1. Introduction
In this example, I would like to show you how to get started with Apache Lucene and write a simple Hello World program. Apache Lucene is an open source tool that provides full text searching and indexing features. Apache Lucene site has excellent details of the features and examples. However, the examples on the site are very detailed. Here, I present a simple example to get started with this cool technology.
Table Of Contents
This example uses the below technologies, frameworks and IDE:
a. JDK 1.8
b. Apache Lucene 6.5.1
c. Eclipse Neon (You can use any IDE of your choice, or run it via command line)
2. Getting started
Let’s get going by first getting the relevant jars. At the time of writing this article, the latest apache lucene jar version is 6.5.1 that can be downloaded from the apache site. Extract the downloaded file and get the main jars (lucene-core-6.5.1.jar, lucene-queryparser-6.5.1.jar, lucene-analyzers-common-6.5.1.jar).
You may use any IDE of your choice or run code via command line.
Next, create a new eclipse project (I named it JCG).
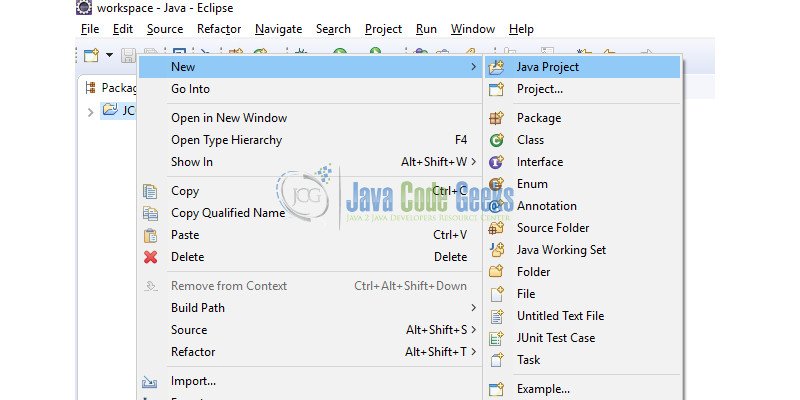
Choose a name for the project and save.
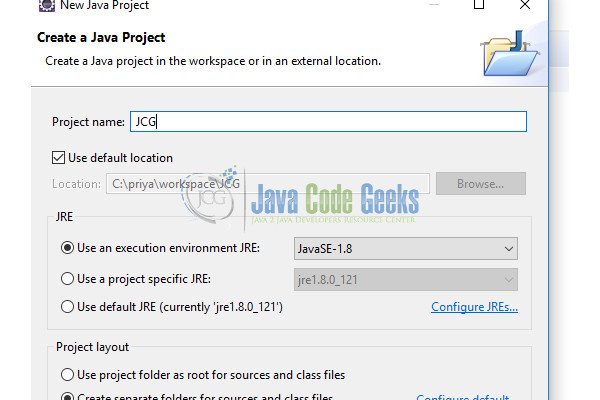
Add the downloaded jars in the project build path. Even though for this example we only need lucene-core and lucene-queryparser jars, it is recommended to add all three jars for lucene projects.

3. What the code needs to accomplish
We start by building a simple index using IndexWriter class that builds and maintains an index, create a couple of document objects and add them to the IndexWriter instance. For the purpose of illustrating the functionality, we are using RAMDirectory to create the IndexWriter. Please note that RAMDirectory is a memory-resident Directory implementation that may not work very well with big indexes. However, it works well to illustrate the Directory functionality needed for our program.
Once the documents have been added and indexed, we will use IndexReader to access the index and IndexSearcher to search the index by using a query that searches on the index created. QueryParser instance is created with the content to be searched for. Query instance fetched to get the TopDocs value that in turn gives the number of hits.
Java code listed below performs the search and lists the number of hits. Search on a value in the index should return number of hits in the index, while search for any text not indexed should return 0.
3.1 Java Code
Let’s look at the code now.
LuceneHelloWorld.java
package com.javacodegeeks.lucene;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.RAMDirectory;
public class LuceneHelloWorld {
public static void main(String[] args) throws IOException, ParseException {
//New index
StandardAnalyzer standardAnalyzer = new StandardAnalyzer();
Directory directory = new RAMDirectory();
IndexWriterConfig config = new IndexWriterConfig(standardAnalyzer);
//Create a writer
IndexWriter writer = new IndexWriter(directory, config);
Document document = new Document ();
//In a real world example, content would be the actual content that needs to be indexed.
