This article is a tutorial about Spring Batch with Hibernate. We will use Spring Boot to speed our development process.
1. Introduction
Spring Batch is a lightweight, scale-able and comprehensive batch framework to handle data at massive scale. Spring Batch builds upon the spring framework to provide intuitive and easy configuration for executing batch applications. Spring Batch provides reusable functions essential for processing large volumes of records, including cross-cutting concerns such as logging/tracing, transaction management, job processing statistics, job restart, skip and resource management.
Spring Batch has a layered architecture consisting of three components:
- Application – Contains custom code written by developers.
- Batch Core – Classes to launch and control batch job.
- Batch Infrastructure – Reusable code for common functionalities needed by core and Application.
Let us dive into spring batch with a simple example of reading persons from a CSV file and loading them into embedded HSQL Database. Since we use the embedded database, data will not be persisted across sessions.
2. Technologies Used
- Java 1.8.101 (1.8.x will do fine)
- Gradle 4.4.1 (4.x will do fine)
- IntelliJ Idea (Any Java IDE would work)
- Rest will be part of the Gradle configuration.
3. Spring Batch Project
Spring Boot Starters provides more than 30 starters to ease the dependency management for your project. The easiest way to generate a Spring Boot project is via Spring starter tool with the steps below:
- Navigate to https://start.spring.io/.
- Select Gradle Project with Java and Spring Boot version 2.0.0.
- Add Batch, JPA and HSqlDB in the “search for dependencies”.
- Enter the group name as com.JCG and artifact as SpringBatchHibernate.
- Click the Generate Project button.
A Gradle Project will be generated. If you prefer Maven, use Maven instead of Gradle before generating the project. Import the project into your Java IDE.
3.1 Gradle File
Below we can see the generated build file for our project.
build.gradle
buildscript {
ext {
springBootVersion = '2.0.0.RELEASE'
}
repositories {
mavenCentral()
}
dependencies {
classpath("org.springframework.boot:spring-boot-gradle-plugin:${springBootVersion}")
}
}
apply plugin: 'java'
apply plugin: 'eclipse'
apply plugin: 'idea'
apply plugin: 'org.springframework.boot'
apply plugin: 'io.spring.dependency-management'
group = 'com.JCG'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = 1.8
repositories {
mavenCentral()
}
dependencies {
compile('org.springframework.boot:spring-boot-starter-batch')
compile('org.springframework.boot:spring-boot-starter-data-jpa')
runtime('org.hsqldb:hsqldb')
compile "org.projectlombok:lombok:1.16.8"
testCompile('org.springframework.boot:spring-boot-starter-test')
testCompile('org.springframework.batch:spring-batch-test')
}
- Spring Boot Version 2.0 is specified in line 3.
- Idea plugin has been applied to support Idea IDE in line 14.
- Lines 23-29 declare the dependencies needed for the project with each downloading the latest version from spring.io.
- Line 27 declares the
Lombokdependency which is used to reduce typing boilerplate code.
3.2 Data file
- Create a sample file sample-data.csv.
- It consists of two columns – First Name and Last Name.
- The file should be in the path
src/main/resources.
Sample CSV
FirstName,LastName Jill,Doe Joe,Doe Justin,Doe Jane,Doe John,Doe
- Line1 indicates the header for the CSV file. It will be ignored by spring batch while reading the file.
3.3 Spring Batch Configuration
Below we will cover the Java configuration for Spring Boot, Batch and Hibernate. We will discuss each part of the configuration below.
Application Class
package com.JCG;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
- We specify our application as the springboot application in Line 6. It takes care of all the Auto Configuration magic. Spring boot works on the philosophy of convention over configuration. It provides sensible defaults and allows overriding with the appropriate configuration.
- Line 10 starts our application with the configuration specified in below section.
Batch Configuration
package com.JCG.config;
import com.JCG.model.Person;
import com.JCG.model.PersonRepository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.*;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.database.JpaItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import javax.persistence.EntityManagerFactory;
@Configuration
@EnableBatchProcessing
public class BatchConfiguration {
@Autowired
public JobBuilderFactory jobBuilderFactory;
@Autowired
public StepBuilderFactory stepBuilderFactory;
@Autowired
EntityManagerFactory emf;
@Autowired
PersonRepository personRepository;
private static final Logger log = LoggerFactory.getLogger(BatchConfiguration.class);
@Bean
public FlatFileItemReader reader() {
FlatFileItemReader reader = new FlatFileItemReader<>();
reader.setResource(new ClassPathResource("sample-data.csv"));
reader.setLinesToSkip(1);
DefaultLineMapper lineMapper = new DefaultLineMapper<>();
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();
tokenizer.setNames("firstName", "lastName");
BeanWrapperFieldSetMapper fieldSetMapper = new BeanWrapperFieldSetMapper<>();
fieldSetMapper.setTargetType(Person.class);
lineMapper.setFieldSetMapper(fieldSetMapper);
lineMapper.setLineTokenizer(tokenizer);
reader.setLineMapper(lineMapper);
return reader;
}
@Bean
public JpaItemWriter writer() {
JpaItemWriter writer = new JpaItemWriter();
writer.setEntityManagerFactory(emf);
return writer;
}
@Bean
public ItemProcessor<Person, Person> processor() {
return (item) -> {
item.concatenateName();
return item;
};
}
@Bean
public Job importUserJob(JobExecutionListener listener) {
return jobBuilderFactory.get("importUserJob")
.incrementer(new RunIdIncrementer())
.listener(listener)
.flow(step1())
.end()
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step1")
.<Person, Person>chunk(10)
.reader(reader())
.processor(processor())
.writer(writer())
.build();
}
@Bean
public JobExecutionListener listener() {
return new JobExecutionListener() {
@Override
public void beforeJob(JobExecution jobExecution) {
/**
* As of now empty but can add some before job conditions
*/
}
@Override
public void afterJob(JobExecution jobExecution) {
if (jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("!!! JOB FINISHED! Time to verify the results");
personRepository.findAll().
