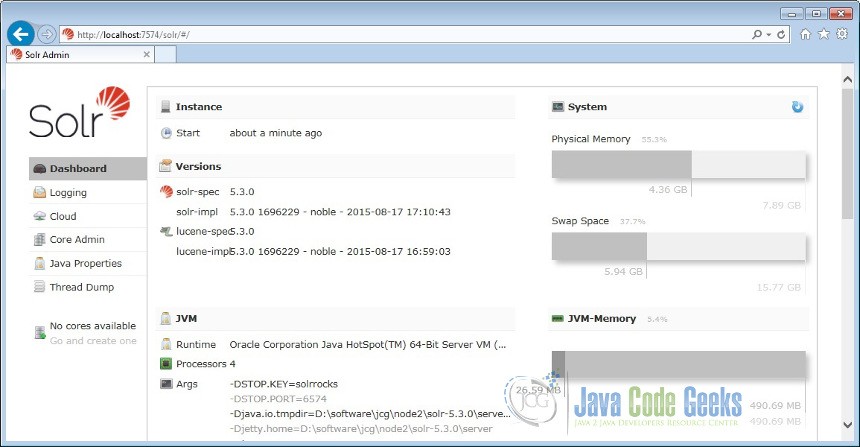
Now lets open the following URL to validate the Solr is running in node 2.
http://localhost:7574/solr/#/
3. Create Collection
In this section, we will show you how to configure the core/collection for a solr instances and how to index the data across different nodes. Apache Solr ships with an option called Schemaless mode. This option allow users to construct effective schema without manually editing the schema file.
First, we need to create a Core for indexing the data. The Solr create command has the following options:
- -c <name> – Name of the core or collection to create (required).
- -d <confdir> – The configuration directory, useful in the SolrCloud mode.
- -n <configName> – The configuration name. This defaults to the same name as the core or collection.
- -p <port> – Port of a local Solr instance to send the create command to; by default the script tries to detect the port by looking for running Solr instances.
- -s <shards> – Number of shards to split a collection into, default is 1.
- -rf <replicas> – Number of copies of each document in the collection. The default is 1.
In this example we will use the -c parameter for collection name, -s parameter for defining the number of Shards and -d parameter for the configuration directory. For all other parameters we make use of default settings.
Now navigate the bin folder of node 1 in the command window and issue the following command:
solr create -c jcg -d data_driven_schema_configs -s 2
We will use jcg as the collection name and use the data_driven_schema_configs for the schemaless mode. Also note, we have passed the value 2 for -s parameter for creating two shards.
We can see the following output in the command window.
Connecting to ZooKeeper at localhost:9983 ...
Uploading D:\software\jcg\node1\solr-5.3.0\server\solr\configsets\data_driven_sc
hema_configs\conf for config jcg to ZooKeeper at localhost:9983Creating new collection 'jcg' using command:
http://localhost:8983/solr/admin/collections?action=CREATE&name=jcg&numShards=2&
replicationFactor=1&maxShardsPerNode=1&collection.configName=jcg{
"responseHeader":{
"status":0,
"QTime":10801},
"success":{"":{
"responseHeader":{
"status":0,
"QTime":7143},
"core":"jcg_shard1_replica1"}}}Now we navigate to the following URL and we can see jcg collection being populated in the core selector. You can also see other configurations configurations listed.

http://localhost:8983/solr/#/
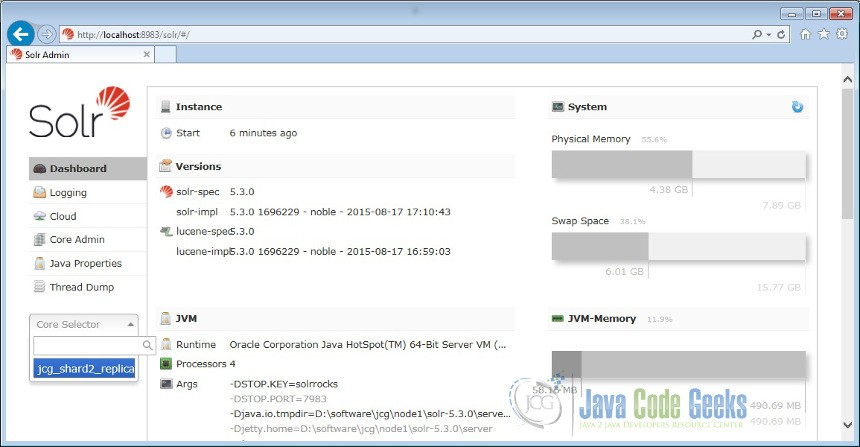
Now click on the Cloud icon in the left navigation bar. You can notice the two shards are active and running in different ports on the same machine.
