Data Analytics using Hadoop is one of the most important requirement in businesses today due to the amount of data being generated and the value the businesses can generate from this data. We will look into some of the best Hadoop Analytics Solutions available in the market which can be used for data analysis.
Table Of Contents
1. Introduction
Apache Hadoop was developed as open source implementation of the Google MapReduce and big companies started using this initially. But as Hadoop matured as a platform, more and more companies started using it due to the fact that is is fast, fault-tolerant and moreover it runs on a cluster of commodity machines. The rising interest in the Apache Hadoop platform gave birth to the commercial components and support of Apache Hadoop. Cloudera was the first company to introduce the commercial support for companies in 2008 followed by MapR in 2009 and Hortonworks in 2011.
As more and more enterprise organizations started showing interest in Apache Hadoop and started using it for the data analysis, there are a lot of companies which provided built in solution for Data Analytics which are based on top of Apache Hadoop. With these products and companies user can directly implement the niche solution they want to instead of going through all the pitfalls of implementing from scratch on top of bare bone Apache Hadoop.
In the following sections, we will look at some of the best data analytics solutions which are based on top of Apache Hadoop.
2. IBM BigInsights
Big Insight is developed by IBM. It is pitched by IBM as offering the best of open source software with enterprise-grade capabilities. BigInsights solves the two main issues related to big data i.e managing the data and analyzing the data to provide the values insights. BigInsights also offers a Data Scientist module which is aimed at providing all the possible options and ways to perform data analysis. Besides the managing the analyzing data BigInsight also offers visualization tools.
BigInsight is made available by IBM both on-premises as well as in cloud which makes it even for easier and fast to start working on the data immediately.
3. Apache Kudu
Apache Kudu is the open source project in the product line of Hadoop Big Data Analytics solutions. The main aim of Apache Kudu is to provide an open source produce which can perform fast analytical and that too in real-time or near real-time. Apache Kudu completes Hadoop’s storage layer to enable fast analytics on fast data. It is a storage system for tables of structured data that is designed to enable real-time analytic applications in Hadoop.
Kudu was developed and contributed to open source by Cloudera, it was created to contribute the likes of Apache HBase and Hadoop Distributed File System (HDFS). One of the benefits of Apache Kudu is that it supports both low-latency random access and high-throughput analytics which simplifies Hadoop architectures for real-time use cases.
Kudu was designed to fit in with the Hadoop ecosystem from the starting and also provides a very easy and simple integration with other data processing frameworks. Apache Kudu can also process streams of directly from live real-time data sources such ask Twitter firehose using the provided Java client, and then process it immediately upon arrival using Spark, Impala, or MapReduce. Data can then be stored in other Hadoop storages such as HDFS or HBase.
Kudu is a good citizen on a Hadoop cluster: it can easily share data disks with HDFS DataNodes, and can operate in a RAM footprint as small as 1 GB for light workloads.
4. Pentaho
Pentaho is the company which advertises itself as “A Comprehensive Data Integration and Business Analytics Platform”. It offers a number of analytics solutions that have been tightly linked with Hadoop. Pentaho’s Business Analytics proprietary tools provide embedded analytics, along with data visualization tools that are designed to be interactive for the users.
Pentaho covers a whole range of tools which start from data integration to data analytics, storage, visualization of data in interactive dashboards and which can be customized to feature the most important KPIs for the organization. The tools are highly customizable and interactive which are created with ease of use in mind, while offering high-level tools to prepare, blend and deliver governed data from sources like Hadoop. It also offers a visual MapReduce designer for Hadoop that works to eliminate coding and complexity so that even the not IT professionals can make use of the Pentaho pipeline for data analysis.
Pentaho is another software platform that began as a report generating engine; it is, like JasperSoft, branching into big data by making it easier to absorb information from the new sources. Currently, Pentaho also offers integration with other NoSQL databases also such as MongoDB and Cassandra. Once the databases are connected, user can drag and drop the columns into views and reports as if the information came from SQL databases.
Pentaho also provides software for drawing HDFS file data and HBase data from Hadoop clusters. One of the more intriguing tools is the graphical programming interface known as either Kettle or Pentaho Data Integration. It has a bunch of built-in modules that you can drag and drop onto a picture, then connect them. Pentaho has thoroughly integrated Hadoop and the other sources into this, so you can write your code and send it out to execute on the cluster.
