In this article we will learn how to use XPath in XSLT. XPath stands for XML Path Language. It is a W3C recommendation. It uses ‘path like’ syntax to identify and navigate nodes in an XML document.
1. Introduction
XPath can be used to navigate through elements and attributes in an XML document. XPath contains over 200 built-in functions. There are functions for string values, numeric values, booleans, date and time comparison, node manipulation, sequence manipulation, and much more. XPath expressions can also be used in JavaScript, Java, XML Schema, PHP, Python, C and C++, and lots of other languages.
2. Terminologies
In this section we will learn about the various terminologies used in XPath.
2.1 Node
In XPath, there are seven kinds of nodes: element, attribute, text, namespace, processing-instruction, comment, and document nodes. XML documents are treated as trees of nodes. The topmost element of the tree is called the root element. Look at the following XML document:
persons.xml
<?xml version="1.0" encoding="UTF-8"?>
<persons>
<person>
<name lang="en">
<firstName>Steve</firstName>
<surname>Jones</surname>
</name>
<address>
<firstLine>33 Churchill Road</firstLine>
<secondLine>Washington</secondLine>
<city>Washington DC</city>
</address>
<age>45<age>
</person>
</persons>In the above xml person, name, firstName etc are all nodes. ‘persons’ is the root node. Each node has a parent node except the root node. Element nodes may have zero, one or more children. Nodes that have the same parent are called Siblings. An ancestor is a node’s parent, parent’s parent, etc.
2.2 Attribute
Attribute is assigned to the node. In the above example ‘lang’ in an attribute of ‘name’ node.
2.3 XPath Expressions
In general, an XPath expression specifies a pattern that selects a set of XML nodes. XSLT templates then use those patterns when applying transformations. (XPointer, on the other hand, adds mechanisms for defining a point or a range so that XPath expressions can be used for addressing). The nodes in an XPath expression refer to more than just elements. They also refer to text and attributes, among other things. In fact, the XPath specification defines an abstract document model that defines seven kinds of nodes:
- Root
- Element
- Text
- Attribute
- Comment
- Processing instruction
- Namespace
The root element of the XML data is modeled by an element node. The XPath root node contains the document’s root element as well as other information relating to the document.
2.4 XSLT/XPath Data Model
Like the Document Object Model (DOM), the XSLT/XPath data model consists of a tree containing a variety of nodes. Under any given element node, there are text nodes, attribute nodes, element nodes, comment nodes, and processing instruction nodes.
In this abstract model, syntactic distinctions disappear, and you are left with a normalized view of the data. In a text node, for example, it makes no difference whether the text was defined in a CDATA section or whether it included entity references. The text node will consist of normalized data, as it exists after all parsing is complete. So the text will contain a < character, whether or not an entity reference such as < or a CDATA section was used to include it. (Similarly, the text will contain an & character, whether it was delivered using & or it was in a CDATA section).
3. XPath Nodes Selection
XPath uses path expressions to select nodes in an XML document. The node is selected by following a path or steps. The most useful path expressions are listed below:
| Expression | Description |
| nodename | Selects all nodes with the name “nodename“ |
| / | Selects from the root node |
| // | Selects nodes in the document from the current node that match the selection no matter where they are |
| . | Selects the current node |
| .. | Selects the parent of the current node |
| @ | Selects attributes |
Below we show the result if we used these XPath expressions on out sample xml:
| Path Expression | Result |
| person | Selects all nodes with the name “person” |
| /persons | Selects the root element persons Note: If the path starts with a slash ( / ) it always represents an absolute path to an element! |
| person/name | Selects all name elements that are children of person |
| //name | Selects all name elements no matter where they are in the document |
| person//name | Selects all name elements that are descendant of the person element, no matter where they are under the person element |
| //@lang | Selects all attributes that are named lang |
3.1 Predicates
Predicates are used to find a specific node or a node that contains a specific value. Predicates are always embedded in square brackets.
/persons/person[1] => Selects the first person element that is the child of the persons element.
/persons/person[last()] => Selects the last person element that is the child of the persons element.
/persons/person[last()-1] => Selects the last but one person element that is the child of the persons element.
/persons/person[position()<3] => Selects the first two person elements that are children of the persons element.
//name[@lang] => Selects all the name elements that have an attribute named lang.
//name[@lang='en'] => Selects all the name elements that have a “lang” attribute with a value of “en”.
/persons/person[age>40] => Selects all the person elements of the persons element that have an age element with a value greater than 40.
