In this tutorial, we will take a look at the Apache Spark Architecture.
1. Introduction
Apache Spark was created in UC Berkeley’s AMPLab in 2009. It was created by Matei Zaharia. It was open-sourced in 2010 with a BSD license. Apache acquired Spark in 2013. It became a popular project in the Apache program in 2014.
Apache Spark is based on a cluster computing framework. It is used for big data processing to give real-time results. The key feature is the in-memory cluster which helps in providing greater performance. It provides a programming interface for creating clusters. The data processing can be parallelized and it is fault-tolerant. Different performance-intensive tasks like batch applications, iterative algorithms, queries, and streaming can be processed as jobs on Apache Spark.
2. Apache Spark
Apache Spark is open source and has features related to machine learning, SQL query processing, streaming, and graph processing. Apache Spark is based on a layered architecture that has loosely coupled components and layers. Apache spark supports two types of datasets which are Resilient Distributed Dataset (RDD) and directed acyclic graph (DAG).
Resilient Distributed Dataset has computation executors. They can support multiple languages such as Java, Scala, and Python. They are immutable, distributed, and fault-tolerant. These datasets can be spread across multiple nodes. Directed Acyclic Graph has a set of events which are tasks. A graph has edges and vertices. RDDs are vertices and operations are edges. Each operation can operate on the sequence’s different areas.
2.1 Prerequisites
Java 8 is required on the Linux, Windows, or Mac operating systems. Apache spark 3.0.1 can be used from the apache website. It will be based on Hadoop 2.7
2.2 Download
You can download Java 8 from the Oracle web site. Apache Spark can be downloaded from the apache web site.
2.3 Setup
2.3.1 Java Setup
Below are the setup commands required for the Java Environment.
Setup
JAVA_HOME="/desktop/jdk1.8.0_73" export JAVA_HOME PATH=$JAVA_HOME/bin:$PATH export PATH
2.3.2 Spark Setup
You need to unzip the file spark-3.0.1-bin-hadoop2.7.tgz after downloading.
2.4 Apache Spark Features
Apache spark is performant and has 100X benchmark relative to Hadoop MapReduce for Big Data Processing. Controlled partitioning is another technique for high performance. Spark has caching capability and can persist to the disk. It can be deployed using Hadoop’s YARN, Mesos, and Spark’s Cluster Manager. Spark provides real-time speed and low latency due to its in-memory cluster manager. Spark has APIs in different languages such as Java, Python, Scala, and R. It has a programming shell in Python and Scala.
2.5 Apache Spark Architecture
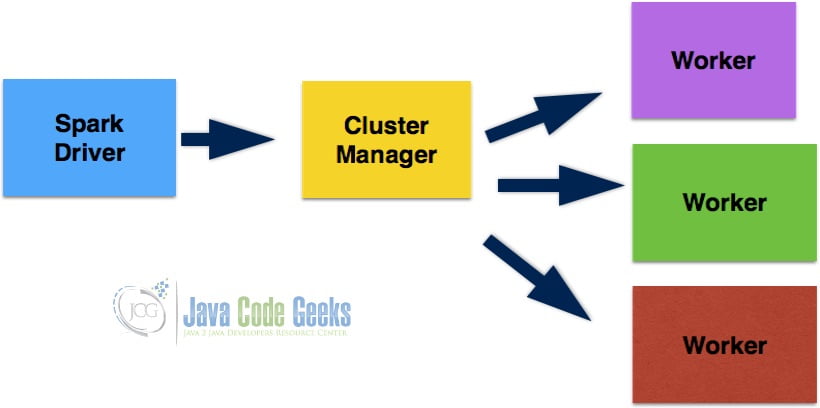
Apache Spark is based on Master and Slave Architecture. The master node has the driver which executes the application. The driver can be executed as the shell. Spark Context is created by the driver. All data operations are executed using the Spark context. The driver converts the application code into a DAG which has actions and transformations. The driver can execute pipelining transformations. DAG is transformed into an execution plan which has multiple stages. An execution plan has tasks that are physical execution units. Tasks are sent to the cluster. Resources are negotiated using the cluster manager by the driver. Executors which are worker nodes are spawned by the cluster manager. Tasks are sent to the worker nodes based on the data. Work nodes register themselves with drivers.
