In this article, we will discuss the Java Tree Data structure.
1. Introduction
Tree is a hierarchical data structure that stores the information naturally in the form of a hierarchy style. It is one of the most powerful and advanced data structures which is a non-linear compared to arrays, linked lists, stack, and queue. It represents the nodes connected by edges
2. Java Tree Data Structure
The below table describes some of the terms used in a tree data structure:
| Root | It is the first top-level node. The entire tree is referenced through it. It does not have a parent. |
| Parent Node | Parent node is an immediate predecessor of a node |
| Child Node | All immediate successors of a node are its children |
| Siblings | Nodes with the same parent are called Siblings |
| Path | Path is a number of successive edges from the source node to the destination node |
| Height of Node | Height of a node represents the number of edges on the longest path between that node and a leaf |
| Height of Tree | Height of tree represents the height of its root node |
| Depth of Node | Depth of a node represents the number of edges from the tree’s root node to the node |
| Edge | Edge is a connection between one node to another. It is a line between two nodes or a node and a leaf |
3. Java Tree Implementations
In this section, we will discuss different types of tree data structures. Tree in computer science is like a tree in the real world, the only difference is that in computer science it is visualized as upside-down with root on the top and branches originating from the root to the leaves of the tree. Tree Data Structure is used for various real-world applications as it can show relationships among various nodes using the parent-child hierarchy. It is widely used to simplify and fasten searching and sorting operations.
3.1 General tree
A tree is called a general tree when there is no constraint imposed on the hierarchy of the tree. In General tree, each node can have an infinite number of children. This tree is the super-set of all other types of trees
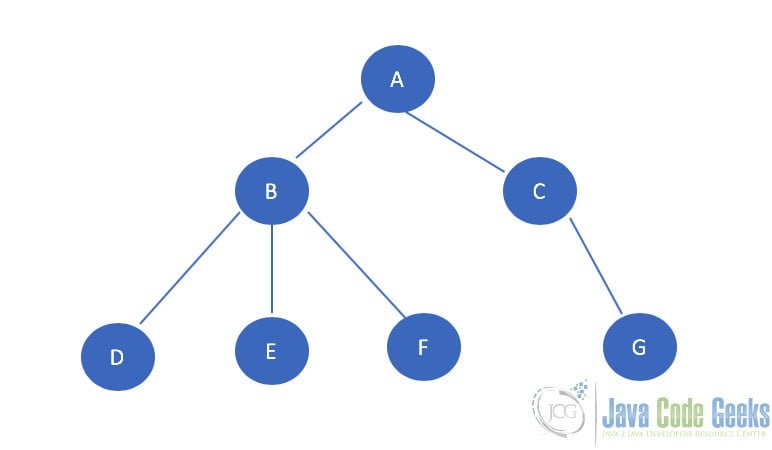
3.2 Binary tree
Binary tree is the type of tree in which each parent can have at most two children. The children are referred to as a left child or right child. This is one of the most commonly used trees. When certain constraints and properties are imposed on the Binary tree it results in a number of other widely used trees like BST (Binary Search Tree), AVL tree, RBT tree etc.
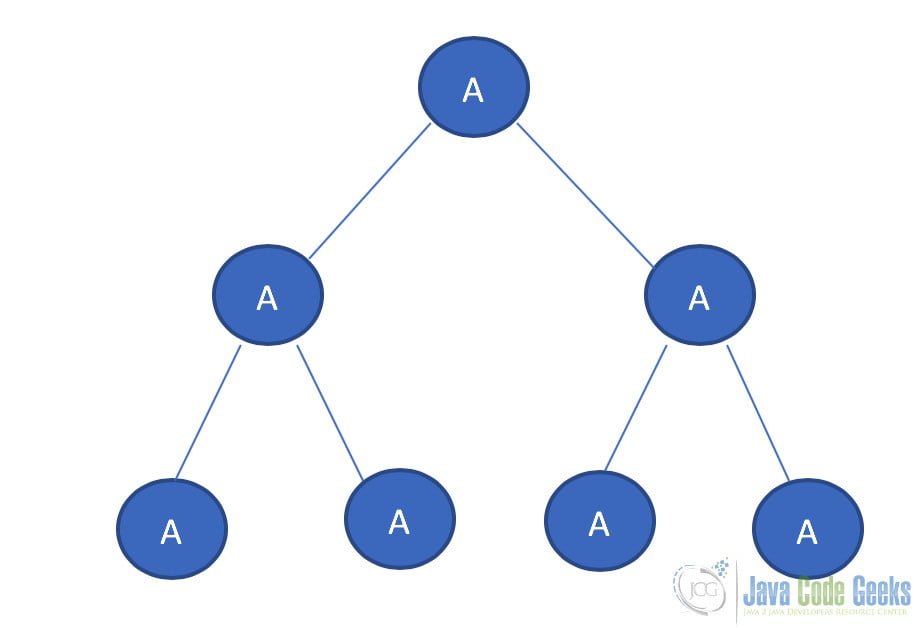
3.3 Binary Search Tree
A BST is a binary tree where nodes are ordered in the following way:
- The value in the left subtree are less than the value in its parent node
- The value in the right subtree are greater than the value in its parent node
- Duplicate values are not allowed.