All these tools and the level to which Pentaho made data analysis interactive and easy even for non-technical person are the reasons why it is one of the most widely used analytics platform out there.
5. Teradata
Teradata entered the big data era boasting the largest roster of petabyte-scale enterprise data warehouse customers of any vendor. In 2012. Teradata partnered with Hortonworks to build out Unified Data Architecture(UDA). Teradata DBMS is the core part of the UDA. It supports Enterprise Data Warehouses and marts for production business intelligence and analytical needs.
Data analytics option on Teradata platform includes SQL, SQL-MapReduce and graph analysis. Teradata can be used without Hadoop as well as with Hadoop for high-scale and low-cost storage. Teradata also provides SQL-H which is the SQL-on-Hadoop option available in Teradata’s Unified Data Architecture.
6. Pivotal
Pivotal is the EMC spinoff that offers the big data infrastructure as well as an abstraction layer for cloud computing based on Cloud Foundry and an agile application development environment based on SpringSource.
Pivotal’s big data analytics capabilities blend in the Pivotal HD Hadoop Distribution with GemFire SQL Fire-in-memory technology, the Greenplum database, and HAWQ (Hadoop With Query) SQL querying capabilities. It also has close ties and in-database integration with SAS analytics.
Pivotal provides a full-fledged Big Data Suite which provides a broad foundation for modern data architectures. It can be deployed on-premise and in public clouds, and contains all the elements for batch and streaming analytics architectures. Each product of Pivotal Big Data Suite is based on open source technologies developed by the open source community. Pivotal as a company creates the production ready distributions around the open source components and provides these products and tools along with the production support for all their products.
Pivotal Big Data Suite uses a subscription based model where the subscription can be from one year to upto three years. The subscription are based on the cores users would need for their data analytics and the time duration for which these cores will be needed.
Pivotal also provides support for the subscribers which can also include the help with setting up analytics pipelines with the help os Pivotal’s data science team which can help accelerate skill development and kick start the analytics process. The Hadoop-native SQL and scale-out data warehouses in Pivotal Big Data Suite support machine learning libraries and perform complex SQL queries at high speed.
7. Jaspersoft BI Suite
The Jaspersoft package is one of the leaders for producing reports from database columns. The software is well-polished and already installed in many businesses turning SQL tables into PDFs that everyone can scrutinize at meetings.
The company is jumping on the big data train, and this means adding a software layer to connect its report generating software to the places where big data gets stored. The JasperReports Server now offers software to suck up data from many of the major storage platforms, including MongoDB, Cassandra, Redis, Riak, CouchDB, and Neo4j. Hadoop is also well-represented, with JasperReports providing a Hive connector to reach inside of HBase.
This is a well-developed corner of the software world, and Jaspersoft is expanding by making it easier to use these sophisticated reports with newer sources of data.
8. Tableau Desktop and Server
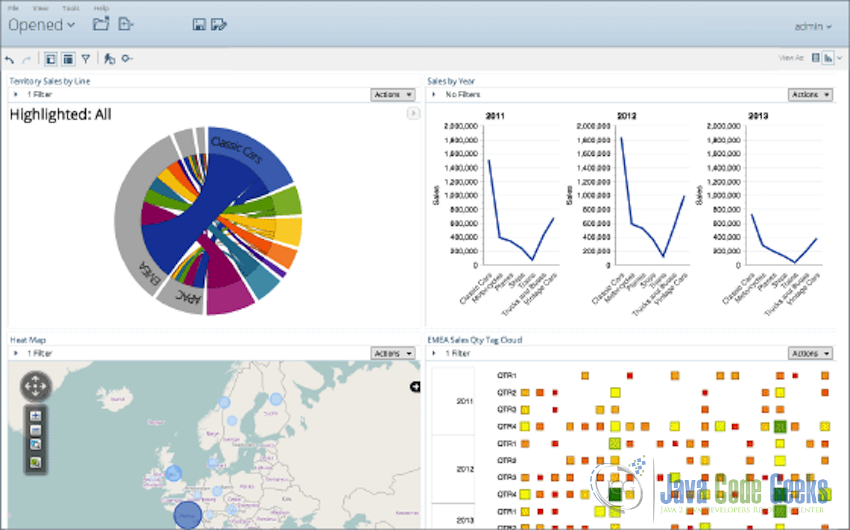
Tableau Desktop is another data analytics and visualization tool that makes it easy to look at the data in new ways, then slice it up and look at it in a different way. Tableau provides an easy to use drag-drop interface where we can mix the data with other data and examine it in yet another light. The tool is optimized to provide all the possible dimensions of the data which can be converted into one of the dozens of graphical templates provided.
