In this example, we will learn about Oozie which is a Hadoop Ecosystem Framework to help automate the process of work scheduling on Hadoop clusters.
1. Introduction
Apache Oozie is an open-source project which is the part of the Hadoop Ecosystem. It is used to create the workflow and automate the process of different job and task scheduling depending on these workflows. From the Apache Hadoop ecosystem, Oozie is designed to work seamlessly with Apache Hadoop MapReduce jobs, Hive, Pig, Sqoop and simple java jars.
There are three type of Oozie jobs:
- Oozie Workflow Jobs: Represented as directed acyclical graphs to specify a sequence of actions to be executed.
- Oozie Coordinator Jobs: Oozie workflow jobs that are triggered by time and data availability.
- Oozie Bundle: Oozie bundle is the packaging manager which handles packaging of multiple coordinator and workflow jobs, and makes it easier to manage the life cycle of those jobs.
2. Oozie Workflow
In this section we will understand the workflow of Oozie in general theoretical terms:
2.1 General Workflow
Ooze workflow is the directed acyclic graph (DAG) which contains the arrangement of the actions to be performed and the conditions on which these actions need to be performed.
There are two types of nodes in the DAG graph:
- Control Nodes: Control nodes as the name says, defines how the jobs are controlled. It define the job chronology, defines the rules for starting and ending a workflow and controls the overall execution path of the jobs based on different rules.
- Action Nodes: Action nodes are the one which performs the main action, they trigger the execution of the jobs be it MapReduce jobs, Pig or Hive jobs, Java application etc.
Oozie is responsible for executing the workflow actions, once these actions are triggered the actual jobs related to these actions are executed by the Hadoop MapReduce framework. This way it is possible to take advantage of the existing load-balancing and availability of the Hadoop cluster.
When Oozie starts a task, it provides a unique callback URL to the particular task and when the task is completed, this callback URL is notified, this way Oozie can track the completion of tasks and in case this callback URL is not invoked, task can be polled again for execution.
2.2 Data Application Pipeline
All the workflow in Oozie is defined in a chain of events which is called data application pipeline. In data application pipeline, Oozie Coordinator Jobs allow the user to define workflow triggers to be executed in the terms of data(if a specific data is present), time(for recurring jobs) or event predicates(if a job need to be started after the execution of another jobs with taking first jobs output data as input to this job). Workflow jobs are executes based on these triggers and when these triggers are satisfied.
Data Application Pipeline is defined in an XML-based language called Hadoop Process Definition Language. Once this workflow is defined, Oozie workflow jobs can be submitted using the command line provided by Hadoop Oozie. Once this job is submitted to the Oozie server, job as well as the execution states will be stored in an RDBMS on the Oozie server.
3. Understanding Workflow XML File
In this section, we will check an example of the Oozie workflow which is written as an XML file. In the sample Oozie workflow file we will have a chain of jobs to be executed. The first job will be the data ingestion job which will be performed first thing in the DAG graph. Followed by the merge operations, here we will define two merge jobs which will merge two different type of data after the ingestion job and finally the chain end with the successful merge of the data.
<workflow-app xmlns='uri:oozie:workflow:0.1' name='ExampleWorkflow'>
<start to='data-ingestor'/>
<action name='data-ingestor'>
<java>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>default</value>
</property>
</configuration>
</java>
<ok to='merge-controller'/>
<error to='fail'/>
</action>
<fork name='merge-controller'>
<path start='merge-task1'/>
<path start='merge-task2'/>
</fork>
<action name='merge-task1'>
<java>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>default</value>
</property>
</configuration>
<arg>-drive</arg>
<arg>${driveID}</arg>
<arg>-type</arg>
<arg>Type1</arg>
</java>
<ok to='completed'/>
<error to='fail'/>
</action>
<action name='merge-task2'>
<java>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>default</value>
</property>
</configuration>
<main-class>com.navteq.assetmgmt.hdfs.merge.MergerLoader</main-class>
<arg>-drive</arg>
<arg>${driveID}</arg>
<arg>-type</arg>
<arg>Type2</arg>
</java>
<ok to='completed'/>
<error to='fail'/>
</action>
<join name='completed' to='end'/>
<kill name='fail'>
<message>Failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name='end'/>
</workflow-app>
In this workflow DAG file of Hadoop Oozie we have three actions:
- Data-ingestion
- Merge Task 1
- Merge-Task 2
and we have one fork node which defines that the data after ingestion will be divided into two merge tasks based on the type of data.
