1. Introduction
In this article, we will take a look at Hive JDBC. Hive is part of the Hadoop Ecosystem. It is used in Big Data solutions with Hadoop. It was developed by Facebook. Hadoop is an Apache Opensource project now.
2. Hive – JDBC Connection
The Apache Hive project has featured in reading, writing, and managing big data. It is used in big data with distributed storage using SQL. JDBC Driver is available for Apache Hive for managing connections and executing DDL (Data Definition Language) and DML (Data Manipulation Language) statements.
2.1 Prerequisites
Java 8 is required on the Linux, Windows, or Mac operating systems. Eclipse Oxygen can be used for this example. Apache Hadoop 2.9.1 and Hive 3.1.2 are used in this example.
2.2 Download
You can download Java 8 from the Oracle web site. Eclipse Oxygen can be downloaded from the Eclipse web site. Apache Hadoop 2.9.1 can be downloaded from Hadoop Website. You can download Apache Hive 3.1.2 from the Hive website.
2.3 Setup
2.3.1 Java Setup
Below are the setup commands required for the Java Environment.Setup
Setup
JAVA_HOME="/desktop/jdk1.8.0_73" export JAVA_HOME PATH=$JAVA_HOME/bin:$PATH export PATH
2.4 IDE
2.4.1 Eclipse Oxygen Setup
The ‘eclipse-java-oxygen-2-macosx-cocoa-x86_64.tar’ can be downloaded from the eclipse website. The tar file is opened by double click. The tar file is unzipped by using the archive utility. After unzipping, you will find the eclipse icon in the folder. You can move the eclipse icon from the folder to applications by dragging the icon.
2.4.2 Launching IDE
Eclipse has features related to language support, customization, and extension. You can click on the eclipse icon to launch Eclipse. The eclipse screen pops up as shown in the screenshot below:

You can select the workspace from the screen which pops up. The attached image shows how it can be selected.
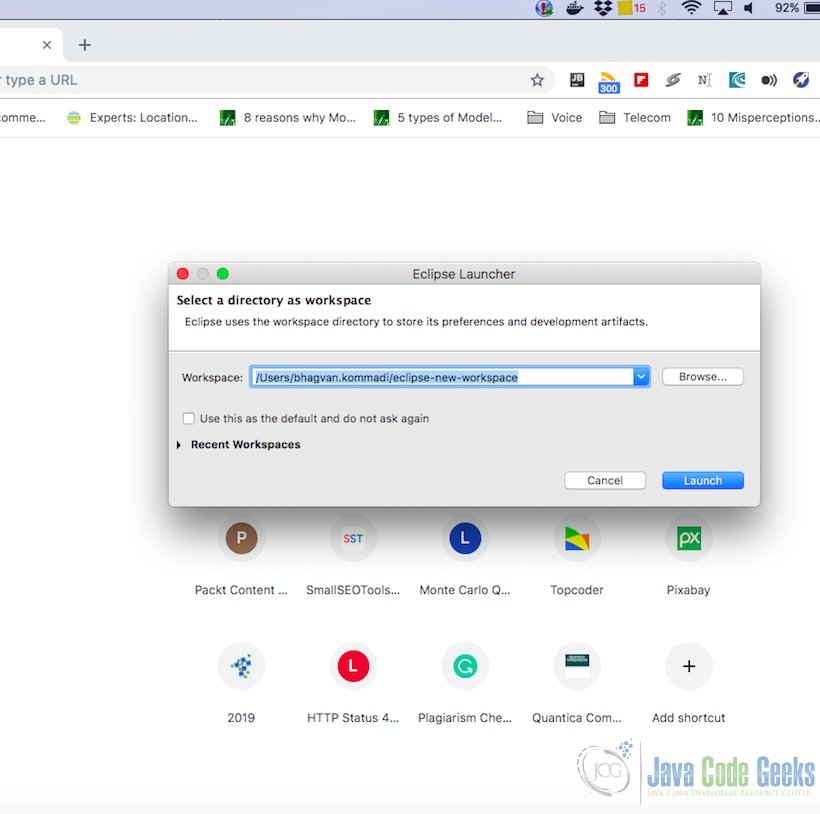
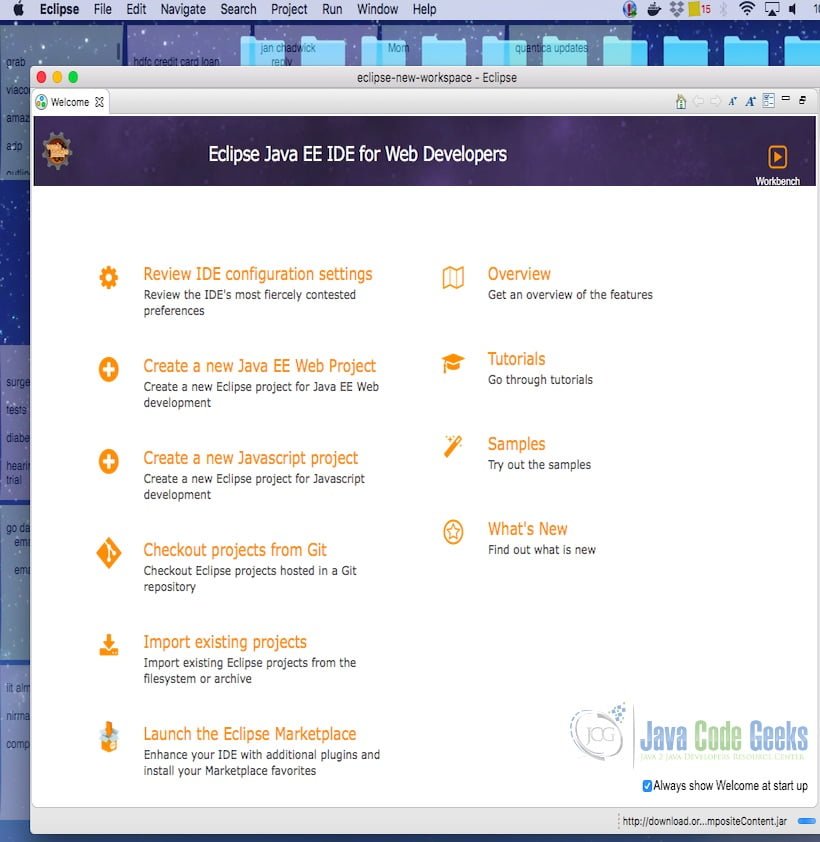
You can see the eclipse workbench on the screen. The attached screenshot shows the Eclipse project screen.
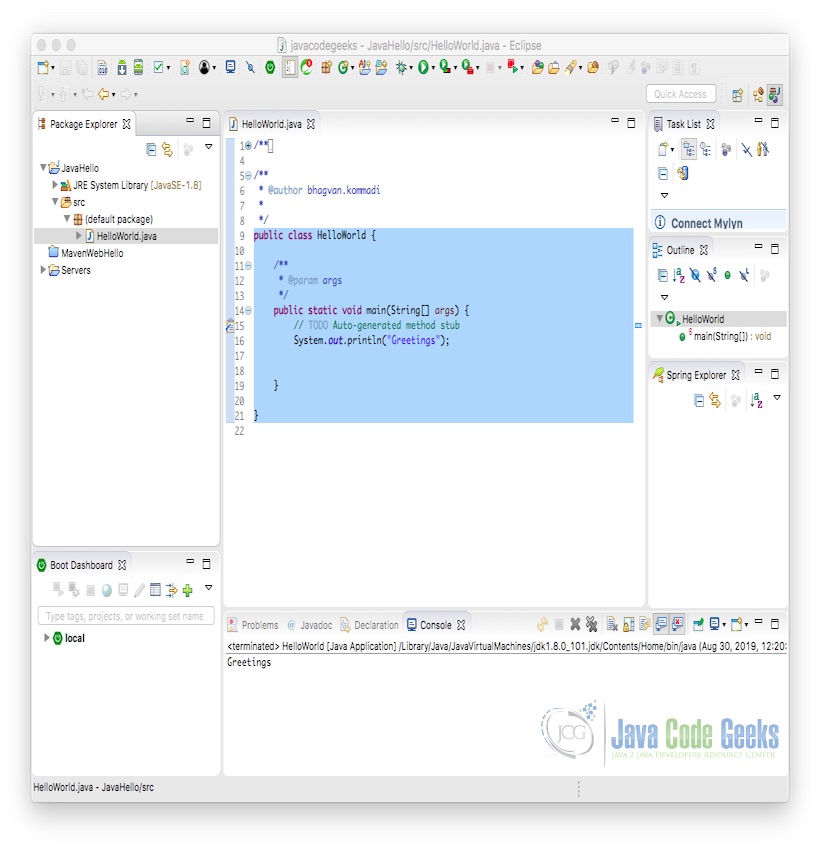
Java Hello World class prints the greetings. The screenshot below is added to show the class and execution on the eclipse.
