In this post, we feature a comprehensive tutorial on AWS Lambda Best Practices. We will make an introduction on how to create Lambda scaling application for the best practice.
1. AWS Lambda Best Practices
1.1 What is Lambda?
Lambda is a serverless data processing and an event driven platform provided by Amazon as part of Amazon Web Service.
Thinking about software development in a virtual environment, we just need to upload code and Lambda takes care of everything required to run and scale out code with high availability.
Our code could be automatically triggered via other AWS services or could be used as a customized functionality used by any web or Mobile application.
2. Lambda Core Features
- Scalability-We pay by Running amount and CPU usage.
- Short Computational Code- to run code snippets “IN THE CLOUD” serverless and continuing auto scaling.
- None Hosted web site and easy integrated with other service at no charge.
- Development environment creation and replication.
- Provide monitoring and notification service.
- Provide recovering service.
3. Lambda integration
Some services do not talk to other services in real word, however, Lambda could act like glue between practically anything.
From the perspective of Data Processing, Lambda sits there and could be triggered by other services sending data into it, such as S3, DynamoDB, Kinesis, SNS and CloudWatch, or it could be orchestrated into workflows via AWS step Functions. So, Lambda allows us to build a variety of real-time serverless data processing systems.
From Real-Time File Processing perspective, Amazon S3 could trigger Lambda to process data immediately per any file upload. such as thumbnail images, videos, index files, process or validation logs, Lambda aggregates and filters data in real -time.
From the perspective of Real-Time Streaming processing, AWS Lambda pairs with Amazon Kinesis to process real-time streaming data for website click streams, application logs, security compliance needs in real-time, Feeds from loT sensors monitoring devices, temperature and weather change, and any event-driven and event-source solutions.
4. Lambda -GLUE Engine
Lambda not only applies to big data, but can also be used to build a serverless website. Although Lambda is not applicable to dynamic websites, if we just need some static html and ajax call embedded within that html, then we could serve that from S3, leaving only the ajax call to be dealt with. For the ajax call, we could possibly have API in Amazon Gateway serve as a wall between clients and our systems. For example, suppose we have a website and the user needs to login. The login request will go through the Gateway API, then be sent to Lambda. Lambda will handshake with Amazon Cognito, and Cognito will issue a token if the criteria met. Then, Lambda will format the result and send it back to the website. Thus, Lambda glues Amazon Cognito and external website as a backend. Let’s say we have a chat application or user login. Amazon Gateway API will validate the login info, then send a request to Lambda. Lambda says “OK, I need to get the chat history for this user,” then provides the user ID and communicate with DynamoDB, fetch the chat history of the user ID, and send back to the user via Gateway API. So here we see Lambda often fits in as a glue between different services. As following is the serverless website architecture diagram:
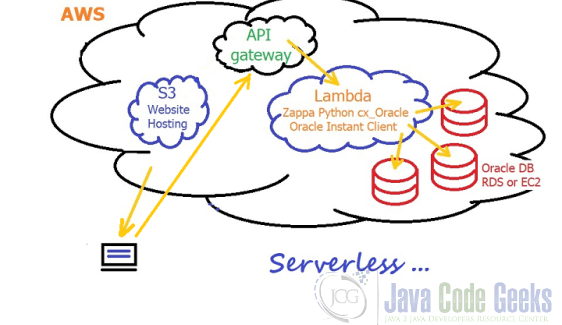
Speaking of the real time streaming, let’s say we have a predefined object in S3. Whenever a new instance created, the Lambda will be triggered and parser out this piece of information and send to redshift. The same situation is prevalent with DynamoDB. Any data change in the DynamoDB table could trigger the Lambda service as well. That allows real time event driven data processing. Lambda could integrate with kinesis Streams by reading records from the stream and later process them accordingly. Under the hood, Lambda is actually pulling the streams periodically and parse as batch process. Kinesis is not pushing data into Lambda. Lambda could integrate with AWS loT and Kinesis Data Firehose as middleware with customized API or Amazon API. Generally speaking, as long as AWS Services have the same account, Lambda could communicate with all of the services via IAM. the following diagram showcases the event-driven workflow which transforms and loads data to the Amazon Redshift.
