In this tutorial, we will learn about Hue. This will be the basic tutorial to start understanding what Hue is and how it can be used in the Hadoop and Big Data Ecosystem.
1. Introduction
First of all, let us look into what is Hue?
Hue is an open source Web interface for analyzing data with any Apache Hadoop based framework or Hadoop Ecosystem applications. Hue basically provides interfaces and UI to interact with Hadoop Distributed File System(HDFS), MapReduce applications, Oozie workflows, Hive and Impala queries etc. So basically Hue is a Web UI which makes it easy to use Hadoop ecosystem easier to use without interacting with command line prompt for most of the common activities. Hue is developed and open sources by Cloudera.
2. Features
Hue provides a lot of features and web interfaces for quite a number of services some of which are following:
- HDFS File Browser
- Job designer and browser
- Hadoop API access
- Access to Hadoop Shell
- User Admin
- Hive query editor
- Pig query editor
- Oozie interface for workflows
- Interface for SOLR searches
This is the reason why hue is used a lot in Hadoop Cluster installations, it combines almost all the basic required functions and makes it easy to use for people who are not well versed with the command line tools of each of these services.
In the following sections, we will go through some of the most important function in details.
3. HDFS Browser
Being able to access, browser and interact with the files in Hadoop Distributed File System is one of the most important factors while working with any component of the Hadoop Ecosystem. Hue provides a user interface for this and this interface is capable of performing all the required tasks. This interface is quite handy when you do not feel like working with the command line.
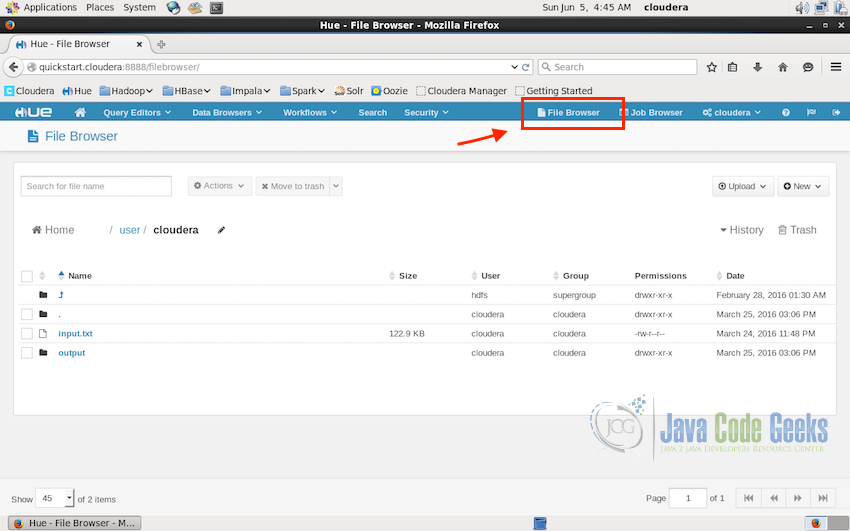
In hue interface, click on the “File Browser” on the top-right of the web interface, this will open the file browser and will list all the available files. In the screenshot below, we are on the path /user/cloudera and it list all the files in the folder along with other properties of the files. We can delete files, upload new files and download files directly from this interface.
4. Job Browser
Next in the tutorial is the Job Browser, at times we need to know what jobs are currently running on the Hadoop cluster, which past jobs were successful or failed due to some error. Job Browser interface of Hue comes handy in such times. Job Browser is can be accessed using the button just next to File Browser on the top-right of the UI.
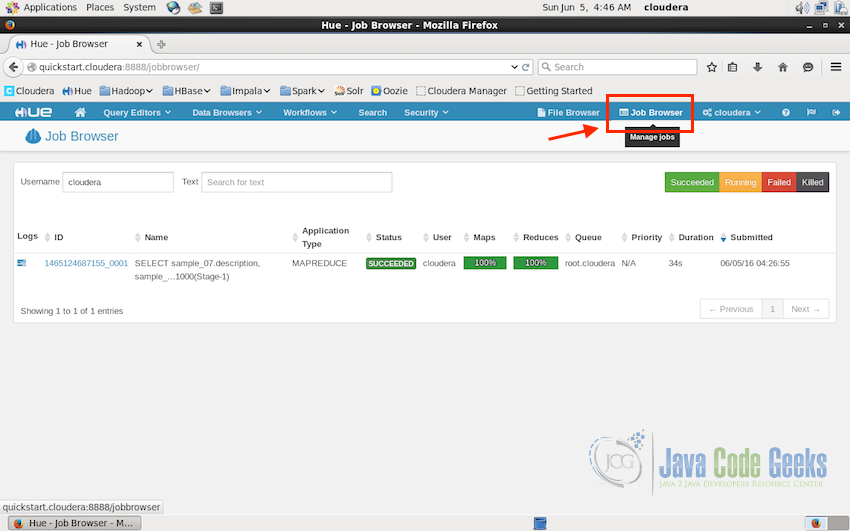
In the screenshot above, it shows one past MapReduce type job which was finished successfully. It also shows other properties of the job like ID, Name, Application Type, Status, Duration, Time of Submission and the User who submitted the job.