2.5 Apache Hive
Apache Hive has features for SQL Access of data, handling multiple data formats, file access from Apache HDFS ad Apache HBase, executing query through Apache Tez, Apache Spark or Map Reduce, HPL-SQL language support, and query retrieval using Hive LLAP, Apache YARN & Apache Slider. Hive has a command-line tool and JDBC driver for data operations.
2.6 Apache Hive Components
Apache Hive has HCatalog and WebHCat components. HCatalog is used for storing data into Hadoop and provides data processing capabilities using Pig and Map Reduce. WebHCat is used to execute Hadoop MapReduce, Pig, and Hive jobs. Hive can be used for managing metadata operations using REST API. Hive can handle JDBC data types for handling data transformations.
2.7 Running Apache Hive
You need to configure HADOOP_HOME as below
Hadoop HOME
export HADOOP_HOME=/users/bhagvan.kommadi/desktop/hadoop-2.9.1/
You need to configure $HADOOP_HOME/etc/hadoop/core-site.xml as below
Core Site – Hadoop Configuration
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://apples-MacBook-Air.local:8020</value>
</property>
</configuration>
You need to start running Hadoop by using the command below
Hadoop Execution
cd hadoop-2.9.1/ cd sbin ./start-dfs.sh
The output of the commands is shown below
Hadoop Execution Output
apples-MacBook-Air:sbin bhagvan.kommadi$ ./start-dfs.sh 20/06/29 20:26:23 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable Starting namenodes on [apples-MacBook-Air.local] apples-MacBook-Air.local: Warning: Permanently added the ECDSA host key for IP address 'fe80::4e9:963f:5cc3:a000%en0' to the list of known hosts. Password: apples-MacBook-Air.local: starting namenode, logging to /Users/bhagvan.kommadi/desktop/hadoop-2.9.1/logs/hadoop-bhagvan.kommadi-namenode-apples-MacBook-Air.local.out Password: localhost: starting datanode, logging to /Users/bhagvan.kommadi/desktop/hadoop-2.9.1/logs/hadoop-bhagvan.kommadi-datanode-apples-MacBook-Air.local.out Starting secondary namenodes [0.0.0.0] Password: 0.0.0.0: starting secondarynamenode, logging to /Users/bhagvan.kommadi/desktop/hadoop-2.9.1/logs/hadoop-bhagvan.kommadi-secondarynamenode-apples-MacBook-Air.local.out 20/06/29 20:27:07 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
Mysql is used as the database for Hive Metastore. You need to configure $HIVE_HOME/conf/hive-site.xml as below
Hive Site – Hive Configuration
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/users/bhagvan.kommadi/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hivedb?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>newuser</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>newuser</value>
</property>
</configuration>
You need to start running Hive (HiveServer2) by using the command below
Hive Execution
export HIVE_HOME=/users/bhagvan.kommadi/desktop/apache-hive-3.1.2-bin/ $HIVE_HOME/bin/hiveserver2
The output of the commands is shown below
Hive Execution Output
