This example illustrates JBoss Drools and its best practices. We will also cover terminology used with Drools with little explanation. Before we proceed with this article, lets assume that readers have basic knowledge about how a Java n-tier application works. In brief, any Java enterprise level application can be split into three parts:
- UI – User Interface (Frontend/presentation layer)
- Service layer which is in turn connected to a database
- Business layer (which contains the business logic)
We have a number of frameworks that handle the UI and service layer together, for example, Spring and Struts. We did not have a standard way to handle the business logic until Drools came into existence.
Drools is a Rule Engine that uses the rule-based approach to decouple logic from the system. The logic is external to the system in the form of rules which when applied to data, results into the decision making. A rules engine is a tool for executing business rules. In this article, we will see the terms related to Drools, also covering how to add Drools plugin to eclipse and the best practices for writing the rules for Drools rule engine.
Table Of Contents
1. Introduction to Drools
Drools is a Business Logic integration Platform(BLiP) written in Java. It is an open source project written by Bob McWhirter, that is backed by JBoss and Red Hat, Inc. Drools provide a core Business Rules Engine (BRE), a web authoring and rules management application (Drools Workbench) and an Eclipse IDE plugin for core development.
In short, Drools is a collection of tools that allow us to separate and reason over logic and data found within business processes. The business rule management system (BRMS) in Drools is also known as Production Rule System.
Drools is split into two main parts: Authoring and Runtime.
- Authoring: Authoring process involves the creation of Rules files (.DRL files).
- Runtime: It involves the creation of working memory and handling the activation.
1.1 Authoring
The Authoring process involves the creation of Rules files (.DRL) which contain the rules which are fed into a parser. The parser checks for correct syntax of the rules and produces an intermediate structure that “describes” the rules. This is then passed to the Package Builder which produces Packages and undertakes any code generation and compilation that is necessary for the creation of the Package.
1.2 Runtime
Drools Runtime is required to instruct the editor to run the program with specific version of Drools jar. We can run your program/application with different Drools Runtime.
1.3 Working Memory
The Working memory is a key point of the Drools engine: it’s here that Facts are inserted. Facts are plain Java classes which rely on the Java Bean pattern (the Java beans from our application). Facts are asserted into the Working Memory where they may then be modified or retracted.
When facts are asserted into the working memory, it will result in one or more rules being concurrently true and scheduled for execution by the Agenda – we start with a fact, it propagates and we end in a conclusion. This method of execution for a Production Rule Systems is called Forward Chaining.
2. What is a Rule Engine
Rule Engine can be any system that uses rules, in any form, that can be applied to data to produce outcomes. This includes simple systems like form validation and dynamic expression engines. Drools is also a Rule Engine or a “Production Rule System” that uses the rule-based approach to implement an Expert System.
Expert Systems use Knowledge representation to facilitate the codification of knowledge into a knowledge base which can be used for reasoning, i.e., we can process data with this knowledge base to infer conclusions. A Rule Engine allows you to define “What to Do” and not “How to do it.”
A Production Rule is a two-part structure: the engine matches facts and data against Production Rules – also called Productions or just Rules – to infer conclusions which result in actions.
when
<conditions>
then
<actions> ;
The process of matching the new or existing facts against Production Rules is called “pattern matching”, which is performed by the inference engine. Actions execute in response to changes in data, like a database trigger; we say this is a data driven approach to reasoning. The actions themselves can change data, which in turn could match against other rules causing them to fire; this is referred to as forward chaining.
3. Advantages of a Rule Engine
Declarative Programming: Rules make it easy to express solutions to difficult problems and get the solutions verified as well. Unlike codes, Rules are written in less complex language; Business Analysts can easily read and verify a set of rules.
Logic and Data Separation: The data resides in the Domain Objects and the business logic resides in the Rules. Depending upon the kind of project, this kind of separation can be very advantageous.
Speed and Scalability: The Rete OO algorithm on which Drools is written is already a proven algorithm. With the help of Drools, your application becomes very scalable. If there are frequent change requests, one can add new rules without having to modify the existing rules.