Four color code shows the types of status:
- Green for successful.
- Yellow for currently running jobs.
- Red for failed jobs.
- Black for the jobs which are manually killed by the user.
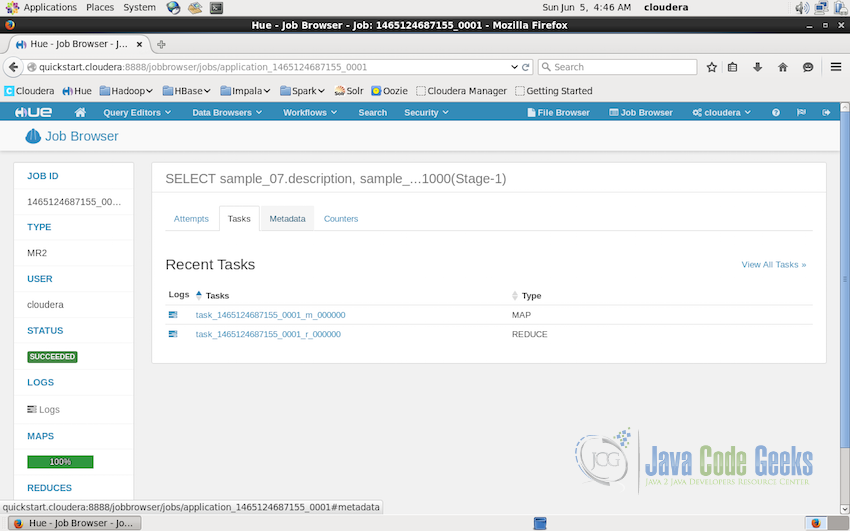
We can also have a look at more details regarding the job by simply clicking on the ID of the job. Clicking on the ID brings us to the job details UI, where it lists the tasks performed for the job. For example, in the screenshot, it shows two tasks were performed for this query, one Map and one Reduce, we can check the details of these tasks also by clicking on the ID of the tasks.
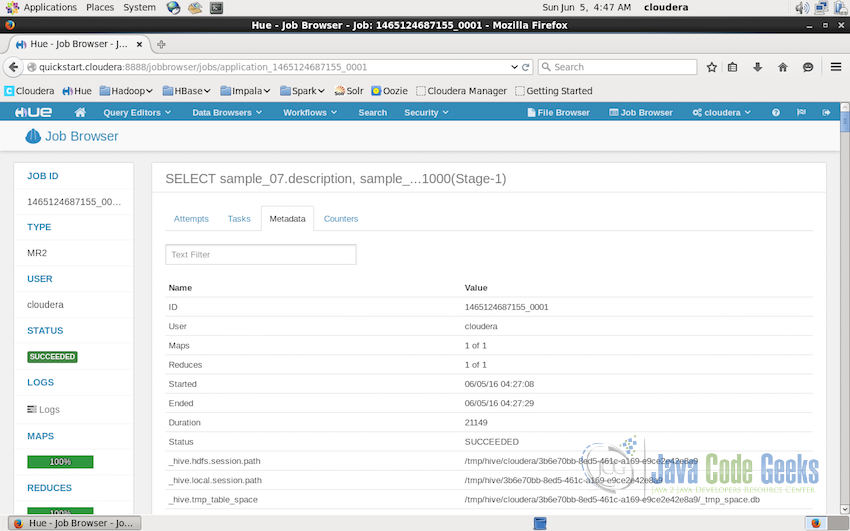
Other properties related to the particular job includes the metadata of the job as shown in the screenshot below. It contains the number of map and reduce tasks, then it was started, ended and the total duration of execution, user who submitted the job and other temporaty storage paths like session path, table space etc.
