Hello. In this tutorial, we will build an event drive architecture example using Kafka.
1. Introduction
Kafka is an open-source distributed streaming platform developed by LinkedIn and later donated to the Apache Software Foundation. It was designed to handle real-time data streams, making it a highly scalable, fault-tolerant, and distributed system for processing and storing large volumes of event data. Kafka is widely used for various use cases, such as log aggregation, event sourcing, messaging, and real-time analytics.
1.1 Key Concepts
- Topics: Kafka organizes data streams into topics, which are similar to categories or feeds. Each topic consists of a stream of records or messages.
- Producers: Producers are applications that publish data to Kafka topics. They write messages to specific topics, and these messages are then stored in the Kafka brokers.
- Brokers: Kafka brokers are the nodes that form the Kafka cluster. They are responsible for receiving, storing, and serving messages. Each broker holds one or more partitions of a topic.
- Partitions: Topics can be divided into multiple partitions, essentially ordered message logs. Partitions allow data to be distributed and processed in parallel across different brokers.
- Consumers: Consumers are applications that read data from Kafka topics. They subscribe to one or more topics and receive messages from the partitions of those topics.
- Consumer Groups: Consumers can be organized into consumer groups, where each group consists of one or more consumers. Each message in a partition is delivered to only one consumer within a group, allowing parallel processing of data.
1.2 How does Kafka work?
- Data Ingestion: Producers send messages to Kafka brokers. Producers can choose to send messages synchronously or asynchronously.
- Storage: Messages are stored in partitions within Kafka brokers. Each partition is an ordered, immutable sequence of messages.
- Replication: Kafka provides fault tolerance through data replication. Each partition has one leader and multiple replicas. The leader handles read and write operations, while the replicas act as backups. If a broker fails, one of its replicas can be promoted as the new leader.
- Retention: Kafka allows you to configure a retention period for each topic, determining how long messages are retained in the system. Older messages are eventually purged, making Kafka suitable for both real-time and historical data processing.
- Consumption: Consumers subscribe to one or more topics and read messages from partitions. Consumers can process data in real time or store it in a database for later analysis.
Overall, Kafka has become an essential component in modern data architectures, allowing organizations to handle large-scale event-driven data streams efficiently.
2. Key Components
Here are the key components of an event-driven architecture that enable event flow and processing:
- Events: Events are the core building blocks of an event-driven architecture. They represent significant occurrences or changes in a system and encapsulate the relevant data and context. Events can be of various types, such as user actions, system state changes, or business transactions.
- Producers: Producers are components or applications responsible for generating and emitting events into the system. When specific conditions are met or certain actions occur, producers publish events to a central event bus or message broker.
- Message Broker: The message broker is a central hub in the event-driven architecture. It receives events from producers and distributes them to interested consumers. The broker ensures reliable event delivery and supports various messaging patterns, such as pub/sub (publish/subscribe) and point-to-point.
- Consumers: Consumers are components or applications that subscribe to specific types of events they are interested in processing. They receive events from the message broker and process them according to their business logic.
- Event Processors: Event processors are components responsible for handling events and executing the necessary actions or computations. They perform tasks such as updating databases, invoking external services, triggering workflows, or generating notifications.
- Event Handlers: Event handlers are specialized event processors that focus on specific types of events. They may perform domain-specific actions based on the event’s content and context.
- Event Bus: The event bus is a communication channel that connects producers and consumers in an event-driven architecture. It facilitates the decoupling of components, allowing them to interact without direct dependencies.
- Event Schema/Contracts: Event schema or contracts define the structure and format of events. They provide a standardized way for producers and consumers to understand and interpret events, ensuring compatibility across different systems.
- Event Registry: The event registry is a central repository that catalogs and manages all the events used within the architecture. It helps maintain a clear inventory of events, their definitions, and their usages.
- Event-driven Patterns: Event-driven architectures often employ various design patterns, such as event sourcing, CQRS (Command Query Responsibility Segregation), and sagas, to address specific challenges and enable advanced event processing scenarios.
By leveraging these key components, an event-driven architecture enables the seamless flow and processing of events throughout a system, promoting scalability, flexibility, and responsiveness in modern applications.
3. Patterns of Event-Driven Architecture
Here are the patterns of event-driven architecture for structuring systems for scalability and autonomy:
- Event Sourcing: In this pattern, the state of a system is derived from a sequence of events. Instead of storing the current state, the system maintains an event log that captures all changes. This allows the system to rebuild its state at any point and supports audibility and historical analysis.
- Command Query Responsibility Segregation (CQRS): CQRS separates the read and write operations of a system into different components. The “Command” side handles write operations, while the “Query” side handles read operations. This pattern improves performance, as read and write operations can be scaled independently to meet different demands.