Centralization of Knowledge: By using Rules, you create a repository of knowledge (a knowledge base) which is executable. It is a single point of truth for business policy. Ideally, Rules are so readable that they can also serve as documentation.
Tool Integration: Tools such as Eclipse provide ways to edit and manage rules and get immediate feedback, validation, and content assistance. Auditing and debugging tools are also available.
Explanation Facility: Rule systems effectively provide an “explanation facility” by being able to log the decisions made by the rule engine along with why the decisions were made.
Understandable Rules: By creating object models and, optionally, Domain Specific Languages that model your problem domain you can set yourself up to write rules that are very close to natural language. They lend themselves to logic that is understandable to, possibly nontechnical, domain experts as they are expressed in their language, with all the program plumbing, the technical know-how being hidden away in the usual code.
4. What is a Rule
Rules are pieces of knowledge often expressed as, “When some conditions occur, then do some tasks.” The most important part of a Rule is its when part. If the when part is satisfied, the then part is triggered. The brain of a Production Rules System is an Inference Engine that is able to scale to a large number of rules and facts. The Inference Engine matches facts and data against Production Rules – also called Productions or just Rules – to infer conclusions which result in actions.
The process of matching the new or existing facts against Production Rules also called Pattern Matching, is performed by the “Inference Engine”. There are a number of algorithms used for Pattern Matching including:
- Linear
- Rete
- Treat
- Leaps
Drools implements and extends the Rete Algorithm. Drools has an enhanced and optimized implementation of the Rete algorithm for object-oriented systems.
The Rules are stored in the Production Memory and the facts that the Inference Engine matches against are kept in the Working Memory. Facts are asserted into the Working Memory where they may then be modified or retracted. A system with a large number of rules and facts may result in many rules being true for the same fact assertion; these rules are said to be in conflict. The Agenda manages the execution order of these conflicting rules using a Conflict Resolution strategy.
5. Rete algorithm
The Rete algorithm was invented by “Dr. Charles Forgy”. The latin word “rete” means “net” or “network”. The Rete algorithm can be broken into 2 parts: rule compilation and runtime execution. The compilation algorithm describes how the Rules in the Production Memory are processed to generate an efficient discrimination network.
In non-technical terms, a discrimination network is used to filter data as it propagates through the network. The nodes at the top of the network would have many matches, and as we go down the network, there would be fewer matches. At the very bottom of the network are the terminal nodes. In Dr. Forgy’s 1982 paper, he described 4 basic nodes: root, 1-input, 2-input and terminal.
The root node is where all objects enter the network. From there, it immediately goes to the ObjectTypeNode. The purpose of the ObjectTypeNode is to make sure the engine doesn’t do more work than it needs to. For example, say we have 2 objects: Account and Order. If the rule engine tried to evaluate every single node against every object, it would waste a lot of cycles. To make things efficient, the engine should only pass the object to the nodes that match the object type. The easiest way to do this is to create an ObjectTypeNode and have all 1-input and 2-input nodes descend from it. This way, if an application asserts a new Account, it won’t propagate to the nodes for the Order object.
In Drools when an object is asserted it retrieves a list of valid ObjectTypesNodes via a lookup in a HashMap from the object’s Class; if this list doesn’t exist it scans all the ObjectTypeNodes finding valid matches which it caches in the list. This enables Drools to match against any Class type that matches with an instanceof check.
The “Rete algorithm” is a pattern matching algorithm for implementing production rule systems. It is used to determine which of the system’s rules should fire based on its data store. If you had to implement a rule engine, you’d probably start with a simple iteration over all rules and checking them one by one if their conditions are true. The “Rete algorithm” improves this by several orders of magnitude.
The advantage that this algorithm brings is efficiency; however, it comes at a cost of higher memory usage. The algorithm uses lot of caching to avoid evaluating conditions multiple times.
The word “Rete” is taken from Latin where it represents a “net”. It is generally pronounced as “ree-tee”. This algorithm generates a network from rule conditions. Each single rule condition is a node in the “Rete” network.