Lets see how the workflow goes:
- Line 2: Declares that the workflow starts with performing the action named
data-ingestor. - Line 3-16: Defines the action
data-ingestorimmediately after the start declaration. It defines a Hadoop MapReduce job to be performed and also associated properties. Line no. 14 and 15 defines the next actions to be followed after the execution of the job. If the job is executed successfully then theokdeclaration is followed which declares that the next action to be performed is namedmerge-controllerand if the job produces and error then action namedfailsneed to be executed. - Line 17-20: defines the next fork action, which declares the next task is forked into two jobs namely
merge-task1andmerge-task2which are declared immediately next and which task will take which data will also be declared in the tasks itself. - Line 21-38: Defines the next action block which defines the
merge-task1job with the corresponding properties. Note in line 33 and 34, an argument is defined which tells the job that it takes the data of the typeType 1only. Similar to the first job, this also defines an ok and an error action to be performed if needed. On successful execution of the job, action block by the namecompletedwill be called and on errorfailwill be executed. - Line 39-57: Similar to the above action, it also defines the Hadoop MapReduce job to be executed and the argument defines that only the data of the type
Type 2will be executed by this MapReduce job. This job also after the successful completion goes tocompletedor tofailin case of any error. - Line 58: Defines the
completedblock, which is the join block, it tells the workflow that the data result from the forked tasks which comes to this action block i.e.merge-task1andmerge-task2will be joined here. On successful join, the workflows moves to the next block which isendas declared in thejoinblock. - Line 59-61: Defines the
killblock which will be executed in case any error arises in any of the jobs. It kills the workflow and prints out the message mentioned in the block. - Line 62: It is the
endblock which declares that this is the end of the DAG workflow and the Hadoop Oozie job is finished now.
This is the simple example of how Hadoop Oozie works in defining the workflow for the execution of different Hadoop MapReduce Jobs in chain.
4. Hadoop Oozie Example
Many examples are bundled with the Oozie distribution which you might have downloaded and installed. Examples should be in the tar file oozie-examples.tar.gz file. Once you extract this it will create an examples/ directory which will contain three directories by the name apps, input-data and src. All the examples are in the folder apps
So to run the examples, we need to follow these steps:
-
The
examples/directory should be unloaded to HDFS first of all. Following command can be used for doing so:hadoop fs -put examples examples
- We will use the map-reduce job example which is located in
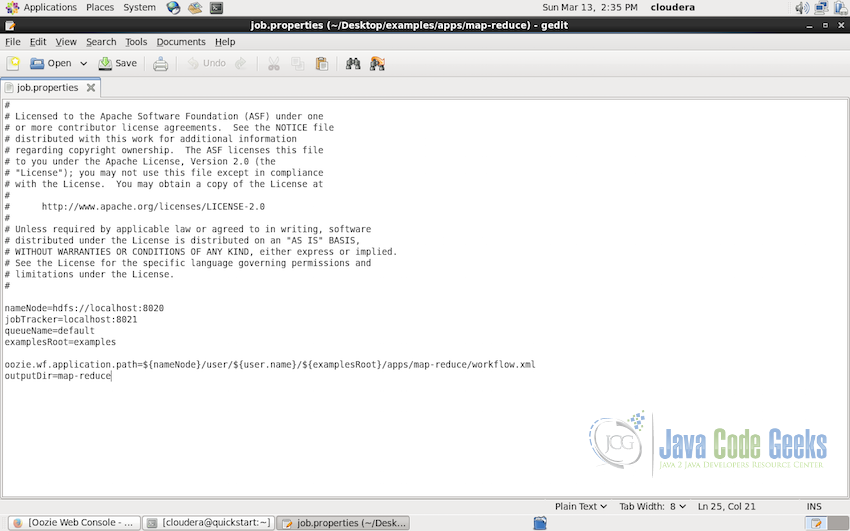
examples/apps/map-reducedirectory. It contains ajob.propertiesfile which contains all the job related proeprties as shown below:

job.properties file - Same directory also contains another file
workflow.xmlwhich is the actual workflow DAG file.