5. Hive Query Editor
Next we will have a look at the Query Editor and Hive Editor specifically. Hive editor allow us to write queries and to check results and the charts in the single interface making querying data quite easy for quick analysis.
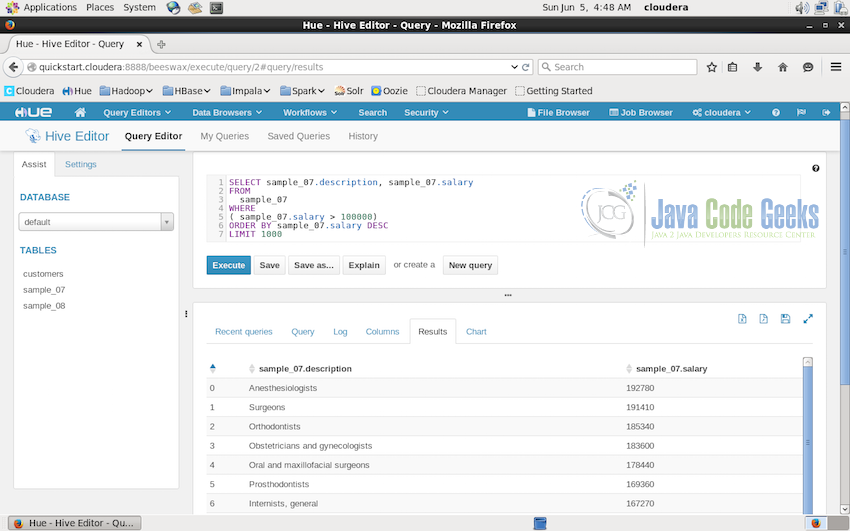
In the screenshot above, writing query in the editor and executing the query automatically creates a MapReduce job to process the data in the sample, this job can be checked in the job browser when it is running. Below the query shows the result of the query once it is processed.
Result of this query can easily be visualized also in the same Hive Editor Interface. The screenshot below shows the result in the bar chart format.
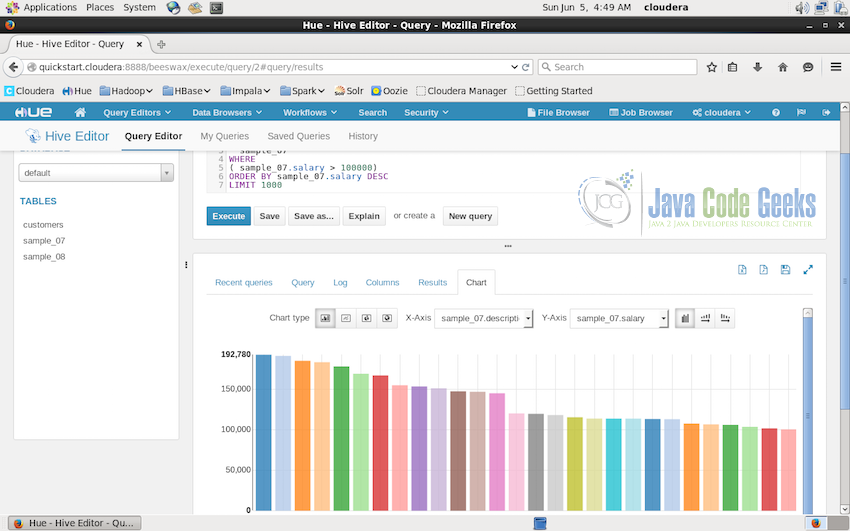
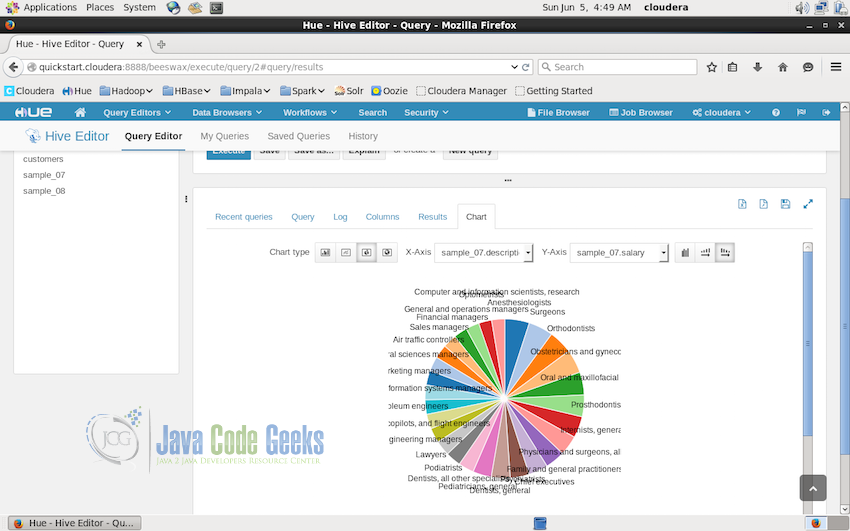
Charts displayed from the result can be easily exported or saved to the disk for record. Bar chart is not the only option available, different types of charts can be created from the same result. The screenshot below shows the pie chart of the same result date.