6. Adding Drools plugin in eclipse
As Drools is a BRMS, we will also see how to add Drools plugin to Eclipse Oxygen, since it is quite popular for Java users to use eclipse. Listed below are the steps to add Drools plugin to eclipse.
Step 1: Download the Drools binaries from the following link: http://download.jboss.org/drools/release/5.6.0.Final/
Step 2: Once the zip files are downloaded extract the content to any folder in local. We will be using Eclipse Oxygen v2 to see how to install Drools plugin.
Step 3: Launch eclipse and goto Help->Install new Software
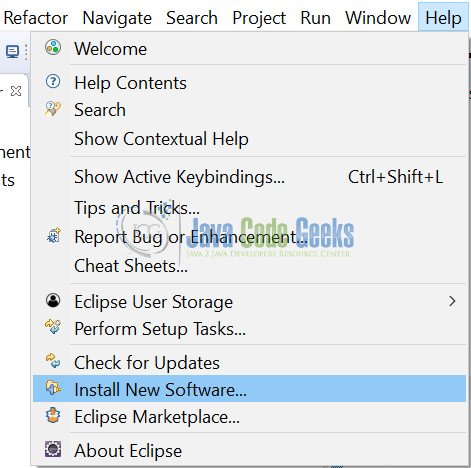
Step 4: Click on “Add” in the install screen that opens up.
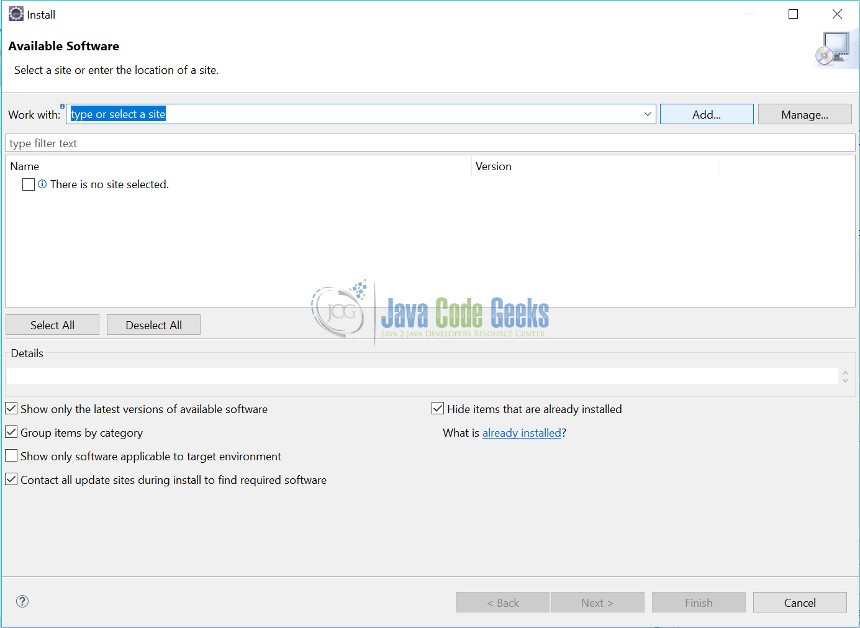
Step 5: Click on “Local” and select ../binaries/org.drools.updatesite from the local system where you have downloaded Drools library files in Step 1 and Step 2.