Tableau Software can use many types of data storages to get data for the analysis including the traditional databases and files but what makes it important in today’s data driven time is that it embraces Hadoop from a long time ago.
In case of Apache Hadoop, Tableau relies upon Hive to structure the queries, then tries its best to cache as much information in memory to allow the tool to be interactive. While many of the other reporting tools are built on a tradition of generating the reports offline, Tableau wants to offer an interactive mechanism so that we can slice and dice the data again and again. Caching helps deal with some of the latency of a Hadoop cluster.
The software is well-polished and aesthetically pleasing. It is quite easy to use and makes it really easy for non-technical people to use the data to make better decisions without digging deep into the technical details of the data analysis.
9. AtScale
AtScale is one of the companies which offers Analytics tools which are natively based on Hadoop instead of being developed for Hadoop on a later stage. Analysis using AtScale on top of Hadoop accesses data as it has been written, directly on the Hadoop cluster, instead of taking it out of the Hadoop cluster and persisting it in a different system for consumption. The results of this type of ‘query-in-place’ approach are significant: BI and Data analytics agility is significantly enhanced. Operational cost and complexity is reduced upto a large extend.
AtScale does not offer its own visualization tool which can be a good option if you have your own favorites existing visualization tools which you want to use. The AtScale Intelligence Platform supports Business Intelligence and Data Analytics on Hadoop by providing native support for the most widely-adopted visualization tools like Tableau, Qlik, Spotfire, and Microsoft Excel. AtScale dynamic cubes integrate nicely with their existing tools while also providing a layer of governance to ensure standardization of business logic across data consumers.
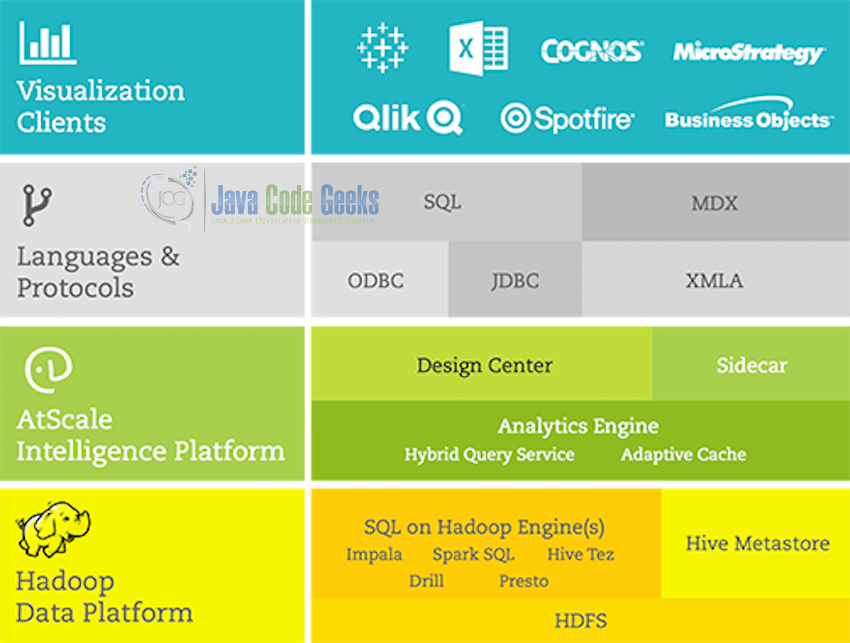
Another good point in favor of AtScale is that it allows users to select their favourites Hadoop Distribution. AtScale supports all the major Hadoop Distributions – Cloudera, Hortonworks, and MapR. Additionally, AtScale can work natively with the top SQL-on-Hadoop engines – Impala, SparkSQL, and Hive-Tez.