apples-MacBook-Air:hive bhagvan.kommadi$ $HIVE_HOME/bin/hiveserver2 2020-06-29 23:56:26: Starting HiveServer2 SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/Users/bhagvan.kommadi/Desktop/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/Users/bhagvan.kommadi/Desktop/hadoop-2.9.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Hive Session ID = 28c5134a-d9f7-4ac2-9313-a04386f57ac9 Hive Session ID = 9c2982fa-965d-43e3-9f45-660e899a8958 Hive Session ID = 3000b392-aa68-4db1-ae3f-5b55c0fda19d Hive Session ID = da06d930-091f-4097-b8b0-cd463e14dc2d Hive Session ID = be1d5b5a-7f1a-4608-a08e-68f5515a2d90 Hive Session ID = 42f8afa1-3399-490e-8101-3f28d8d30072 Hive Session ID = 17b1f2aa-2c6d-40ff-849b-4c82fd1e38e0 Hive Session ID = d4e82376-f0ee-42e1-b27c-70dd8ce6efdc Hive Session ID = 1e20ac56-21cc-45ef-9976-48078c6e3a12 Hive Session ID = 5821afdf-696f-46d1-acfe-15f1cf078e4e Hive Session ID = f67cf1ba-937b-46a3-92b7-9c9efd145ae2 Hive Session ID = 9d8e3c3e-e216-4907-b0ba-08f23ffc8fd4 Hive Session ID = 316e0807-9c55-4bb5-a8da-360396581870 Hive Session ID = cef4c8de-9da8-4617-a053-9e28b40e8d6b Hive Session ID = 596b7b81-47d1-4b09-9816-e88576c5529c Hive Session ID = 7b1fe697-77e7-4c19-ac19-b0e0bf942480 Hive Session ID = 3aa7813d-f6a8-4238-a0b4-334106946266 Hive Session ID = e6631200-ee2b-487a-af8f-5d25f2a5e193
2.8 Apache Hive – JDBC Connection
To configure the JDBC connection to Apache Hive, you can use the following code:

Hive JDBC
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class HiveClient {
private static String driverClass = "org.apache.hive.jdbc.HiveDriver";
public static void main(String args[]) throws SQLException {
try {
Class.forName(driverClass);
} catch (ClassNotFoundException exception) {
exception.printStackTrace();
System.exit(1);
}
Connection connection = DriverManager.getConnection("jdbc:hive2://", "", "");
Statement statement = connection.createStatement();
String table = "CUSTOMER";
try {
statement.executeQuery("DROP TABLE " + table);
} catch (Exception exception) {
exception.printStackTrace();
}
try {
statement.executeQuery("CREATE TABLE " + table + " (ID INT, NAME STRING, ADDR STRING)");
} catch (Exception exception) {
exception.printStackTrace();
}
String sql = "SHOW TABLES '" + table + "'";
System.out.println("Executing Show table: " + sql);
ResultSet result = statement.executeQuery(sql);
if (result.next()) {
System.out.println("Table created is :" + result.getString(1));
}
sql = "INSERT INTO CUSTOMER (ID,NAME,ADDR) VALUES (1, 'Ramesh', '3 NorthDrive SFO' )";
System.out.println("Inserting table into customer: " + sql);
try {
statement.executeUpdate(sql);
} catch (Exception exception) {
exception.printStackTrace();
}
sql = "SELECT * FROM " + table;
result = statement.executeQuery(sql);
System.out.println("Running: " + sql);
result = statement.executeQuery(sql);
while (result.next()) {
System.out.println("Id=" + result.getString(1));
System.out.println("Name=" + result.getString(2));
System.out.println("Address=" + result.getString(3));
}
result.close();
statement.close();
connection.close();
}
}
In the eclipse, a Java project is configured with dependencies from
hive-jdbc.3.1.2-standalone.jar$HIVE_HOME/lib/*.jarfiles-
$HADOOP_HOME/share/hadoop/mapreduce/*.jar files $HADOOP_HOME/share/hadoop/common/*.jar
The apache hive JDBC code is executed from Eclipse using Run command. The output is shown below:
Hive JDBC Output