- Event Notification: Event notification ensures that changes in one part of the system are communicated to other parts that need to be aware of those changes. Producers emit events, and interested consumers subscribe to receive and react to these events accordingly.
- Event Collaboration: This pattern promotes loose coupling and collaboration between different services or components. When a service wants to perform an action or request information from another service, it raises an event. Other services can subscribe to and respond to these events as needed.
- Event Choreography: Event choreography is a decentralized approach to coordination in an event-driven system. Services or components communicate directly with each other through events without a centralized controller, promoting flexibility and autonomy.
- Event-driven Messaging: Event-driven messaging involves the use of a message broker to facilitate communication between components. Producers publish events to the broker, and consumers subscribe to specific types of events to process them.
- Event-driven Workflow: In this pattern, events trigger workflows that orchestrate a series of actions across multiple services or components. It allows the system to respond dynamically to events and adapt to changing requirements.
- Event-driven Sagas: Sagas is a way to manage distributed transactions in an event-driven system. A saga represents a long-lived, multi-step transaction that is composed of a series of smaller, local transactions across different services. If a step fails, compensating events are used to undo the previous steps and maintain data consistency.
- Domain Events: Domain events capture significant changes within the business domain. They are used to trigger reactions and updates across various parts of the system, ensuring that all components are aware of relevant changes.
- Event-driven Microservices: Event-driven architecture is well-suited for microservices-based systems. Each microservice can independently produce and consume events, promoting autonomy and scalability while enabling loose coupling between services.
By employing these patterns, an event-driven architecture can be designed to handle large-scale systems with enhanced scalability, autonomy, and responsiveness.
4. Building a Kafka Event-Driven Architecture
Let us dive into a working example. We will set up Node.js on Windows and use Visual Studio Code as my preferred IDE.
4.1 Using Docker for Kafka
Docker is an important term that is often used in CI/CD platforms that packages and runs the application with its dependencies inside a container. If someone needs to go through the Docker installation, please watch this video.
4.1.1 Setting up Kafka on Docker
To set up the Kafka I will be using Docker and for that, I have prepared a simple stack.yml that will help to set up the Kafka and Zookeeper. The Kafka will be running on the default port i.e. 9092 but you’re free to change the configuration as per your setup.
stack.yml
services:
kafka:
container_name: kafka
environment:
KAFKA_ADVERTISED_HOST_NAME: localhost
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
image: wurstmeister/kafka
ports:
- "9092:9092"
zookeeper:
container_name: zookeeper
image: wurstmeister/zookeeper
ports:
- "2181:2181"
version: "3"
To get Kafka up and running we will trigger the following command – docker-compose -f /stack.yml up -d. If the images are not present in the host environment then they will be downloaded from the Dockerhub repository and the whole process might take a minute or two. Once done you can use the – docker ps command to confirm whether the container is running or not as shown in the below image.
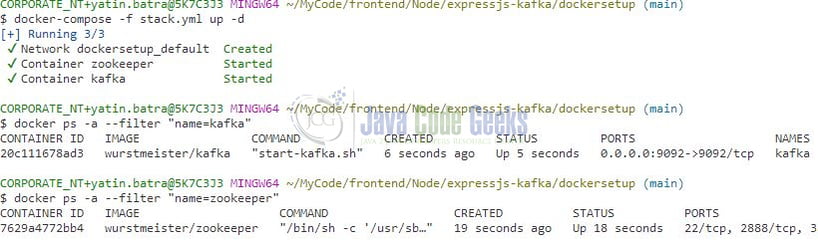
You can also use the following command – docker-compose -f /stack.yml up -d to clean up the created environment.
4.1.2 Create a Kafka Topic
To work with Kafka we need to set up a topic and for that, we will use the script provided by Kafka. Login to the Kafka docker container and navigate to the /opt/kafka/bin/ directory. From the location trigger the below command:
-- Create the topic kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 1 --partitions 1 --topic test-topic
Once the command will be executed successfully a Kafka topic will be created and a message will be shown on the console.

4.2 Working example
We will be creating a small express.js application that will bind to the Kafka setup running on Docker. We will use an endpoint that will be responsible for sending messages to the producer and a consumer that will read the messages from the Kafka topic and print it on the IDE console.
4.2.1 Setting up project dependencies
Navigate to the project directory and run npm init -y to create a package.json file. This file holds the metadata relevant to the project and is used for managing the project dependencies, script, version, etc. Replace the generated file with the code given below.
package.json
{
"name": "expressjs-kafka",
"version": "1.0.0",
"description": "Event-driven architecture in kafka",
"main": "app.js",
"scripts": {
"dev": "nodemon app.js",
"start": "node app.js",
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "javacodegeeks.com",
"license": "MIT",
"dependencies": {
"body-parser": "^1.20.2",
"express": "^4.18.2",
"kafka-node": "^5.0.0"
},
"devDependencies": {
"nodemon": "^3.0.1"
}
}
Once the file is replaced trigger the below npm command in the terminal window to download the different packages required for this tutorial.