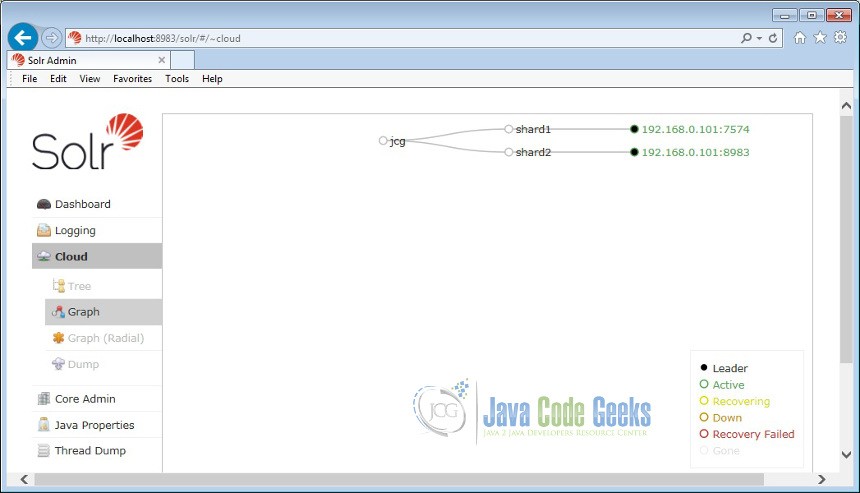
4. Indexing the Data
Apache Solr comes with a Standalone Java program called the SimplePostTool. This program is packaged into JAR and available with the installation under the folder example\exampledocs.
Now we navigate to the \solr-5.3.0\example\exampledocs folder in the command prompt and type the following command. You will see a bunch of options to use the tool.
java -jar post.jar -h
The usage format in general is as follows:
Usage: java [SystemProperties] -jar post.jar [-h|-] [<file|folder|url|arg> [<file|folder|url|arg>...]]
As we said earlier, we will index the data present in the “books.csv” file shipped with Solr installation. We will navigate to the solr-5.3.0\example\exampledocs in the command prompt and issue the following command.
java -Dtype=text/csv -Durl=http://localhost:8983/solr/jcg/update -jar post.jar books.csv
The SystemProperties used here are:
- -Dtype – the type of the data file.
- -Durl – URL for the jcg core.
The file “books.csv” will now be indexed and the command prompt will display the following output.
SimplePostTool version 5.0.0 Posting files to [base] url http://localhost:8983/solr/jcg/update using content- type text/csv... POSTing file books.csv to [base] 1 files indexed. COMMITting Solr index changes to http://localhost:8983/solr/jcg/update... Time spent: 0:00:00.647
5. Query the data
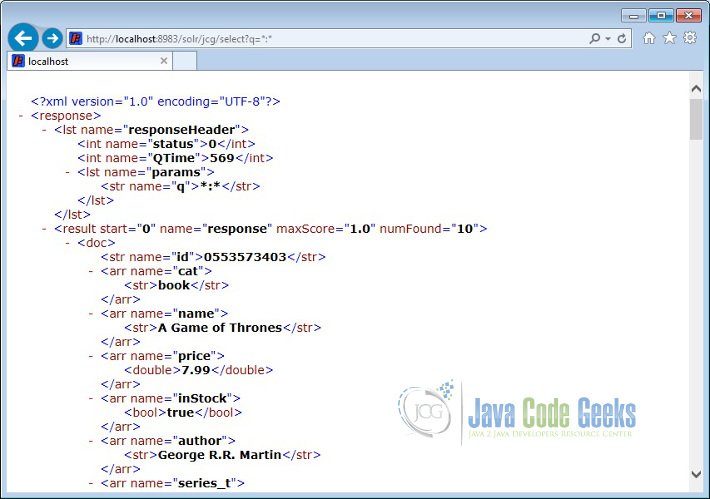
Now let’s query the data using the following URL. It will bring all the data spread across different shards.
http://localhost:8983/solr/jcg/select?q=*:*
Similarly, open the following URL. The result set will be the same as ZooKeeper does the distributed search across all the Shards.
http://localhost:7574/solr/jcg/select?q=*:*
The ZooKeeper will split the indexing equally across the different Shards. To validate it, lets query the data present in one of the Shards.
http://localhost:8983/solr/jcg/select?q=*:*&shards=localhost:7574/solr/jcg
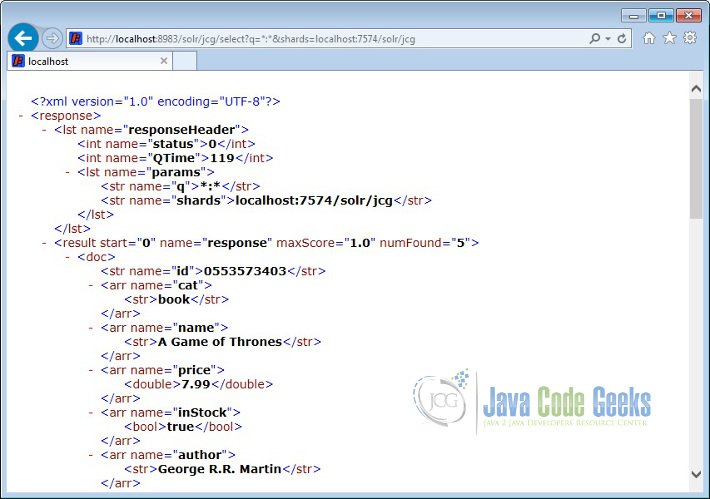
You can notice that only 5 records are returned as part of this query.
6. Conclusion
This was an example of Apache Solr integration with ZooKeeper. With example, we have seen how Zookeeper helps us in performing the distributed search and retrieve the resultset as if the query was performed on a single server.