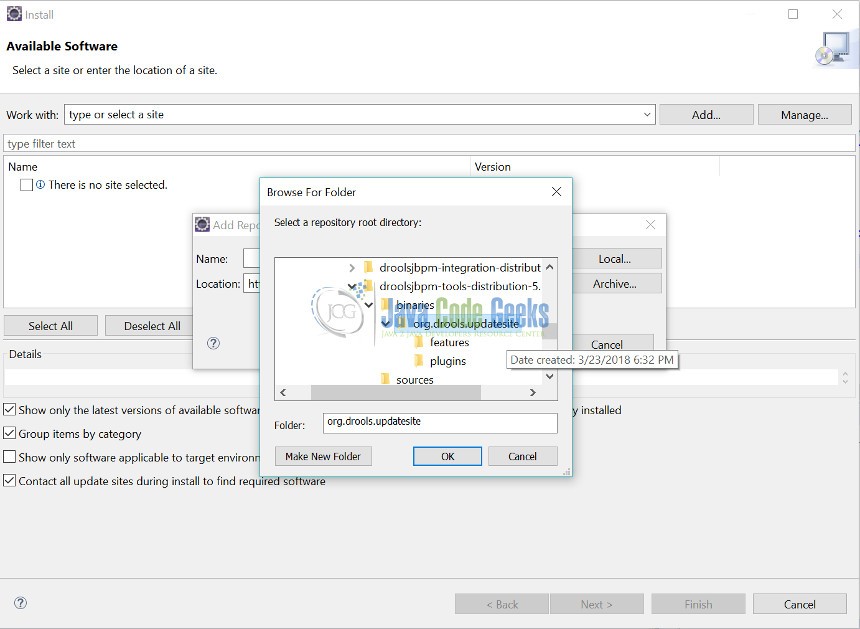
Step 6: Press ok and you will be redirected to the previous page . Then select “Drools and jBPM”.
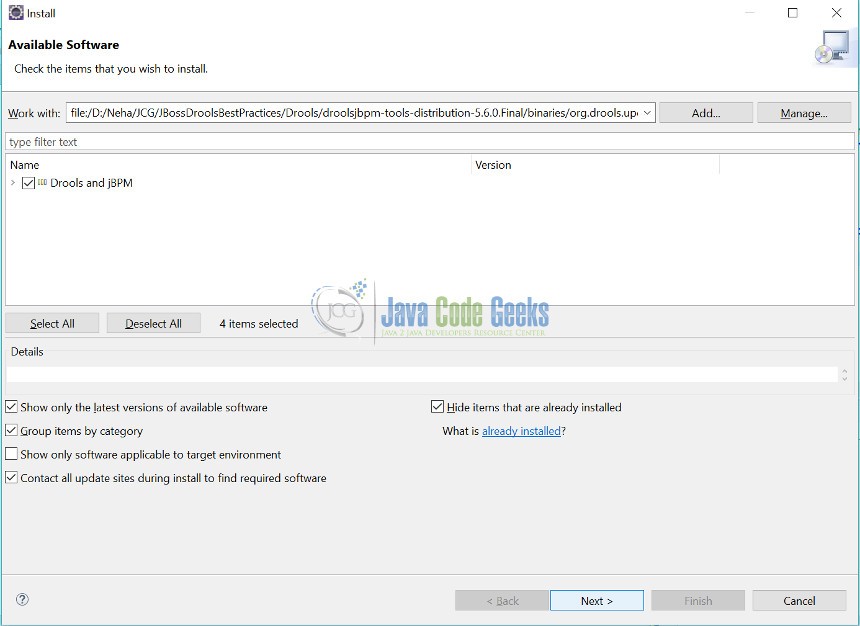
Step 7: When “Next” button is clicked, it takes few seconds to goto the next page.
