In this post, we feature a comprehensive tutorial on Big Data Pipeline.
1. Big Data Pipeline – Background
Hadoop is an open source data analytics platform that addresses the reliable storage and processing of big data. Hadoop is suitable for handling unstructured data, including the basic components of HDFS and MapReduce.
What is HDFS? HDFS provides a flexible data storage system across servers.
What is MapReduce? When technology is sensed, a standardized data processing flow position is provided. Data reading and data mapping (the Map), uses a key-value data rearrangement, and simplified data (the Reduce) to give the final output.
What is the Amazon Elastic Map Reduce (EMR)? The Amazon Elastic Map Reduce is a hosted solution that runs on a network-scale infrastructure consisting of Amazon Elastic Compute Cloud (EC2) and Simple Storage Service (S3). If you need one-time or unusual big data processing, EMR may be able to save you money. However, EMR is highly optimized to work with the data in S3 and has a higher latency.
Hadoop also includes a set of technology extensions, including Sqoop, Flume, Hive, Pig, Mahout, Datafu, and HUE.
What is Pig? Pig is a platform used to analyze big data sets that consist of a high-level language that expresses data analysis programs and an infrastructure for evaluating these programs.
What is Hive? Hive is a data warehousing system for Hadoop that provides a SQL-like query language that makes it easy to aggregate data, specific queries, and analysis.
What is Hbase? Hbase is a distributed and scalable big data repository that supports random and real-time read/write access.
What is Sqoop? Sqoop is a tool designed to efficiently transfer bulk data for data transfer between Apache Hadoop and structured data repositories such as relational databases.
What is Flume? Flume is a distributed, reliable, and available service for efficiently collecting, summarizing, and moving large amounts of log data.
What is ZooKeeper? ZooKeeper is a centralized service that maintains configuration information and naming. It also provides distributed synchronization, and grouping services.
What is Cloudera? Cloudera is the most popular Hadoop distribution and has the most deployment cases. Cloudera provides powerful deployment, management, and monitoring tools. It is also developed and contributed to the Impala project that can process big data in real time.
What does Hortonworks use? Hortonworks uses a 100% open source Apache Hadoop provider. Many enhancements have been developed and submitted to the core backbone, which enables Hadoop to run locally on platforms including Windows Server and Azure .
What does MapR do? MapR allows people to get better performance and ease of use while supporting native Unix filesystems instead of HDFS. MapR provides high availability features such as snapshots, mirroring, and stateful failover. Leading the Apache Drill project is an open source implementation of Google’s Dremel, which is designed to perform SQL-like queries to provide real-time processing.
2. Principle
Data Storage
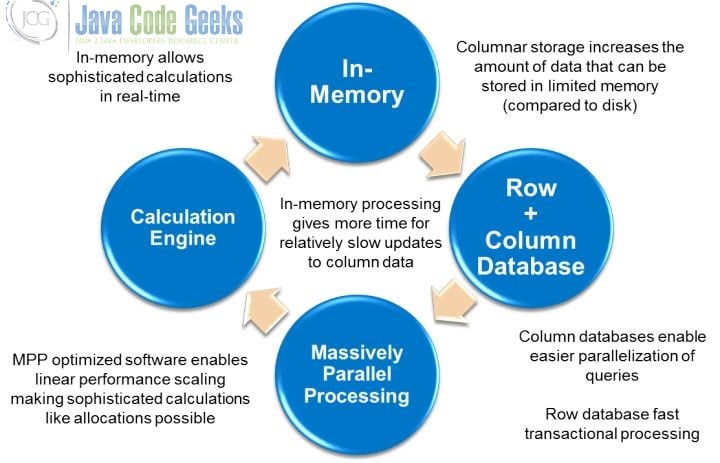
The goal of Hadoop is to be a reliable system that supports large scale expansion and easy maintenance. There is a locality in the computer, as shown in the figure. Access from bottom to top is getting faster and faster, but storage is more expensive.
Relative to memory, disk and SSD need to consider the placement of data because performance will vary greatly. The benefits of disk are persistence, the unit cost is cheap, and it is easy to back up. But while the memory is cheap, many data sets can be considered directly into the memory and distributed to each machine, some based on key-value, with Memcached used in the cache. Persistence of the memory can be written into the log (RAM with battery), written to the log in advance, or periodically Snapshotted or copied in another machine memory. The state needs to be loaded from the disk or network when rebooting. In fact, writing into the disk is used in the append log, which reads it directly from the memory. Like VoltDB and MemSQL, RAMCloud is relationally based on an in-memory database, and can provide high performance and solve the trouble of disk management before.