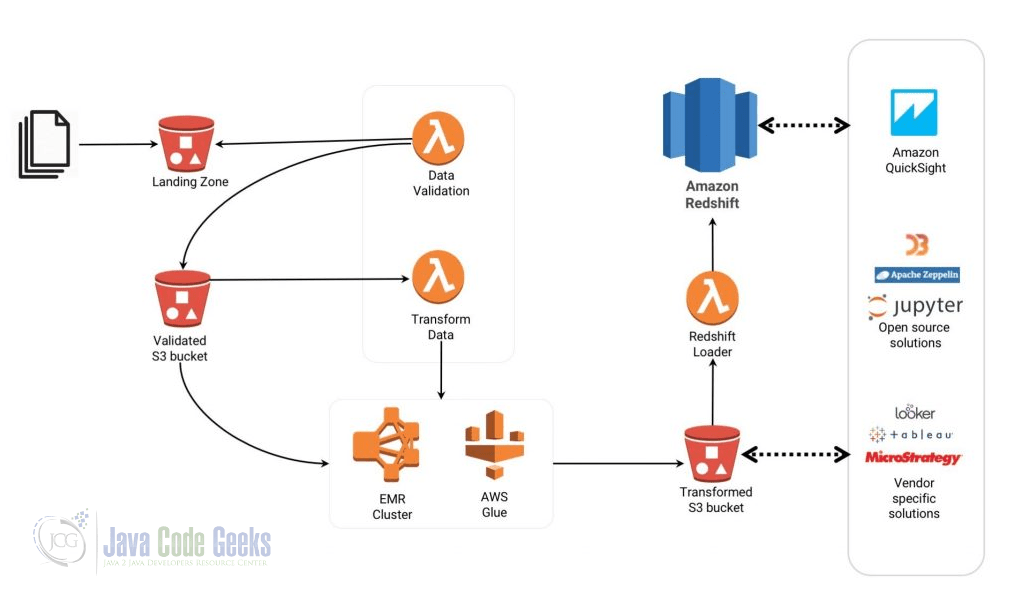
Let’s dive deeper. Lambda could glue with AWS ElasticSearch Services. Imagine that we have some data sent into S3 like data lakes, etc. That object of S3 could trigger the Lambda function, which turns around and processes the data and sends it to ElasticSearch service to process and analyze it. Lambda could glue with AWS Data PipeLine in the same way as S3 new data can come in and trigger Lambda to kick off the AWS Data Pipeline automatically to process the data further. The following example is a Python Lambda function that takes requests from API Gateway, querying through Amazon ES and returns results:
import boto3
import json
import requests
from requests_aws4auth import AWS4Auth
region = '' # For example, us-west-1
service = 'es'
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
host = '' # For example, search-mydomain-id.us-west-1.es.amazonaws.com
index = 'movies'
url = 'https://' + host + '/' + index + '/_search'
# Lambda execution starts here
def handler(event, context):
# Put the user query into the query DSL for more accurate search results.
# Note that certain fields are boosted (^).
query = {
"size": 25,
"query": {
"multi_match": {
"query": event['queryStringParameters']['q'],
"fields": ["fields.title^4", "fields.plot^2", "fields.actors", "fields.directors"]
}
}
}
# ES 6.x requires an explicit Content-Type header
headers = { "Content-Type": "application/json" }
# Make the signed HTTP request
r = requests.get(url, auth=awsauth, headers=headers, data=json.dumps(query))
# Create the response and add some extra content to support CORS
response = {
"statusCode": 200,
"headers": {
"Access-Control-Allow-Origin": '*'
},
"isBase64Encoded": False
}
# Add the search results to the response
response['body'] = r.text
return response
Last but not least, I would like to talk about the Lambda parallel operation. Even though Lambda can basically communicate with any application, Lambda is stateless, and not able to share the data among services. Let’s say there are thousands of parallel jobs in Lambda, and each job inserts records into ElasticSearch. The ES cluster would not be able to handle the heavy load of concurrent connections. Therefore, the recommended solution is to integrate Docker with Lambda. Docker would iterate over the S3 datas, absorb each one and pipe them all into Kinesis Firehose. Firehose transforms the payload into real time streams and output to ElasticSearch. Another alternative is to dockerize the customized logic in Lambda, deploy to either ECS, kubernetes or even few more EC2 instances to process S3 files asynchronously. Lambda is triggered by event notifications, and the corresponding event ID would be put into queue. Then, Lambda would horizontally scalable indexing nodes or docker, picking off messages and bulk index into ElasticSearch.