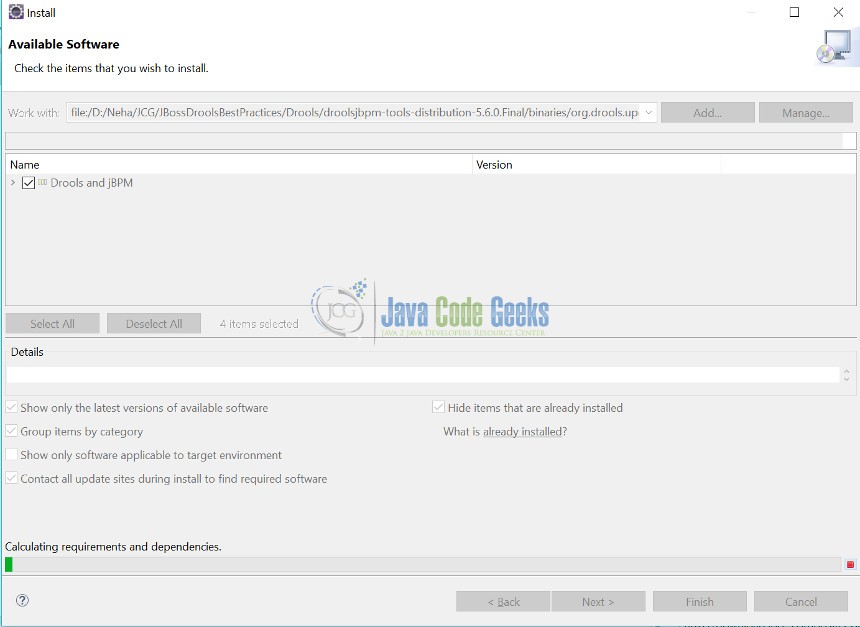
Step 8: Again click “Next” button
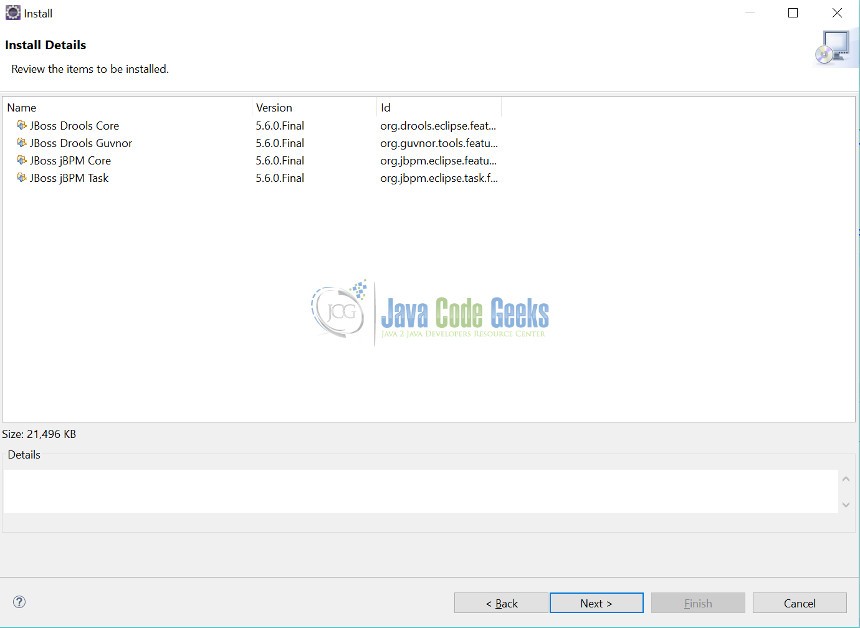
Step 9: Accept the terms and conditions on next page and click “Finish”.
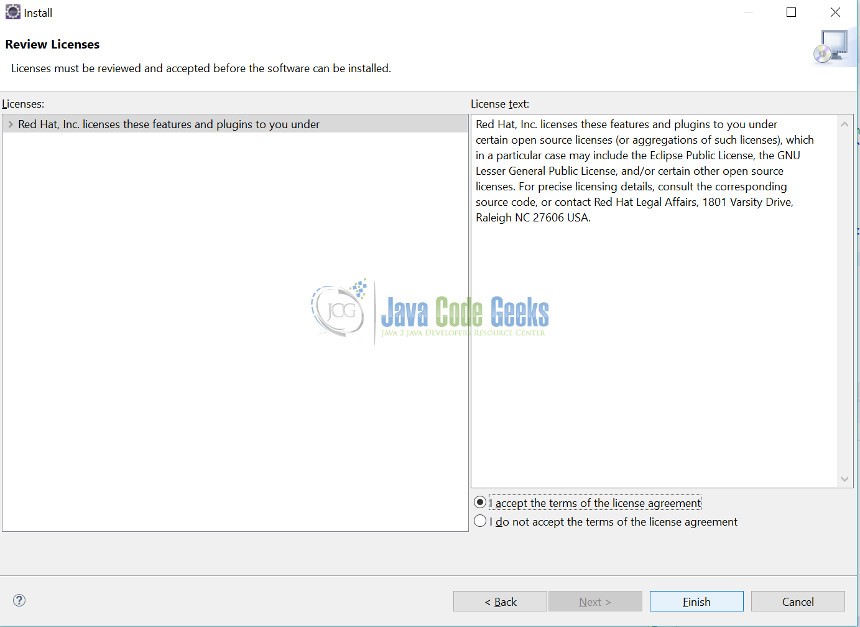

Step 10: You might get a security warning in eclipse to install the software. Select “Install Anyway” and proceed with installation.