HyperLogLog & Bloom Filter & CountMin Sketch
The HyperLogLog is an algorithm applied to big data. The general idea of it is to process the input sequentially with a set of independent hash functions. HyperLogLog is used to calculate the cardinality of a large set (how many reasonable different elements there are in total), and is used to count the hash value: how many consecutive 0s are for the high-order statistics. Then, it uses the lower-order value as the data block. BloomFilter calculates and flags the values of all hash functions for the input during the pre-processing stage. When looking for a particular input that has occurred, look up the corresponding value of the hash function of this series. For BloomFilter, there may be False Positive, but there is no possibility of False Negative. BloomFilter can be thought of as looking up a data structure with or without data (whether the frequency of the data is greater than 1). CountMin Sketch goes one step further on BloomFilter. CountMin Sketch can be used to estimate the frequency of an input (not limited to greater than 1).
3. CAP Theorem
There are three characteristics of the CAP Theorem: consistency, availability, and network partitioning. There are many trade-offs in designing different types of systems, as well as many algorithms and advanced theories in distributed systems. These algorithms and advanced theories in distributed systems include the Paxos algorithm, Cassandra study notes protocol, Quorum (distributed system), time Logic, vector clocks (fourth of consistency algorithms: timestamps and vector diagrams), Byzantine generals, two-stage commits, etc.

4. Technical Articles
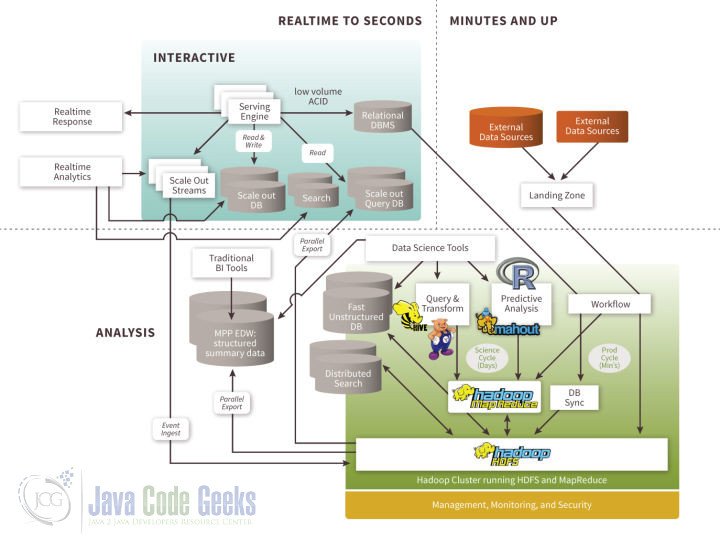
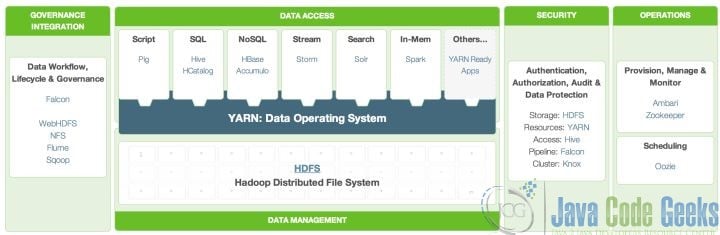
Depending on the delay requirements (SLA), the amount of data storage and updates, the need for analysis, and the architecture of big data processing also require flexible design. The figure below depicts big data components in different areas.
The technology of big data still needs to mention Google and Google’s new three carriages, Spanner, F1, and Dremel.
Spanner: Google’s internal database with highly scalable, multi-version, global distributed and synchronous replication features. Google’s internal database has support for externally consistent and distributed transactions. Goals spanning hundreds of data centers worldwide are designed, covering millions of servers, including 10,000 billions of records!
F1: Built Spanner (read above), using Spanner as a feature-rich foundation on top. F1 also provides a distributed SQL, transactional consistency of the secondary index and other functions. In the advertising business ran by AdWord, the old manual before MySQL Shard program was successfully replaced.
Dremel: A method for analysis of information. Dremel can run on thousands of servers. Similar to the use of SQL language, the size of the network can handle massive data at very high speeds (PB magnitude).