2.6 Apache Spark Ecosystem
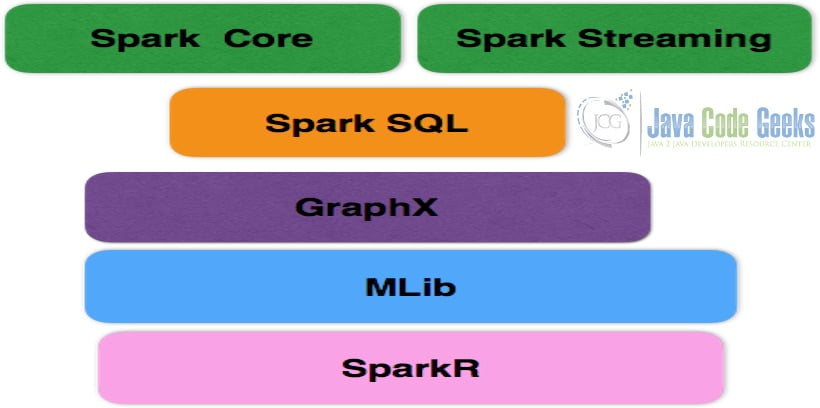
Apache Spark Ecosystem has different components such as Spark SQL, Spark Streaming, MLib, GraphX, and Core API Components. Spark Core is the data processing engine for distributed and parallel big data processing. The core has packages for streaming, SQL, and machine learning. Spark Core manages memory, fault recovery, scheduling, distributing, and job monitoring. Spark Streaming helps in high-performance and real-time streaming. It is fault-tolerant and provides high throughput by processing real-time data streams. Spark SQL helps in relational database processing using programming API. It supports SQL and Hive Query Language. GraphX is used for the parallel processing of data graphs. It is based on RDD. Spark MLib is the machine learning component in the Spark framework. Spark R package helps in data operations such as selection, filtering, and aggregation using the R language.
2.7 Supported Datasets
Apache spark supports the below dataset’s types:
- Resilient Distributed Dataset (RDD)
- Directed Acyclic Graph (DAG)
2.7.1 Resilient Distributed Dataset (RDD)
RDD type datasets are resilient, distributed, and partitioned data. They are the building blocks of the spark framework. RDD is abstracted over the distributed data collection. The operations on RDD are immutable and lazy. RDD type datasets are split into data chunks. These data chunks have a key. They can recover after failure easily since the data chunks are replicated across multiple worker nodes. If one of the worker nodes fails, the other one can pick up the data chunk to be processed. RDD operations are immutable as the state of the object cannot be changed after creation. The object’s state can be transformed. RDD type datasets are split into logical partitions which are used for parallel data processing on cluster nodes.
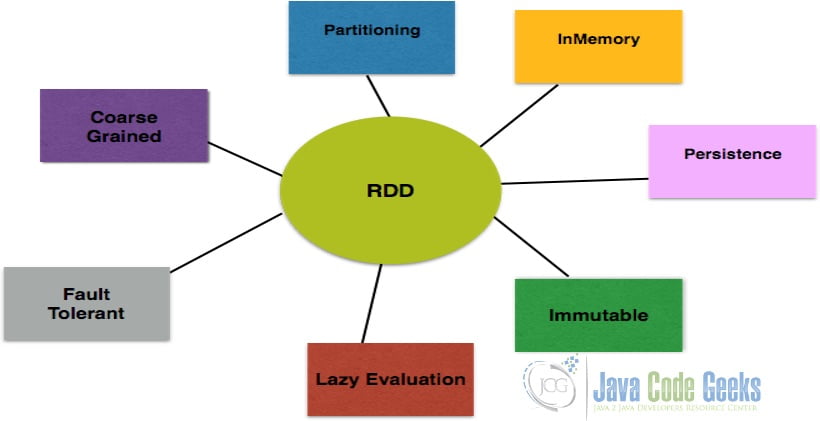
RDDs can be created using external storage-based data sets from HDFS, HBase, and shared File system. RDD supports transformations and actions.