Loading data to table default.customer 2020-06-29T23:56:57,782 INFO [HiveServer2-Background-Pool: Thread-42] org.apache.hadoop.hive.ql.exec.Task - Loading data to table default.customer from file:/users/bhagvan.kommadi/hive/warehouse/customer/.hive-staging_hive_2020-06-29_23-56-50_794_3066299632130740540-1/-ext-10000 2020-06-29T23:56:57,784 INFO [HiveServer2-Background-Pool: Thread-42] org.apache.hadoop.hive.metastore.HiveMetaStore - 4: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore Running: SELECT * FROM CUSTOMER 2020-06-29T23:56:58,584 INFO [main] org.apache.hadoop.hive.conf.HiveConf - Using the default value passed in for log id: 42cd1c1e-dae1-4eb2-932c-57bf6653e77d 2020-06-29T23:56:58,584 INFO [main] org.apache.hadoop.hive.ql.session.SessionState - Updating thread name to 42cd1c1e-dae1-4eb2-932c-57bf6653e77d main 2020-06-29T23:56:58,785 INFO [main] org.apache.hadoop.hive.conf.HiveConf - Using the default value passed in for log id: 42cd1c1e-dae1-4eb2-932c-57bf6653e77d 2020-06-29T23:56:58,786 INFO [main] org.apache.hadoop.hive.ql.session.SessionState - Updating thread name to 42cd1c1e-dae1-4eb2-932c-57bf6653e77d main 2020-06-29T23:56:58,786 INFO [42cd1c1e-dae1-4eb2-932c-57bf6653e77d main] org.apache.hadoop.hive.conf.HiveConf - Using the default value passed in for log id: 42cd1c1e-dae1-4eb2-932c-57bf6653e77d 2020-06-29T23:56:58,786 INFO [42cd1c1e-dae1-4eb2-932c-57bf6653e77d main] org.apache.hadoop.hive.ql.session.SessionState - Resetting thread name to main 2020-06-29T23:56:58,786 INFO [main] org.apache.hadoop.hive.conf.HiveConf - Using the default value passed in for log id: 42cd1c1e-dae1-4eb2-932c-57bf6653e77d 2020-06-29T23:56:58,787 INFO [main] org.apache.hadoop.hive.ql.session.SessionState - Updating thread name to 42cd1c1e-dae1-4eb2-932c-57bf6653e77d main 2020-06-29T23:56:58,833 INFO [42cd1c1e-dae1-4eb2-932c-57bf6653e77d main] org.apache.hadoop.mapred.FileInputFormat - Total input files to process : 1 2020-06-29T23:56:58,837 INFO [42cd1c1e-dae1-4eb2-932c-57bf6653e77d main] org.apache.hadoop.hive.ql.exec.TableScanOperator - RECORDS_OUT_INTERMEDIATE:0, RECORDS_OUT_OPERATOR_TS_0:1, 2020-06-29T23:56:58,838 INFO [42cd1c1e-dae1-4eb2-932c-57bf6653e77d main] org.apache.hadoop.hive.ql.exec.SelectOperator - RECORDS_OUT_INTERMEDIATE:0, RECORDS_OUT_OPERATOR_SEL_1:1, 2020-06-29T23:56:58,838 INFO [42cd1c1e-dae1-4eb2-932c-57bf6653e77d main] org.apache.hadoop.hive.ql.exec.ListSinkOperator - RECORDS_OUT_INTERMEDIATE:0, RECORDS_OUT_OPERATOR_LIST_SINK_3:1, 2020-06-29T23:56:58,838 INFO [42cd1c1e-dae1-4eb2-932c-57bf6653e77d main] org.apache.hadoop.hive.conf.HiveConf - Using the default value passed in for log id: 42cd1c1e-dae1-4eb2-932c-57bf6653e77d 2020-06-29T23:56:58,838 INFO [42cd1c1e-dae1-4eb2-932c-57bf6653e77d main] org.apache.hadoop.hive.ql.session.SessionState - Resetting thread name to main Id=1 Name=Ramesh Address=3 NorthDrive SFO
The output above shows only the select query from the CUSTOMER table. In the code, the CUSTOMER table is created. Data is inserted into the CUSTOMER table. Apache Hive JDBC calls are based on Java JDBC calls using HiveQL (similar to SQL).
3. Download the Source Code
You can download the full source code of this example here: Hive JDBC Connection Java Example