Workflow.xml file - So now once we have the examples directory in HDFS, we are ready to submit the example Oozie job. Use the following command to submit the job to the Oozie server.
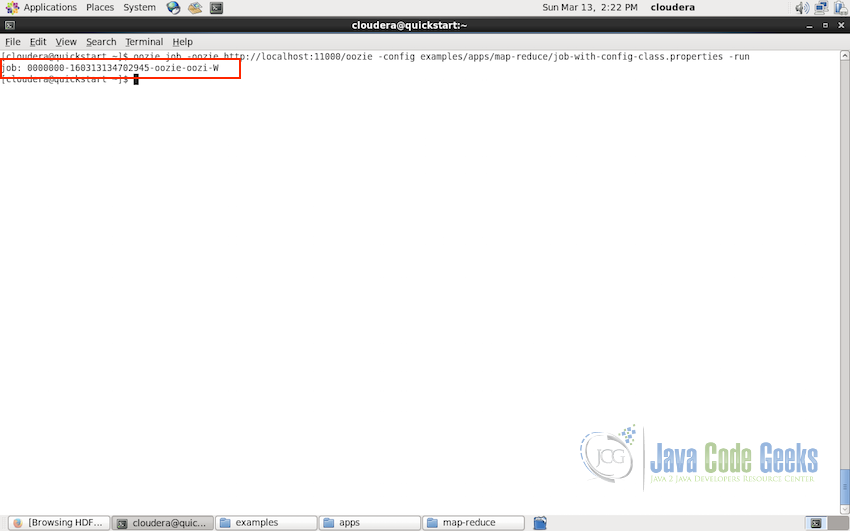
oozie job -oozie http://localhost:11000/oozie -config examples/apps/map-reduce7job.properties -run
Once you run this command, after the successful submission of the job, Oozie will return a job id which we can use for checking the job information.
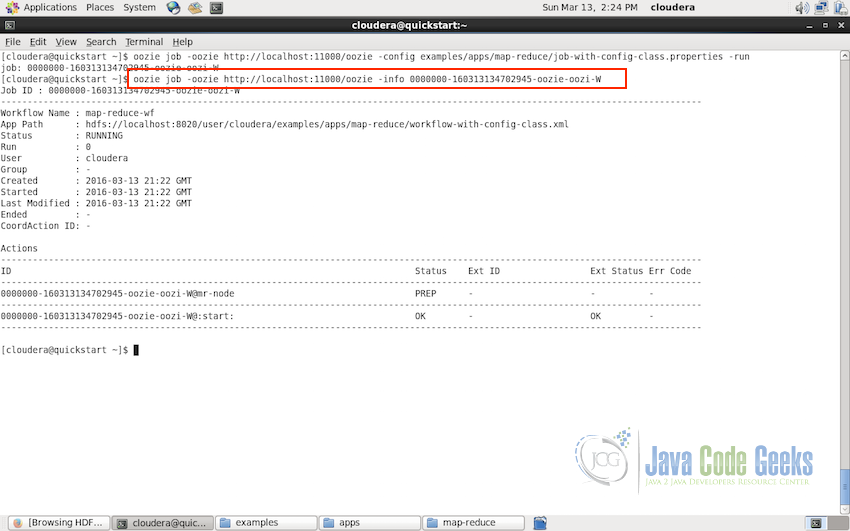
Oozie job submission - Now as we have a job id corresponding to the job we submitted, we can check the status of the workflow job using the following command
oozie job -oozie http://localhost:11000/oozie -info {JOB_ID_FROM_LAST_COMMAND}Following screenshot shows the output of theworkflow job status command:
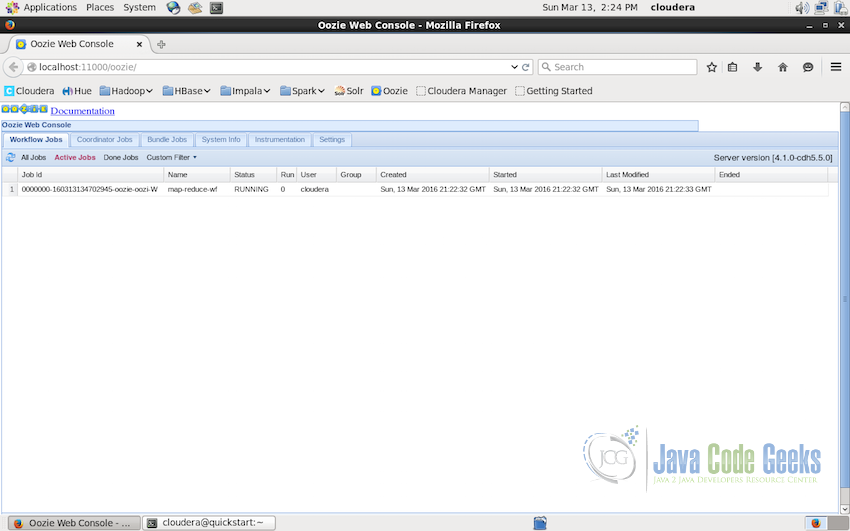
Workflow job status output - The workflow status can also be checked on the web interface of Hadoop Oozie at