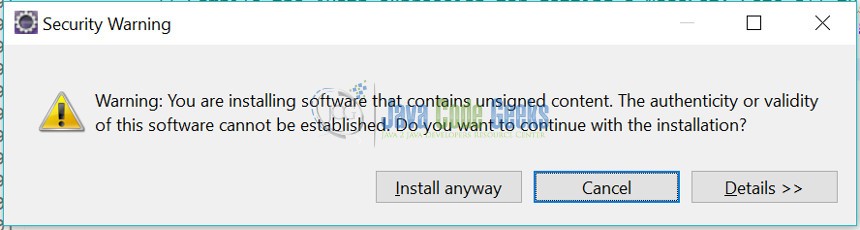
Step 11: After the software is installed, a pop up comes asking to restart the eclipse. Select “Restart Now” and proceed.

Step 12: Once eclipse restarts, goto Windows -> Preferences. We can see Drools under preferences. Drools plugin installation is complete now.
7. Best Practices
Lets see some best practices that can be followed in order to maximize the benefits provided by business rule management system (BRMS) tools. The best practices are grouped under architectural and authoring practices.
7.1 Architectural practices
7.1.1 Knowledge Base Partitioning
A Knowledge Base usually will contain assets such as rules, processes and domain models that are related to one subject, business entity or unit of work. Understanding how to partition these assets in knowledge base can have a huge impact on the overall solution. BRMS tools are better at optimizing sets of rules than they are at optimizing individual rules.
The larger the rule set, the better the results will be when compared to the same set of rules split among multiple rule sets. On the other hand, increasing the rule set by including non-related rules has the opposite effect as the engine will be unable to optimize unrelated rules. The application will still pay for the overhead of the additional logic. As a best practice, users should partition the knowledge bases by deploying only the related rules into a single knowledge base. Users should also avoid monolithic knowledge bases as well as those that are too fine grained.
7.1.2 Knowledge Session Partitioning
The creation of Knowledge Sessions is designed to be inexpensive with regard to performance. BRMS systems typically scale better when increasing the number of rules and scale worse when increasing the volume of data (facts). We can therefore infer that the smaller the knowledge sessions are, the better the overall performance of the system will be. Individual sessions are also simple to parallelize, so a system with many sessions will scale better on hardware with multiple processors.
At the same time we should minimize the fragmentation of data or facts, so we want to include only the related facts in the same session with the related rules. This typically comprises the facts relative to a transaction, service or unit of work. When creating a session, it is more desirable to add all the facts to the session in a batch and then fire the rules than it is to add individual facts and fire the rules for each of them.
7.1.3 Domain Model Design
A BRE is very similar to a database, from the underlying relational algorithms to the optimizations like data indexing. It is not a surprise then that many of the best practices that are documented for the use of databases also apply to BRE. One of the most important best practice is to carefully design the domain model. The quality of the domain model is directly proportional to the performance and maintainability of the rules.
A badly designed domain model not only affects the runtime of the engine, but also increases time and cost as rules will be more complex to author and harder to maintain over time. A good domain model is one that represents the relationships between the multiple entities in the simplest way possible. Flatter models usually help making constraints easier to write while small entities (entities with few attributes) help prevent loops.
7.2 Rules Authoring
7.2.1 Don’t try to micro-control
Rules should execute actions based on scenarios, these are the conditions of the rules. By following this simple principle rules remain loosely coupled, allowing rule authors to manage them individually. Rule engines further optimize the rules that are decoupled. Use conflict resolution strategies like salience, agenda-groups or rule-flows only to orchestrate sets of rules, never for individual rules.