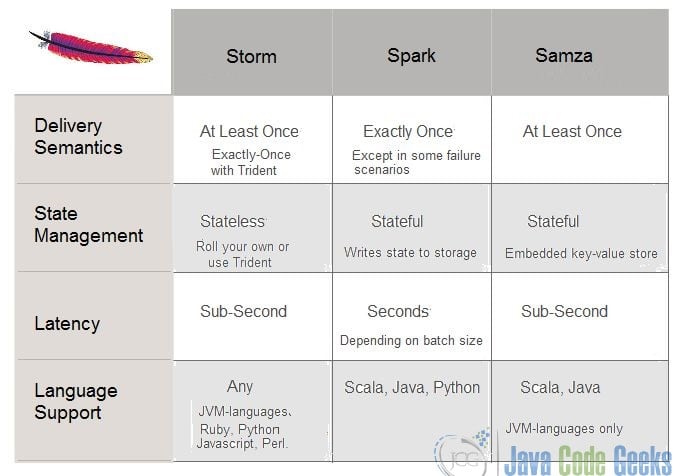
5. Spark
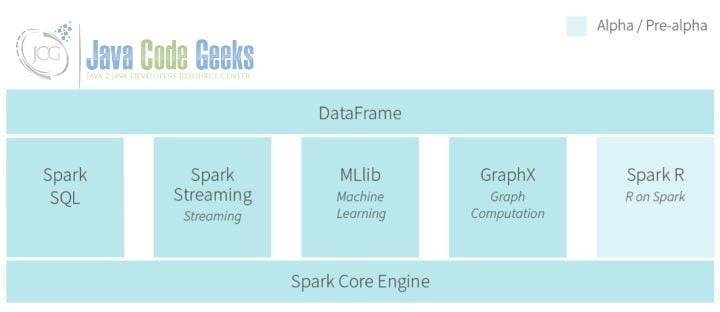
The main intent of Spark, the hottest big data technology in 2014, is to complete faster data analysis based on in-memory calculations. At the same time, Spark supports graph and streaming calculation, along with batch processing. The core members of Berkeley AMP Lab formed the company Databricks to develop Cloud products.
6. Flink
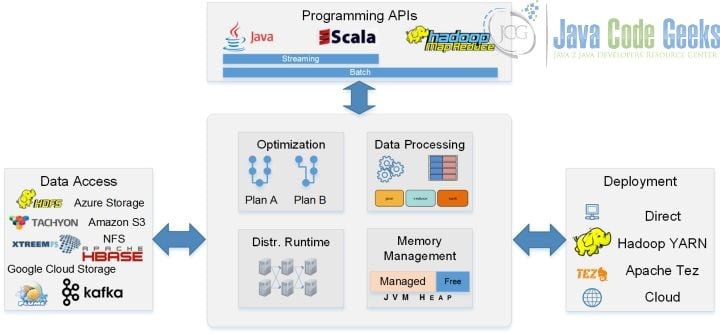
With Flink, a method similar to SQL database query optimization is used, which is the main difference between Flink and the current version of Apache Spark. It can apply a global optimization scheme to a query for better performance.
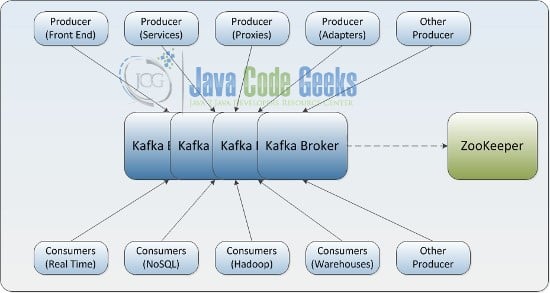
7. Kafka
Kafka is described as LinkedIn’s “Central Nervous System,” and manages the flow of information gathered from various applications, which are processed and distributed thoroughly. Unlike traditional enterprise information queuing systems, Kafka processes all data flowing through a company in near real-time, and has established real-time information processing platforms for LinkedIn, Netflix, Uber and Verizon. The advantage of Kafka is its near real-time.