http://localhost:11000/oozie. The interface list all the jobs. We will see only one job as we have submitted only one till now:
Oozie web interface with the submitted job - We can use the web interface for check other details of the submitted job also. For example:
Detailed Job Inforamtion
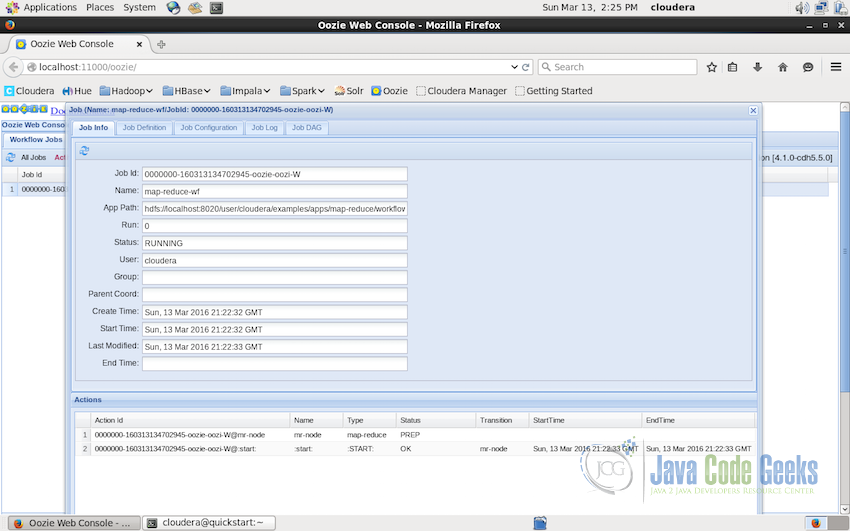
Job Information
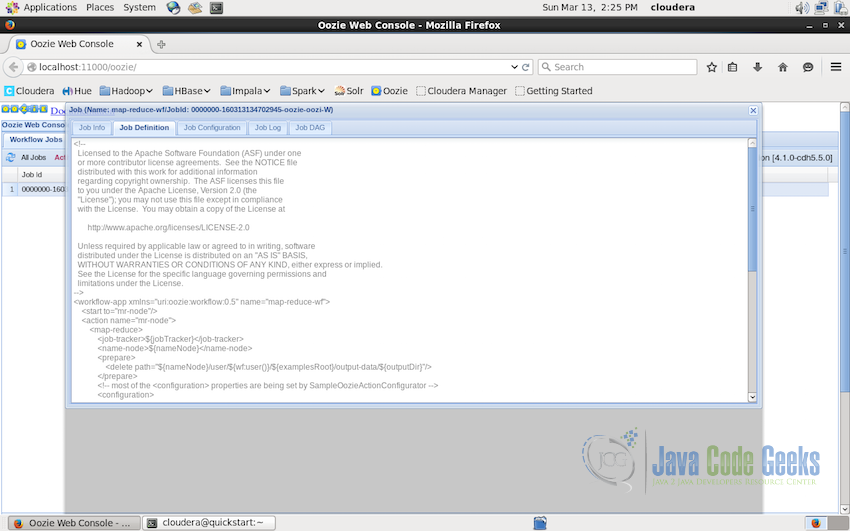
Job Definition: which will show the complete workflow of the DAG graph
Job Definition
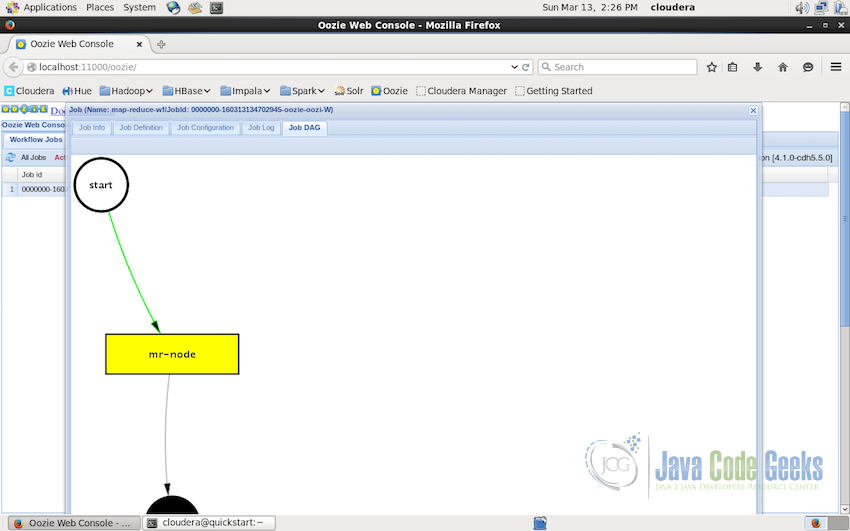
Job DAG Graph: Web interface also displays the visualization of the DAG graph generated from the workflow XML file. For this example job we have a quite simple graph but the actual production graph can do a lot complex.
DAG Graph Visualization


This brings us to the end of this section where we saw hands on example of the sequence of submission and tracking the status of the Oozie job both in console as well as in web-interface.
5. Conclusion
This example introduces the Hadoop Oozie library with an example of the workflow. Hadoop Oozie is very useful library of the Hadoop Ecosystem in real world projects and practices. It provides a tool for the chaining and the automation of the different kinds of Hadoop Ecosystem jobs and makes the task quite easy and hassle free compared to if the complex chains of jobs need to be executed one after the other. In this article, we started with the introduction of Hadoop Oozie followed by the simple workflow and introduction to the data processing pipeline. Finally we saw the working of Oozie with an example dummy workflow.
6. Download the Workflow XML file
This was the example of Hadoop Oozie with the dummy workflow file for executing three Hadoop MapReduce jobs in the chain. This dummy workflow file can be downloaded for reference from below:
You can download the XML file used in this example here: ExampleWorkflow