5. Lambda -Anti-Patterns
Lambda would not be a good solution for the following instances:
- Long Running applications
- Dynamic Web Sites
- Stateful applications
6. AWS Lambda CloudWatch -Metrics
CloudWatch serves as a metric repository. Metric is the fundamental concept in CloudWatch which represents time-ordered set of data points. Metrics are uniquely defined by name space, name, or dimensions.
By creating CloudWatch Event rules, you can monitor and create Lambda functions for processing. Two general scenarios as following:
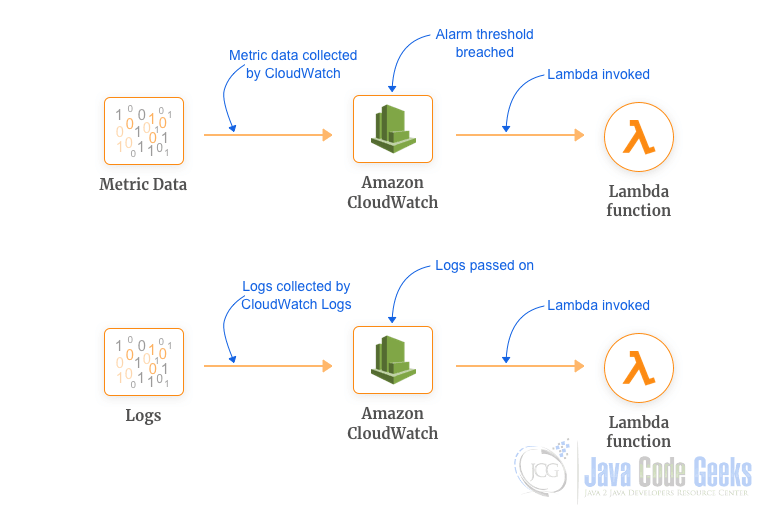
AWS Lambda namespace includes the following metrics:
- Invocations (Units: count) which measure the number of times an API invoked in response to an event. Lambda onlys sends these metrics to CloudWatch if they have a non-zero value.
- Errors (Units: count) which measure the number of invocation attempts that failed due to errors that repose Code(4**), and could be used for exception handling, unhandled exception force code to Exist, TimeOuts, out of memory, etc.
- Durations (Units: Milliseconds) which measure the elapsed from the start to end of executions.
- Throttles(Units: count) which measure the number of Lambda functions invocation attempts that are throttled due to invocation rates exceeding customized concurrent limits with Error code 429. Retry succeed attempts could be triggered per invocation failure.
- IteratorAge(Units: Milliseconds) which are emitted for stream-based invocation only such as Amazon Kinesis stream or DynamoDB, age is the difference between time when Lambda received the batch and the time the last record in the batch was written to the stream.
- Concurrent Executions(Units: count) which are emitted as an aggregate metric for all functions in the account, or for functions that have a custom concurrency limit specified.
7. AWS Lambda Best Practices – Summary
To summarize the information above, in this article, we discussed the high and lower level of Lambda, the integration with Lambda, Lambda Promises, Anti-Patterns and Lambda-CloudWatch metrics as well as the cost of Lambda.
Thank you all for reading this!
8. Download the Source Code
This was an example of a Python Lambda function that takes requests from API gateway, querying through Amazon ES and returns results.
You can download the full source code of this example here: AWS Lambda Best Practices Tutorial