Downloading dependencies
npm install
4.2.2 Setting up producer
The provided Node.js script sets up a Kafka producer using the kafka-node library. Kafka is a distributed streaming platform used for real-time data processing. The code imports the necessary kafka-node module and creates a Kafka client with a specified broker address. Then, a Kafka producer is initialized using the client to establish a connection with the broker. Event handlers are set up to handle “ready” and “error” events emitted by the producer. Once the producer is ready, a message is logged to indicate its readiness, and any errors encountered during its operation are logged as well. The producer instance is then exported as a module, allowing other parts of the application to use it for sending messages to Kafka topics. This script enables developers to integrate Kafka into their Node.js applications and leverage its capabilities for real-time data streaming and processing.
kafkaproducer.js
const kafka = require("kafka-node");
const kafkaClient = new kafka.KafkaClient({ kafkaHost: "localhost:9092" });
const producer = new kafka.Producer(kafkaClient);
producer.on("ready", () => {
console.log("Kafka producer is ready.");
});
producer.on("error", (err) => {
console.error("Error in Kafka producer:", err);
});
module.exports = producer;
4.2.3 Setting up a consumer
The provided Node.js script sets up a Kafka consumer using the kafka-node library. Kafka is a distributed streaming platform used for real-time data processing. The code imports the necessary kafka-node module and creates a Kafka client with a specified broker address. Then, a Kafka consumer is initialized using the client to establish a connection with the broker. The consumer is subscribed to a particular topic and partition, allowing it to consume messages from that topic. When the consumer receives a new message from Kafka, it logs the message value to the console. Additionally, the script handles any errors that may occur during the consumer’s operation and logs them accordingly. Finally, the consumer instance is exported as a module, making it available for other parts of the application to use for message consumption from the specified Kafka topic and partition.
kafkaconsumer.js
const kafka = require("kafka-node");
const kafkaClient = new kafka.KafkaClient({ kafkaHost: "localhost:9092" });
const consumer = new kafka.Consumer(kafkaClient, [
{ topic: "test-topic", partition: 0 }
]);
consumer.on("message", (message) => {
console.log("Received message from Kafka:", message.value);
});
consumer.on("error", (err) => {
console.error("Error in Kafka consumer:", err);
});
module.exports = consumer;
4.2.4 Setting up routes
The provided Node.js script is an Express application that sets up a router to handle HTTP POST requests for sending messages to a Kafka topic. It utilizes the express and body-parser modules to create a router that can parse JSON data in the request body. Additionally, it requires a custom producer module that exports a Kafka producer instance for message delivery (not shown here).
The router handles POST requests to the /send-message endpoint, extracting the message from the JSON data in the request body. It then creates a payloads array containing the Kafka topic and the message to be sent. The producer’s send() method is used to transmit the message to Kafka. If an error occurs during transmission, the router responds with a 500 status code and an error message. Otherwise, it responds with a 200 status code and a success message, indicating that the message was sent successfully.
routes.js
const express = require("express");
const bodyParser = require("body-parser");
const producer = require("./kafkaproducer");
const router = express.Router();
router.use(bodyParser.json());
router.post("/send-message", (req, res) => {
const message = req.body.message;
const payloads = [{ topic: "test-topic", messages: message }];
producer.send(payloads, (err, data) => {
if (err) {
console.error("Error sending message:", err);
res.status(500).json({ error: "Error sending message to Kafka" });
} else {
console.log("Message sent:", data);
res.status(200).json({ message: "Message sent successfully" });
}
});
});
module.exports = router;
This code can be integrated into an Express application to facilitate sending messages to a Kafka topic, making it suitable for building real-time data streaming applications.
4.2.5 Creating the main file
The provided file is a Node.js script that sets up an Express server to handle incoming HTTP requests. It imports the necessary modules, including express, routes, and kafkaconsumer. The script initializes the Express application, designates the server’s port as 6501, and defines the routes using the routes module. The kafkaconsumer module is also imported, which appears to handle Kafka consumer functionality, but the specific implementation is not shown in this snippet.
The script listens for the “ready” event emitted by the consumer, indicating that the Kafka consumer is ready to process messages. When the consumer is ready, it logs a message to the console. Finally, the server starts listening on the specified port (6501), and a confirmation message is logged to the console indicating that the server is running.
routes.js
const express = require("express");
const routes = require("./routes");
const consumer = require("./kafkaconsumer");
const app = express();
const PORT = 6501;
app.use("/", routes);
// require("./init");
consumer.on("ready", () => {
console.log("Kafka consumer is ready.");
});
// Start the server
app.listen(PORT, () => {
console.log(`Server is running on http://localhost:${PORT}`);
});
4.3 Run the Application
To run the application navigate to the project directory and enter the following command as shown below in the terminal from the project’s root location. The application will be started successfully on port number 6501 and will bind to the topic.