forEach(person -> log.info("Found <" + person + "> in the database."));
}
}
};
}
}
Lines 25 indicates that it is a configuration class and should be picked up by spring boot to wire up the beans and dependencies. Line 26 is used to enable batch support for our application. Spring defines a Job which contains multiple Step to be executed. In our example, we use only a single step for our importUserJob. We use a JobExecutionListener to track the job execution which we will cover below. A Step could be a TaskletStep(contains a single function for execution) or Step which includes a Reader, Processor and Writer. In the above example, We have used Step.

3.3.1 Reader
Lines 42-60 include our reader configuration. We use FlatFileItemReader to read from our CSV file. The advantage of using an inbuilt reader is that it handles application failures gracefully and will support restarts. It can also skip lines during errors with a configurable skip limit.
It needs the following parameters to successfully read the file line by line.
- Resource – The application reads from a class path resource as specified in line 45. We skip the header line by specifying
setLinesToSkip. - Line Mapper – This is used to map a line read from the file into a representation usable by our application. We use
DefaultLineMapperfrom Spring Infrastructure. This, in turn, uses two classes to map the line to our modelPerson. It uses aLineTokenizerto split one single line into tokens based on the criteria specified and aFieldSetMapperto map the tokens into a fieldset usable by our application.- Line Tokenizer – We use
DelimitedLineTokenizerto tokenize the lines by splitting with a comma. By default, the comma is used as the tokenizer. We also specify the token names to match the fields of our model class. FieldSetMapper– Here we are usingBeanWrapperFieldSetMapperto map the data to a bean by its property names. The exact field names are specified in the tokenizer which will be used.
- Line Tokenizer – We use
- Line Mapper is mapped to the reader in line 57.
Reader reads the items in the chunk(10) which is specified by the chunk config in line 91.
3.3.2 Processor
Spring does not offer an inbuilt processor and is usually left to the custom implementation. Here, We are using a lambda function to transform the incoming Person object. We call the concatenateName function to concatenate the first name and last name. We return the modified item to the writer. Processor does its execution one item at a time.
3.3.3 Writer
Here, we are using JpaItemWriter to write the model object into the database. JPA uses hibernate as the persistence provider to persist the data. The writer just needs the model to be written to the database. It aggregates the items received from the processor and flushes the data.
3.3.4 Listener
JobExecutionListener offers the methods beforeJob to execute before the job starts and afterJob which executes after job has been completed. Generally, these methods are used to collect various job metrics and sometimes initialize constants. Here, we use afterJob to check whether the data got persisted. We use a repository method findAll to fetch all the persons from our database and display it.
3.4 Model/Hibernate configuration
application.properties
spring.jpa.hibernate.ddl-auto=create-drop spring.jpa.show-sql=true
Here we specified that tables should be created before use and destroyed when the application terminates. Also, we have specified configuration to show SQL ran by hibernate in the console for debugging. Rest of the configuration of wiring Datasource to hibernate and then in turn to JPA EntityManagerfactory is handled by JpaRepositoriesAutoConfiguration and HibernateJpaAutoConfiguration.
Model Class(Person)
package com.JCG.model;
import lombok.*;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.Transient;
@Entity
@Getter
@Setter
@NoArgsConstructor
@RequiredArgsConstructor
@ToString(exclude={"firstName","lastName"})
public class Person {
@Id
@GeneratedValue
private int id;
@Transient
@NonNull
private String lastName;
@Transient
@NonNull
private String firstName;
@NonNull
private String name;
public void concatenateName(){
this.setName(this.firstName+" "+this.lastName);
}
}
A model class should be annotated with Entity to be utilized by spring container. We have used Lombok annotations to generate getter, setter and Constructor from our fields. Fields firstName and lastName are annotated as Transient to indicate that these fields should not be persisted to the database. There is an id field which is annotated to generate the hibernate sequence while saving to the database.