3.4 AVL Tree
AVL tree is a self-balancing binary search tree. The name AVL is given on the name of its inventors Adelson-Velshi and Landis. This was the first dynamically balancing tree. In AVL tree, each node is assigned a balancing factor based on which it is calculated whether the tree is balanced or not. In AVL tree, the heights of children of a node differ by at most 1. The valid balancing factors in AVL trees are 1, 0 and -1. When a new node is added to the AVL tree and tree becomes unbalanced then rotation is done to make sure that the tree remains balanced. The common operations like lookup, insertion and deletion take O(log n) time in AVL tree. It is widely used for Lookup operations.
3.5 Red-Black Tree
Red-Black is another type of self-balancing tree. The name Red-Black is given to it because each node in a Red-Black tree is either painted Red or Black according to the properties of the Red- Black Tree. This makes sure that the tree remains balanced. Although the Red-Black tree is not a perfectly balanced tree but its properties ensure that the searching operation takes only O(log n) time. Whenever a new node is added to the Red-Black Tree, the nodes are rotated and painted again if needed to maintain the properties of the Red-Black Tree .
4. Benefits
In this section, we will discuss the benefits of Tree data structure. One of the main benefits of using the tree data structure is that it represents the structural relationship in the data and hierarchy. They are quite good for insertion and search operations. They are very flexible and they allow to move subtrees around with minimum effort.
5. Custom Tree Example
In this section, we will look into the binary tree implementation in Java. For the sake of simplicity, we will only discuss the sorted binary tree containing integers. A Binary tree is a data structure that has at the most two children. A common type of binary tree is a binary search tree, in which every node has a value that is greater than or equal to the node values in the left sub-tree, and less than or equal to the node values in the right sub-tree.
First, we will create a Node class that will represent a node in the tree. Value represents the data contained in the node. left and right represents the left and right node in the tree
Node.java
class Node {
int value;
Node left;
Node right;
public Node(int value) {
this.value = value;
}
}
5.1 Common Operations
In this section, we will see the java implementation of the common operations which are performed on the binary tree.
5.1.1 Insertion
In this section, we will look at how to insert a new node in the binary tree. First, we have to find the place where we want to add a new node in order to keep the tree sorted. We’ll follow the below rules starting from the root node
- if the new node’s value is lower than the current node’s, we go to the left child.
- if the new node’s value is greater than the current node’s, we go to the right child.
- when the current node is null, we’ve reached a leaf node and we can insert the new node in that position
JavaBinaryTreeExample.java
public void add(int value) {
root = add(root, value);
}
private Node add(Node current, int value) {
if (current == null) {
return new Node(value);
}
if (value < current.value) {
current.left= add(current.left, value);
} else if (value > current.value) {
current.right = add(current.right, value);
}
return current;
}
5.1.2 Searching
In this section, we will look at how to implement the searching logic for an element in a Binary tree.
JavaBinaryTreeExample.java
public boolean containsNode(int value) {
return containsNode(root, value);
}
private boolean containsNode(Node current, int value) {
if (current == null) {
return false;
}
if (value == current.value) {
return true;
}
return value < current.value
? containsNode(current.left, value)
: containsNode(current.right, value);
}
Here, we’re searching for the value by comparing it to the value in the current node, then continue in the left or right child depending on that.