6. Database Browsers
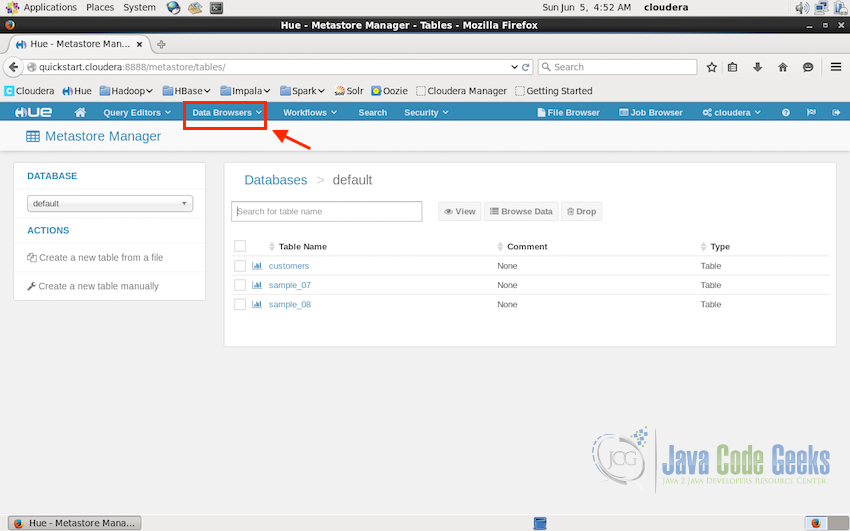
Metastore Manager in the Data Browser can be used to display all the available datastore tables, importing or exporting data etc.
The screenshot below shows three metastore tables which are the sample tables for the tutorial. We can view the tables, browser its data from this interface.
Clicking on the table “sample_07” opens up the details about the table where we can see the columns, sample data from the table(shown in the screenshot below) and properties of the table.
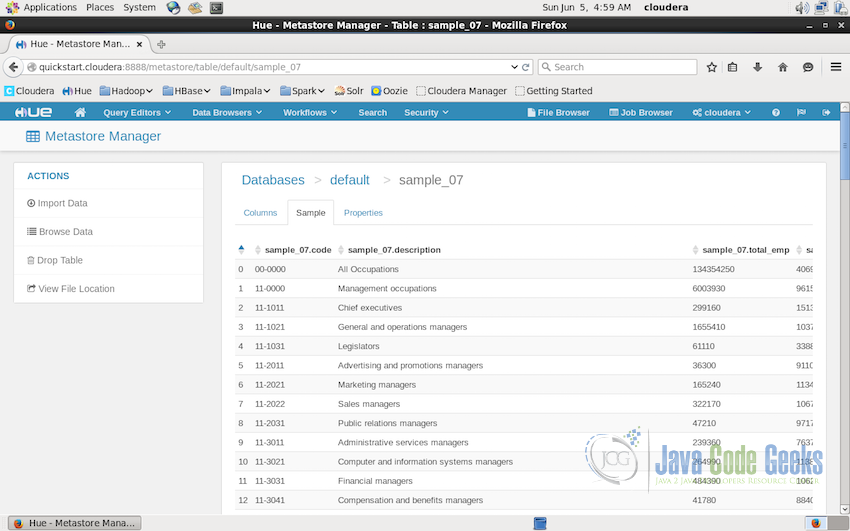
This is the interface where we can import data into the metastore, browse through the data, have a look at the actual file location corresponding to this table in the file system etc.