AtScale provides a lot of flexibility that users can select their favorite visualization tool and integrate it with AtScale as well as they can use the already existing distribution of Hadoop if they have one already running in their organization and need not to set up another cluster with another distribution.
10. Arcadia Data
Arcadia Data is another Big Data Hadoop Analytic platform which unifies data discovery, visual analytics and business intelligence in a single and integrated platform that runs natively on your Hadoop clusters. With Arcadia Data also there is not need of a separate Hadoop Distribution cluster. If can run on the existing cluster used in the organization.

Arcadia Data also provides an interactive drag-drop interface where user need not to build data marks or data cubes, user can directly use the interactive drag-drop interface on top of data to create different interactive dashboards as per the requirement.
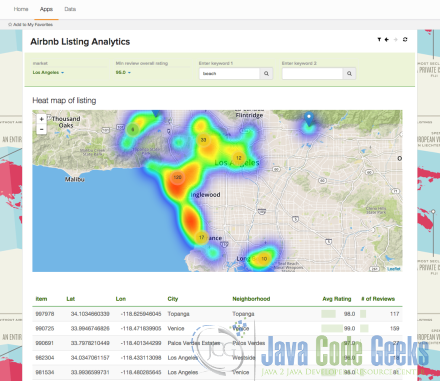
Arcadia Data can connect to almost all major Hadoop Ecosystem project which may need Arcadia data. It can connect to multiple data sources such as, Hive, Impala, Amazon Redshift, Teradata Aster, Postgres Sql and MySql etc.
11. Actian
Actian provides an Apache Hadoop based Data Analysis platform called Vector in Hadoop (VectorH) which is capable of realizing business value from the data stored in the Hadoop Clusters.
VectorH provides elastic data preparation for analysis. Bring in data quickly with the inbuild analytic engines and also provide KNIME user interface for visualizing trends and patterns in data with hyper-parallelized Hadoop analytics. SQL can be directly used in the applications and tools directly on top of Hadoop with fully industrialized SQL support
Apache Hadoop, Spark and Hive and other open source and proprietary platforms have allowed companies to explore big data in ways which were not possible previously. Most of these products and platforms being Open-Source brings the cost of implementation and maintenance to very low. Actian’s products are also built on top of Open-Source platforms.
One of the major focus of Actian Data Analytics Platform is speed and performance. Many analytics platforms are encumbered by performance that slows when data sets get larger but as per the Actian team their data analysis product is built on an analytics platform designed for speed. With blazingly fast analytics engines, users can get results more quickly and stay a step ahead of the competition.
12. QlikView
QlikView is another visualization focused platform like Tableau which lets us create visualizations, dashboards, and apps that answer the company’s most important KPIs. It provides an interactive way of searching and exploring large amounts of data. With Qlik, you’re not constrained by preconceived notions of how data should be related, but can finally understand how it truly is related. Analyze, reveal, collaborate and act.
Qlik lets users convert data into insights across all aspects of the data. At the core of QlikView is a patented software engine designed and develop inhouse by Qlik, which generates new views of data on the fly. QlikView compresses data and holds it in memory, where it is available for immediate exploration by multiple users. For data sets too large to fit in memory, QlikView connects directly to the data source. It delivers an associative experience across all the data used for analysis, regardless of where it is stored.
13. Splunk
Hunk: Splunk Analytics for Hadoop is another platform gives us the power to rapidly detect patterns and find anomalies across petabytes of raw data in Apache Hadoop cluster without the need to move or replicate data in any other form or in any other datastore. Users can make the most of the large quantity of data stored in Hadoop with the help of “Hunk: Splunk Analytics for Hadoop”. With Hunk users can rapidly explore, analyze and visualize data in Hadoop. It delivers dramatic improvements in the speed and simplicity of getting insights from raw, unstructured or multi-structured big data—all without building fixed schemas or moving data to a separate in-memory store.
Search and analyze across real-time data in Splunk Enterprise and historical data in Hadoop through a single, fluid user experience give anyone in the organization including the non-technical people the power to perform rapid, self-service analytics on big data.