5.1.3 Deletion
In this section we will see how to delete an element from a Binary tree.
JavaBinaryTreeExample.java
public void delete(int value) {
root = delete(root, value);
}
private Node delete(Node current, int value) {
if (current == null) {
return null;
}
if (value == current.value) {
// No children
if (current.left == null && current.right == null) {
return null;
}
// Only 1 child
if (current.right == null) {
return current.left;
}
if (current.left == null) {
return current.right;
}
// Two children
int smallestValue = findSmallestValue(current.right);
current.value = smallestValue;
current.right = delete(current.right, smallestValue);
return current;
}
if (value < current.value) {
current.left = delete(current.left, value);
return current;
}
current.right = delete(current.right, value);
return current;
}
Once we find the node to delete, there are 3 main different cases
- a node has no children – this is the simplest case; we just need to replace this node with null in its parent node
- a node has exactly one child – in the parent node, we replace this node with its only child
- a node has two children – this is the most complex case because it requires a tree reorganization
5.2 Traversing
In this section, we’ll see different ways of traversing a tree. A traversal is a process that visits all the nodes in the tree. Since a tree is a nonlinear data structure, there is no unique traversal.
5.2.1 Depth First Search (DFS)
Depth-first search is a type of traversal that goes deep as much as possible in every child before exploring the next sibling. There are several ways to perform a depth-first search: in-order, pre-order and post-order.
The in-order traversal consists of first visiting the left sub-tree, then the root node, and finally the right sub-tree:
JavaBinaryTreeExample.java
public void inOrderTraversal(Node node) {
if (node != null) {
inOrderTraversal(node.left);
print(node.value);
inOrderTraversal(node.right);
}
}
If we call this method for our example we will get: 7 10 17 20 29 55 60 99
Pre-order traversal visits first the root node, then the left subtree, and finally the right subtree:
JavaBinaryTreeExample.java
public void preOrderTraversal(Node node) {
if (node != null) {
print(node.value);
preOrderTraversal(node.left);
preOrderTraversal(node.right);
}
}
If we call this method for our example we will get: 20 7 17 10 29 60 55 99
Post-order traversal visits the left subtree, the right subtree, and the root node at the end:
JavaBinaryTreeExample.java
public void postOrderTraversal(Node node) {
if (node != null) {
postOrderTraversal(node.left);
postOrderTraversal(node.right);
print(node.value);
}
}
5.2.2 Breadth First Search (BFS)
This is another common type of traversal that visits all the nodes of a level before going to the next level. This kind of traversal is also called level-order and visits all the levels of the tree starting from the root, and from left to right.
6. Tree applications
Unlike Array and Linked List, which are linear data structures, tree is a hierarchical (or non-linear) data structure. One reason to use tree data structure might be because you want to store information that naturally forms a hierarchy, for e.g: the file system on the computer or the family tree. If we organize keys in the form of a tree (with some ordering e.g., BST), we can search for a given key in moderate time.
Heap is a tree data structure which is implemented using arrays and used to implement priority queues. B-Tree and B+ Tree are used to implement indexing in databases. Trie is used to implement dictionaries with prefix lookup. Suffix Tree can be used for quick pattern searching in a fixed text.
A company’s organization’s structure can be represented as tree showing who represents what in the company and who reports to whom. Another example of tree data structure application is the XML parser and decision tree-based learning.
7. Conclusion
In this article, we discussed about the Tree data structure. We discussed what doest a tree looks like and what it is made of. We discussed the different Java implementations of the tree. We looked at the benefits of using tree data structure and how it can be represented in Java.
We discussed the different operations we can perform on the tree e.g: adding of an element, deletion and searching. We discussed different types of ways we can traverse the tree (Depth-first vs Breadth-first).
In the end, we discussed the real-life application of the tree data structure.
8. Download the Source Code
You can download the full source code of this example here: Java Tree Example

In insertion method there is typo:
if(value < current.value) {
current.right = add(current.right, value);
}
else
if
(value > current.value) {
current.right = add(current.right, value);
}
correction should be :
if(value < current.value)
current.left= add (current.left, value)
Thanks for your comment the article has just been corrected.
This is the Best Explanation among all