2.7.2 Directed Acyclic Graph (DAG)
DAG is a directed graph-based data set. A graph is a set of nodes linked by branches. A directed graph has branches from one node linked to another. If you start from one of the DAG nodes through the branches, one will never visit the traversed node. The DAG-based data set has a set of operations created by the Spark Driver. Spark creates an execution plan from the application code. DAG Scheduler finishes the job execution stage wise. Jobs are assigned to the task scheduler and executed in minimum time. The task scheduler gets the cache status and tracks the RDDs and DAG operations. Failure can be recovered easily as the data is replicated in every worker node.
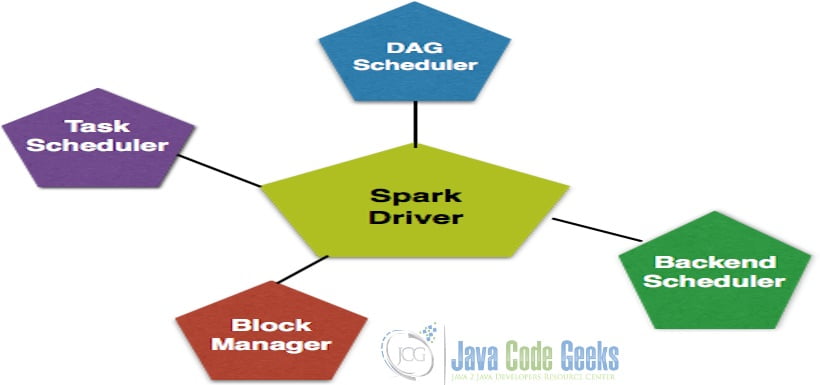
2.8 Spark Components
Spark framework has components listed below:
- Cluster Manager
- Master Node
- Worker Node
Spark has master and slave nodes which are Master and Worker nodes. The cluster manager helps in creating the daemons and binding them.
2.8.1 Master Node
Spark framework has the master node which acts as a Hub for managing. The master node creates Spark Context which can perform data operations. The driver has components listed below:
- DAG Scheduler
- Task Scheduler
- Backend Scheduler
- Block Manager
Driver talks to the cluster manager to schedule the tasks. A job is divided into different task which are distributed across the worker nodes. RDD is distributed across worker nodes and cached across the nodes.
2.8.2 Worker Node
Worker Node is used for task execution by the master node. A single master node has multiple worker nodes. Work Nodes execute on the RDD partitions and computational output is provided by the Spark Context. The worker nodes can be increased based on the data size. They help in splitting the jobs into more partitions and execute them. Worker nodes can help in caching the data and the tasks.
2.9 Spark Functions
Apache Spark has support for the functions listed below:
- Map Function
- Filter Function
- Count Function
- Distinct Function
- Union Function
- Intersection Function
- Cartesian Function
- SortByKey Function
- GroupByKey Function
- ReducedByKey Function
- CoGroup Function
- First Function
- Take Function
A sample java program that shows the usage of some of the above functions is shown below. A detailed example is discussed in this javacodegeeks article.
Sample java code
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class SparkExampleRDD {
public static void main(String[] args) {
if (args.length == 0){
System.out.println("No file provided");
System.exit(0);
}
String filename = args[0];
// configure spark
SparkConf sparkConf = new SparkConf().setAppName("Word Count").setMaster("local").set("spark.executor.memory","2g");
// start a spark context
JavaSparkContext sc = new JavaSparkContext(sparkConf);
JavaRDD inputFile = sc.textFile(filename);
JavaRDD wordsList = inputFile.flatMap(content -> Arrays.asList(content.split(" ")).iterator());
JavaPairRDD wordCount = wordsList.mapToPair(t -> new Tuple2(t, 1)).reduceByKey((x, y) -> (int) x + (int) y);
wordCount.saveAsTextFile("Word Count");
}
}
3. Summary
Apache Spark is based on Hadoop MapReduce. It is in-memory based and hence it is better compared to the other Big data frameworks. Apache Spark is fast in batch processing and data streaming. Spark has a DAG scheduler, query optimizer, and execution engine. It is easy to develop applications in Java, Scala, Python, R, and SQL for Apache Spark. It has an analytics engine that is lightweight for big data processing. It is portable and deployable on Kubernetes, Cloud, Mesos, and Hadoop. The operations in a typical Apache Spark program are Loading input to an RDD Task, Preprocessing Task, Mapping Task, Reducing Task, and Saving task.
4. Download the Source Code
You can download the full source code of this example here: Apache Spark Architecture Tutorial