7.2.2. Don’t overload rules
Each rule should describe a mapping between one scenario and one list of actions. Don’t try to overload the rules with multiple scenarios as it will make long term maintenance harder. It also increases the complexity of testing and unnecessarily ties the scenarios to each other. Leverage the engine’s inference and chaining capabilities to model complex scenarios by decomposing it into multiple rules. The engine will share any common conditions between scenarios, so there is no performance penalty for doing so. For example:
rule “1 – Teenagers and Elders get Discount” when Person age is between 16 and 18 or Person age is greater or equal to 65 then Assign 25% ticket discount end rule “2 – Elders can buy tickets in area A” when Person age is greater or equal to 65 then Allow sales of area A tickets end
The above rules are overloaded. They define in the same rules policies for what a teenager or elder is, as well as the actual actions that should be taken for those classes of people. Pretend that the company had 1000 rules that apply to elders and in each rule, it would repeat the condition “Person age is greater or equal to 65”to check for Elders.
Imagine that the company policy for Elders, or the government law about it, changes and a Person with age 60+ is now considered an Elder. This simple policy change would for a change in all of the 1000 existing rules, not to mention test scenarios, reports, etc. A much better way of authoring the same rules would be to have one rule defining what an Elder is, another defining what a Teenager is, and then all the 1000 rules just using the inferred data. For example:
rule “0.a – Teenagers are 16-18” rule “0.b – Elders are older than 65” when Person age is between 16 and 18 then Assert: the person is a Teenager end rule “0.b – Elders are older than 65” when Person is older than 65 then Assert: the person is an Elder end rule “1 – Teenagers and Elders get discount” when Teenager or Elder then Assign 25% ticket discount end
When authored like this the user is leveraging the inference capabilities of the engine while making the rules simpler to understand and maintain. Also the same change of policy for elders would only affect one single rule among the 1000 rules in our example, reducing costs and complexity.
7.2.3 Control facts are a code smell
“Control facts” are facts introduced in the domain and used in the rules for the sole purpose of explicitly controlling the execution of rules. They are arbitrary and don’t represent any entity in the domain and usually are used as the first condition in a rule. “Control facts” are heavily used in engines that don’t have the expressive and powerful conflict resolution strategies that JBoss BRMS has and have many drawbacks: they lead to micro-control of rule executions, they cause massive bursts of work with unnecessary rule activations and cancellations. They degrade visibility and expressiveness of rules, making it harder for other users to understand as well as create dependencies between rules.
“Control facts” are a code smell that should be avoided as a general best practice. Having said that, there is only one use case where control facts are acceptable, and that is to prevent an expensive join operation that should not happen until a given condition is met.
7.2.4 Right tool for the right job
JBoss BRMS has many advanced features that help users and rule authors model their business. For instance, if one needs to query the session for data in order to make a decision, or to return data to the application, then a user should use queries instead of rules.
“Queries” are like rules but they are always invoked by name, never execute actions and always return data. “Rules” on the other hand are always executed by the engine (can’t be invoked), should always execute actions when they match and never return data. Another feature that JBoss BRMS provides is the declarative models, i.e., fact types declared and defined as part of the knowledge base. For example:
declare Person name : String age : int end
Declarative models are a great way to develop quick prototypes and to model auxiliary fact types that are used only by rules, not by an application. JBoss BRMS integrates natively with domain models developed in POJOs and the use of POJOs simplifies application integration, testing and should be preferred whenever rules and application use the same domain entities.
8. Conclusion
This article covers the terminology used with JBoss Drools and its best practices. As Drools is a business logic integration platform written in Java, this article explains usage of Drools in a business environment. We have also seen how to install Drools plugin in eclipse IDE. This article is also useful for all those readers who wish to define rules in their applications to integrate business logic in a standard way.
9. References
Following links have been referred while writing this article:
- https://docs.jboss.org/drools/release/5.3.0.Final/drools-expert-docs/html/ch01.html
- https://en.wikipedia.org/wiki/Drools
- https://www.tutorialspoint.com/drools/drools_introduction.htm