Run the application
$ npm run start
Once the application is started successfully open the Postman tool to import the below curl request. The request will contain a request body and will be sent to the /send-message endpoint. The application will intercept the incoming request and send the request payload to a Kafka topic via the producer.
Send message
curl -X POST -H "Content-Type: application/json" -d '{"message": "Hello, Kafka!"}' http://localhost:6501/send-message
Once the request from the postman tool is sent to the given endpoint and the 200 OK is returned the following logs will be shown on the IDE console. The logs will show that a message is sent to the Kafka topic and the consumer has listened to that message.
IDE console output
Message sent: { 'test-topic': { '0': 4 } }
Received message from Kafka: Hello, Kafka!
Message sent: { 'test-topic': { '0': 5 } }
Received message from Kafka: Hello, Kafka!
Message sent: { 'test-topic': { '0': 6 } }
Received message from Kafka: Hello, Kafka!
5. Use Cases
Kafka event-driven architecture provides a versatile and powerful solution for various use cases in modern application development and data processing. Here are some common use cases where Kafka excels as a distributed streaming platform:
- Real-time Stream Processing: Kafka’s ability to handle high-throughput event streams makes it ideal for real-time data processing and analytics. Applications can consume events in real time and perform actions, such as aggregations, filtering, and transformations, to derive valuable insights from the data as it flows through the system.
- Microservices Communication: Kafka serves as a communication channel between microservices in a distributed system. Microservices can publish and subscribe to events, enabling them to exchange information, coordinate actions, and maintain loose coupling between services.
- Log Aggregation: Kafka can act as a central log aggregation system, collecting log data from various services and applications. This centralized logging enables easier monitoring, debugging, and analysis of system behavior and performance.
- Event Sourcing: Kafka is well-suited for event sourcing patterns, where all changes to an application’s state are captured as events. These events can be replayed to reconstruct the application’s state at any point in time, providing a robust audit trail and ensuring data consistency.
- Internet of Things (IoT) Data Ingestion: Kafka’s ability to handle high-throughput and low-latency data streams makes it an excellent choice for IoT data ingestion. It can efficiently process and store massive amounts of data generated by IoT devices in real time.
- Real-time Monitoring and Alerts: Kafka enables real-time monitoring of various metrics and events. It can feed data into monitoring systems, allowing them to generate alerts and trigger actions based on predefined thresholds or patterns.
- Data Replication and Synchronization: Kafka can be used for data replication and synchronization across multiple data centers or cloud environments. It ensures data consistency and availability, making it valuable for disaster recovery and data backup scenarios.
- Clickstream Data Processing: Kafka is frequently used to handle clickstream data generated by web applications and websites. It can ingest and process user interaction events, enabling businesses to analyze user behavior and make data-driven decisions.
- Machine Learning Pipelines: Kafka can be integrated into machine learning pipelines to stream data for model training, evaluation, and prediction. This real-time data flow ensures that machine learning models stay up-to-date with the latest information.
- Event-Driven ETL (Extract, Transform, Load): Kafka can be a fundamental component of event-driven ETL pipelines, enabling efficient data extraction, transformation, and loading into various data systems and databases.
6. Conclusion
Building an Event-Driven Architecture Using Kafka allows developers to create scalable and efficient systems that handle various data processing and messaging requirements. Kafka, as a distributed streaming platform, has proven to be a robust and reliable solution for handling real-time event streaming at scale.
The event-driven architecture enabled by Kafka offers several benefits:
- Scalability: Kafka’s distributed nature allows it to scale horizontally, making it suitable for handling massive volumes of events and high-throughput scenarios. This architecture enables systems to grow and adapt to changing demands effortlessly.
- Fault Tolerance: Kafka’s replication and partitioning mechanisms ensure data durability and availability even in the face of node failures. This fault-tolerance capability makes the event-driven architecture resilient and highly available.
- Loose Coupling: By decoupling services through events, different components can operate independently, reducing dependencies between services. This promotes a flexible and modular system design.
- Real-time Data Processing: Kafka’s ability to process and stream events in real-time allows applications to react instantly to changes and provide real-time insights.
- Data Integration: Kafka serves as a central data hub, facilitating data integration across multiple services and systems. This makes it easier to share and process data across the entire organization.
By leveraging the Kafka ecosystem and its client libraries, developers can implement a wide range of use cases, such as data synchronization, log aggregation, stream processing, and event-driven microservices. The event-driven architecture allows developers to build systems that are responsive, flexible, and capable of handling complex data flows efficiently.
7. Download the Project
This was a tutorial to implement the event-driven architecture in Kafka.
You can download the full source code of this example here: Building an Event-Driven Architecture Using Kafka