7. Oozie workflows
Oozie workflows are another set of interfaces provided by Hue. Here we can have a look at all the past and current oozie workflows present on the Hadoop Cluster.
Similar to the Job Browser, Oozie also displays the status of the workflows using three color code:
- Green for successful.
- Yellow for currently running jobs.
- Red for failed jobs.
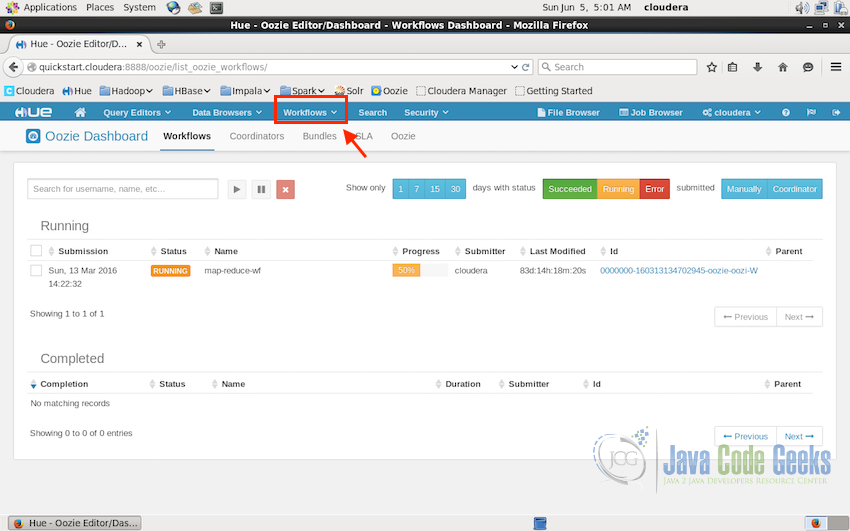
Screenshot below displays an Oozie workflow names “map-reduce-wf” which was submitted on 13th of March 2016 and is running from 83 days. It shows the status to be still running with the yellow label.
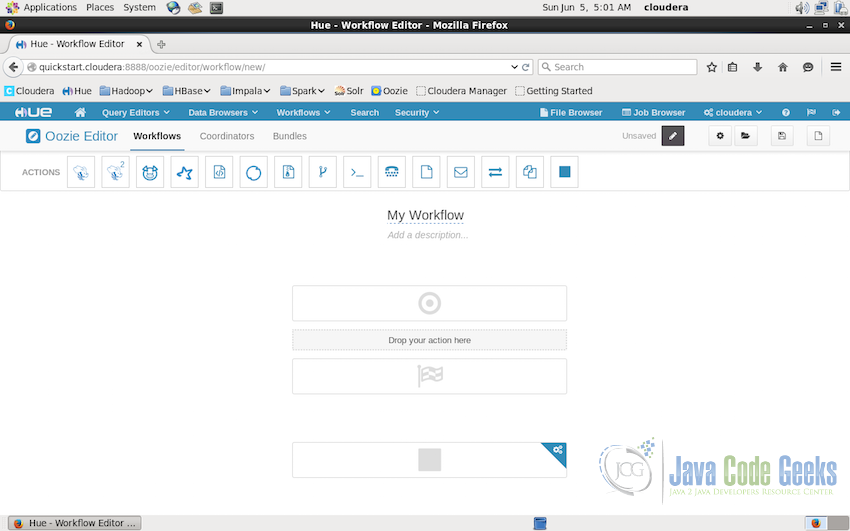
Besides the dashboard, Oozie interface also allow us to design the new workflows in the interface itself. Hue provides an inbuilt Oozie Editor. Where we can create new workflows using drag-drop interface. Oozie provides a lot of action which can be added to the workflow. For example, Hive queries, Pig Queries, Spark Jobs, MapReduce Jobs, Simple Java programs, emails, joins etc as shown in the screenshot below:
8. Conclusion
This brings us to the end of the tutorial. This covers the basic introduction of the available option and their working. We started with the introduction to Hue followed by the features available in Hue. We then had a look at all the available options and how to use them to make the tasks related to Hadoop ecosystem and cluster easy if we are not in the mood to use the command line interfaces of all the different services. Hue provides a one point access to all the available services.
So, start using Hue and make Hadoop Cluster management easy and all at one interface.