Hunk also provides the visualization component which allows users to quickly create and share charts, graphs and dashboards. Ensure security with role-based access control and HDFS pass-through authentication. Hunk natively supports Apache Hadoop and Amazon EMR, Cloudera CDH, Hortonworks Data Platform, IBM InfoSphere BigInsights, MapR M-series and Pivotal HD distributions. In this way, it provides a whole lot of flexibility for reusing the data which might already be in one os the supported data stores.
Hunk comes with a feature called “Schema-on-the-fly technology” which means that users do not
need to know anything about the data in advance. It automatically adds structure and identifies fields of interest at search time, such as keywords, patterns over time, top values etc.
In short, Hunk is a full-featured, integrated analytics platform providing features to explore, analyze and visualize data; create dashboards and share reports. Instantly pivot from any search and automatically identify meaningful patterns in the data which can be used directly from one of the many supported datastores.
14. Hortonworks Data Platform
Hortonworks Data Platform (HDP) is the enterprise-ready open source Apache Hadoop distribution based on a centralized architecture (YARN). HDP addresses the complete needs of data-at-rest, powers real-time customer applications and delivers robust analytics that accelerate decision making and innovation. It also provides options for integrating the data analysis feature. YARN and Hadoop Distributed File System (HDFS) are the cornerstone components of HDP. While HDFS provides the scalable, fault-tolerant, cost-efficient storage for your big data lake, YARN provides the centralized architecture that enables you to process multiple workloads simultaneously.
Hortonworks Data Platform includes a versatile range of processing engines that empower users to interact with the same data in multiple ways that too directly from the Hadoop Cluster. This means applications can interact with the data in multiple ways and the user can select the best possible way of interaction from batch to interactive SQL or low latency access with NoSQL. HDP extends data access and management with powerful tools for data governance and integration. They provide a reliable, repeatable, and simple framework for managing the flow of data in and out of Hadoop. This control structure, along with a set of tooling to ease and automate the application of schema or metadata on sources is critical for successful integration of Hadoop into business data architecture.
Cloudbreak, as part of Hortonworks Data Platform and powered by Apache Ambari, allows users to simplify the provisioning of clusters in any cloud environment including; Amazon Web Services, Microsoft Azure, Google Cloud Platform and OpenStack. It optimizes the use of cloud resources as workloads change. So HDP is a kind of platform which is a complete package and provide every possible required component.
15. HP Enterprise Vertica
Vertica as per HP is the most advanced SQL database analytics portfolio built to address the most demanding Big Data analytics initiatives. HPE Vertica delivers speed without compromise, scale without limits, and the broadest range of consumption models.
Vertica can be provisioned on-premise, in the cloud, or on Hadoop. It provides default support for all leading business intelligence and visualization tools, open source technologies like Hadoop and R, and built-in analytical functions.
HPE Vertica is built to handle the challenges of Big Data analytics. One of the focus of Vertica is its massively parallel processing system, it can handle petabyte-scale data. HPE Vertica also provides very advanced SQL-based analytics from graph analysis to triangle counting to Monte Carlo simulations and many more.
At the core of the HPE Vertica Analytics Platform is a column-oriented, relational database built specifically to handle today’s analytic workloads. It also provides an inbuilt clustered approach to storing Big Data, offering superior query and analytic performance. Also Vertica relies a lot on the compression of the data and in a result consumes a very little resources and does not need a very high end and expensive hardware. Vertica has Built-in predictive analytics.
When Vertica is used together with Hadoop it installs SQL library in the Hadoop cluster and which allows to use a powerful set of data analytics capabilities. It offers no single
point of failure because it’s not reliant on a helper node to query.
HPE Vertica can also read native Hadoop file formats like ORC, Parquet, Avro, and others. By installing the Vertica SQL engine in the Hadoop cluster, users can tap into advanced and comprehensive SQL on Hadoop capabilities.
16. Conclusion
In this article, we read about some of the best Data Analytics and Business Intelligence platforms which already uses or can use Apache Hadoop Clusters for helping with the analysis. Each of the proprietary company provides best available product with some changes from one another. For if you have to choose then a platform for data analysis choose carefully and the one which will fit well for the needs.

Nice Job! explained well about hadoop analytics solutions