//Setting content to Hello World as an example.
document.add(new TextField("content", "Hello World", Field.Store.YES));
writer.addDocument(document);
document.add(new TextField("content", "Hello people", Field.Store.YES));
writer.addDocument(document);
writer.close();
//Now let's try to search for Hello
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher (reader);
QueryParser parser = new QueryParser ("content", standardAnalyzer);
Query query = parser.parse("Hello");
TopDocs results = searcher.search(query, 5);
System.out.println("Hits for Hello -->" + results.totalHits);
//case insensitive search
query = parser.parse("hello");
results = searcher.search(query, 5);
System.out.println("Hits for hello -->" + results.totalHits);
//search for a value not indexed
query = parser.parse("Hi there");
results = searcher.search(query, 5);
System.out.println("Hits for Hi there -->" + results.totalHits);
}
}
3.2 Code output
The above code performs a query on the index using “Hello” and “hello” as search parameters – the search returns the total hits as expected. Searching on a value not present in the index e.g. "Hi there" returns 0 as the total hits as expected.
Hits for Hello -->2 Hits for hello ->2 Hits for Hi there -->0
3.3 Java code reading file contents and index output on a folder
We will now modify the code listed in section 3.1 to read from a file and index to a folder. Let’s look at the code:
LuceneHelloWorldReadFromFile.java
package com.javacodegeeks.lucene;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class LuceneHelloWorldReadFromFile {
public static void main(String[] args) throws IOException, ParseException {
// New index
StandardAnalyzer standardAnalyzer = new StandardAnalyzer();
String inputFilePath = "C:\\priya\\workspace\\JCG\\src\\com\\javacodegeeks\\lucene\\input.txt";
String outputDir = "C:\\priya\\workspace\\JCG\\src\\com\\javacodegeeks\\lucene\\output";
File file = new File(inputFilePath);
Directory directory = FSDirectory.open(Paths.get(outputDir));
IndexWriterConfig config = new IndexWriterConfig(standardAnalyzer);
config.setOpenMode(OpenMode.CREATE);
// Create a writer
IndexWriter writer = new IndexWriter(directory, config);
Document document = new Document();
try (BufferedReader br = new BufferedReader(new FileReader(inputFilePath))) {
document.add(new TextField("content", br));
writer.addDocument(document);
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
// Now let's try to search for Hello
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
QueryParser parser = new QueryParser("content", standardAnalyzer);
Query query = parser.parse("Hello");
TopDocs results = searcher.search(query, 5);
System.out.println("Hits for Hello -->" + results.totalHits);
// case insensitive search
query = parser.parse("hello");
results = searcher.search(query, 5);
System.out.println("Hits for hello -->" + results.totalHits);
// search for a value not indexed
query = parser.parse("Hi there");
results = searcher.search(query, 5);
System.out.println("Hits for Hi there -->" + results.totalHits);
}
}
3.4 Code Output
In the code presented in section 3.3, the change we have made is to read contents to be indexed from a file input.txt and index to the outputDir directory:
Directory directory = FSDirectory.open(Paths.get(outputDir));
IndexWriterConfig config = new IndexWriterConfig(standardAnalyzer);
config.setOpenMode(OpenMode.CREATE);
Document document = new Document();
try (BufferedReader br = new BufferedReader(new FileReader(inputFilePath))) {
document.add(new TextField("content", br));
writer.addDocument(document);
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
Also, the IndexWriter in this code creates index in the directory presented in attribute outputDir. You can view the indexing output by viewing the output folder. See a sample output below:
Sample input.txt and corresponding output of the java code in section 3.3 listed below:
input.txt-
Hello world
Output –
Hits for Hello -->1 Hits for hello -->1 Hits for Hi there -->0
4. Apache Lucene Hello World – Summary
In this example, we learnt how to get started with Lucene by getting the relevant jars, including jars in eclipse and running a Lucene Hello World programs – using two different approaches to indexing.
Hope you enjoyed this tutorial to get started with Lucene. This tutorial would serve as a starting point to get started with this rich open source technology. Enjoy and happy programming!
5. References
Some useful links are listed below for your reference:
6. Download the Eclipse Project
This was an Apache lucene Hello World example with Eclipse.
You can download the full source code of this example here: lucene hello world

great work | thank you so much!
Thanks for the example.