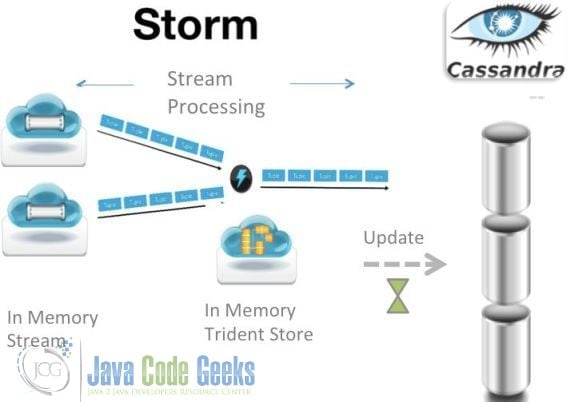
8. Storm
Storm is Twitter’s real-time computing framework that can handle five billion sessions a day in real time. The so-called stream processing framework is a distributed, highly fault-tolerant and real-time computing system. Storm makes continuous stream computing simple. Storm is often used in real-time analytics, online machine learning, continuous computing, distributed remote calls, and ETL .
9. Heron
Heron has been well-versed on Twitter for more than half a year. Heron is suitable for very large-scale machines and clusters of more than 1,000 machines. It has a better performance in terms of stability. In terms of resource usage, cluster resources can be shared with other programming frameworks, but the topology level will waste some resources.

10. Samza
Samza is the main stream computing framework of LinkedIn. When compared with other similar Sparks, Storm is different. Samza is integrated with Kafka as a primary storage node and intermediary.
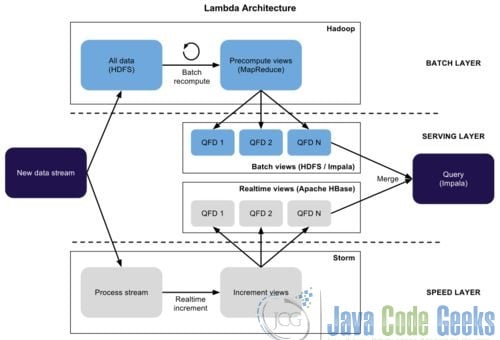
11. Lambda Architecture
The main idea of the Lambda Architecture is to use batch architecture for high latency but large data volume. It also uses streaming for real-time data. Framework is created, and then surface layer is built on top to merge the data flow on both sides. This system can balance the real-time efficiency and batch scale. It is adopted by many companies in the production system
12. Summingbird
Twitter developed Summingbird, and Summingbird’s complete program runs in multiple places. Summingbird also connects batch and stream processing, and reduces the conversion overhead between them by integrating batch and stream processing. The figure below explains the system runtime
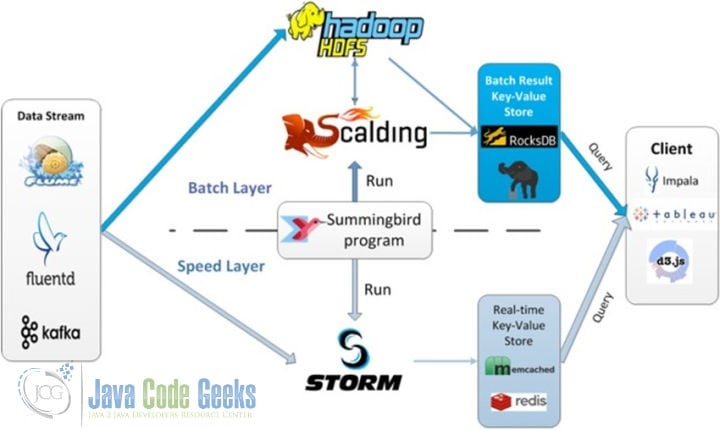
13. NoSQL
Data is traditionally stored in a tree structure (hierarchy), but it is difficult to represent a many-to-many relationship. Relational databases are the solution to this problem, but in recent years, relational databases have been found to be ineffective. New NoSQL appears like Cassandra, MongoDB, and Couchbase. NoSQL is also divided into the category’s document type. These categories consist of graph operation type, column storage, key-value type, and different systems solve different problems. There is no one-size-fits-all solution.

14. Cassandra
In the architecture of big data, Cassandra’s main role is to store structured data. DataStax’s Cassandra is a column-oriented database that provides high availability and durability through a distributed architecture. It implements very large scale clusters and provides a type of consistency called “final consistency,” which means that the same database entries in different servers can have different values at any time.