Repository Class(PersonRepository)
package com.JCG.model;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface PersonRepository extends JpaRepository<Person,Integer> {
}
This is just a repository implementation of Spring JPA repository. For a detailed example refer JPA Repository example.
4. Summary
Run the Application class from a Java IDE. Output similar to the below screenshot will be displayed. In this example, we saw a simple way to configure a Spring Batch Project Application.
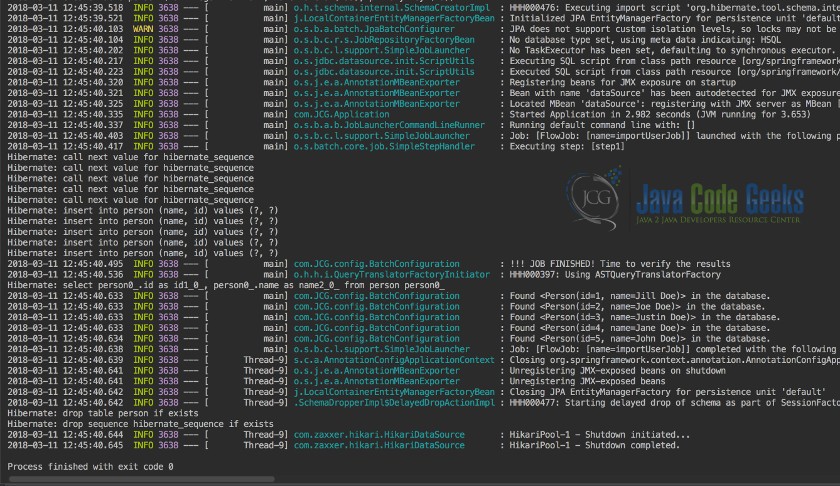
5. Download the Source Code
You can download the full source code of this example here: SpringBatchHibernate

Caused by: org.springframework.beans.NotWritablePropertyException: Invalid property ‘firstName’ of bean class [com.JCG.model.Person]: Bean property ‘firstName’ is not writable or has an invalid setter method. Does the parameter type of the setter match the return type of the getter?
at org.springframework.beans.BeanWrapperImpl.createNotWritablePropertyException(BeanWrapperImpl.java:247) ~[spring-beans-5.0.4.RELEASE.jar:5.0.4.RELEASE]
at org.springframework.beans.AbstractNestablePropertyAccessor.processLocalProperty(AbstractNestablePropertyAccessor.java:426) ~[spring-beans-5.0.4.RELEASE.jar:5.0.4.RELEASE]
at org.springframework.beans.AbstractNestablePropertyAccessor.setPropertyValue(AbstractNestablePropertyAccessor.java:278) ~[spring-beans-5.0.4.RELEASE.jar:5.0.4.RELEASE]
at org.springframework.beans.AbstractNestablePropertyAccessor.setPropertyValue(AbstractNestablePropertyAccessor.java:266) ~[spring-beans-5.0.4.RELEASE.jar:5.0.4.RELEASE]
at org.springframework.beans.AbstractPropertyAccessor.setPropertyValues(AbstractPropertyAccessor.java:97) ~[spring-beans-5.0.4.RELEASE.jar:5.0.4.RELEASE]
at org.springframework.validation.DataBinder.applyPropertyValues(DataBinder.java:839) ~[spring-context-5.0.4.RELEASE.jar:5.0.4.RELEASE]
at org.springframework.validation.DataBinder.doBind(DataBinder.java:735) ~[spring-context-5.0.4.RELEASE.jar:5.0.4.RELEASE]
at org.springframework.validation.DataBinder.bind(DataBinder.java:720) ~[spring-context-5.0.4.RELEASE.jar:5.0.4.RELEASE]
at org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper.mapFieldSet(BeanWrapperFieldSetMapper.java:198) ~[spring-batch-infrastructure-4.0.0.RELEASE.jar:4.0.0.RELEASE]
at org.springframework.batch.item.file.mapping.DefaultLineMapper.mapLine(DefaultLineMapper.java:43) ~[spring-batch-infrastructure-4.0.0.RELEASE.jar:4.0.0.RELEASE]
at org.springframework.batch.item.file.FlatFileItemReader.doRead(FlatFileItemReader.java:180) ~[spring-batch-infrastructure-4.0.0.RELEASE.jar:4.0.0.RELEASE]
… 50 common frames omitted
I think lombok annotations are not being processed correctly. Getter and setter are autogenerated by it. Can you please check once if gradle dependencies are pulled correctly. Also can you check this out ? https://stackoverflow.com/questions/3418865/cannot-make-project-lombok-work-on-eclipse-helios/3425327#3425327
Thank You very much!
This example is nice but not finished. It misses a crucial part of development which are unit tests. Now everybody is talking about TDD. How would you get an instance of EntityManagerFactory? I am struggling with this issue.