15. SQL on Hadoop
There are many SQL-on-Hadoop projects in the open source community that focus on competing with some commercial data warehouse systems. These projects include Apache Hive, Spark SQL, Cloudera Impala, Hortonworks Stinger, Facebook Presto, Apache Tajo and Apache Drill. Some projects are based on Google Dremel design.
16. Impala
Impala is the Cloudera company leading the development of a new type of query system that provides SQL semantics. Impala can query data stored in Hadoop’s HDFS and HBase in PB magnitude data.
17. Drill
The open source version of Dremel-Drill is similar to the Apache community. Dremel-Drill is a distributed system designed to interactively analyze large data sets.
18. Druid
Druid is open source data storage designed for real-time statistical analysis on top of big data sets. This system aggregates a layer for column-oriented storage, a distributed and nothing-shared architecture, and an advanced index structure to achieve arbitrary exploration and analysis of billion-row-level tables within seconds.
19. Berkeley Data Analytics Stack
BDAS is a more grand blueprint in the Berkeley AMP lab. There are many star projects in it besides Spark that include:
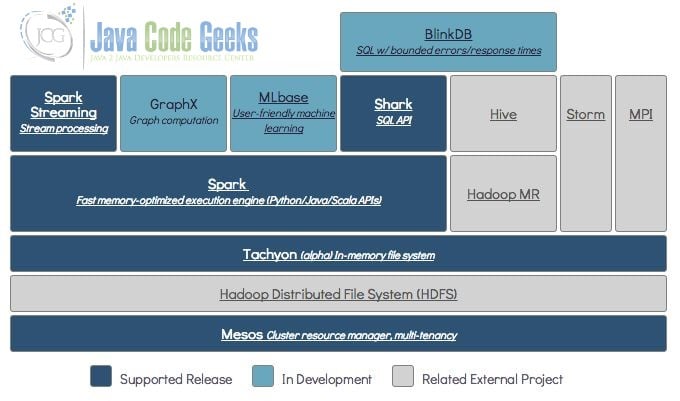
Mesos: A resource management platform for distributed environments that enable Hadoop, MPI and Spark jobs to be executed in a unified resource management environment. Mesos is very good for Hadoop 2.0 support, and Mesos is used by Twitter and Coursera.
Tachyon: A highly fault-tolerant distributed file system that allows files to be reliably shared in the cluster framework at the speed of the memory, just like Spark and MapReduce. The current development is very fast, and some people believe it is even more amazing than Spark. Tachyon has established the startup Tachyon Nexus.
BlinkDB: A massively parallel query engine that runs interactive SQL queries on massive amounts of data. It allows the user to increase the query response time by weighing the data precision. The accuracy of the data is controlled within the allowable error range.
Cloudera: A solution proposed by Hadoop Big Brother.
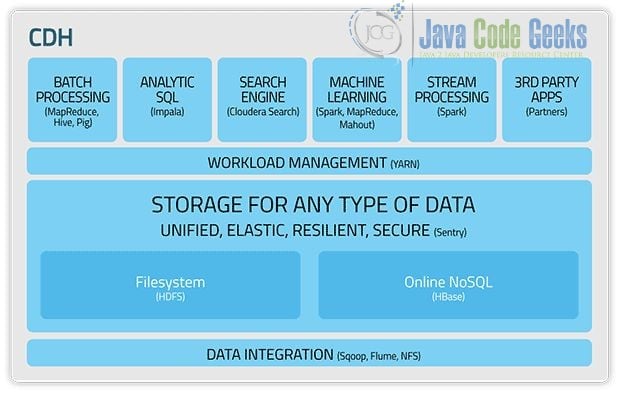
HDP (Hadoop Data Platform): Hortonworks’ proposed architecture selection.
Redshift: Amazon RedShift is a version of ParAccel. It is a massively parallel computer and a very convenient data warehouse solution. Amazon RedShift is also a SQL interface and provides seamless connection with various cloud services. Amazon RedShift is fast and provides very good performance at TB to PB level. It is also used directly and supports different hardware platforms. If you want to be faster, you can use SSD.
20. Conclusion
In conclusion, Hadoop is an open source data analytics program that addresses the reliable storage and processing of big data. The goal of Hadoop is to be a reliable system that supports large-scale expansion and easy maintenance. Hadoop includes a set of technology extensions that are described in depth above. To add on, New NoSQL is shown in different categories, and is divided according to the category’s document type. An in depth tutorial regarding Big Data Pipeline is described above.