/persons/person[age>40]/name => Selects all the name elements of the person elements of the persons element that have an age element with a value greater than 40.
3.2 Selecting Unknown nodes
XPath wildcards can be used to select unknown XML nodes.
* => Matches any element node
@* => Matches any attribute node
node() => Matches any node of any kind
Below we will apply these on our sample xml
/persons/* => Selects all the child element nodes of the persons element
//* => Selects all elements in the document
//name[@*] => Selects all name elements which have at least one attribute of any kind
By using the | operator in an XPath expression you can select several paths.
4. XSLT
XSLT stands for XSL (EXtensible Stylesheet Language) Transformations. XSLT is a language for transforming XML documents. XSLT is used to transform an XML document into another XML document, or another type of document that is recognized by a browser, like HTML and XHTML. Normally XSLT does this by transforming each XML element into an (X)HTML element. With XSLT you can add/remove elements and attributes to or from the output file. You can also rearrange and sort elements, perform tests and make decisions about which elements to hide and display, and a lot more.
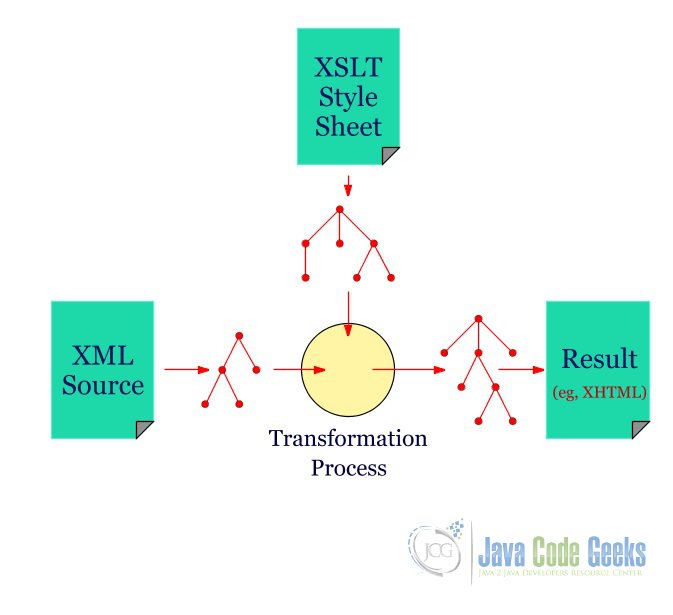
XSLT uses XPath to find information in an XML document. XPath is used to navigate through elements and attributes in XML documents. In the transformation process, XSLT uses XPath to define parts of the source document that should match one or more predefined templates. When a match is found, XSLT will transform the matching part of the source document into the result document.
The root element that declares the document to be an XSL style sheet is <xsl:stylesheet> or <xsl:transform>. <xsl:stylesheet> and <xsl:transform> are completely synonymous and either can be used. The correct way to declare an XSL style sheet according to the W3C XSLT Recommendation is:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
or:
<xsl:transform version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
To get access to the XSLT elements, attributes and features we must declare the XSLT namespace at the top of the document. The xmlns:xsl=”http://www.w3.org/1999/XSL/Transform” points to the official W3C XSLT namespace. If you use this namespace, you must also include the attribute version=”1.0″.
5. Convert XML to HTML
The output of an XSLT processing can be an HTML, XML (e.g. XHTML, SVG etc) or pure text. In this section we will see how we can convert an XML to an HTML using XSLT. We will use the persons.xml file for this. Create an XSL Style Sheet with a transformation template:
persons.xsl
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<body>
<h2>XSLT transformation example</h2>
<table border="1">
<tr bgcolor="grey">
<th>First Name</th>
<th>Surname</th>
<th>First line of Address</th>
<th>Second line of Address</th>
<th>City</th>
<th>Age</th>
</tr>
<xsl:for-each select="persons/person">
<tr>
<td><xsl:value-of select="name/firstName"/></td>
<td><xsl:value-of select="name/surname"/></td>
<td><xsl:value-of select="address/firstLine"/></td>
<td><xsl:value-of select="address/secondLine"/></td>
<td><xsl:value-of select="address/city"/></td>
<td><xsl:value-of select="age"/></td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Add the XSL style sheet reference to your XML document.
<?xml-stylesheet type="text/xsl" href="persons.xsl"?>
5.1 XSL Template
An XSL style sheet consists of one or more set of rules that are called templates. A template contains rules to apply when a specified node is matched. It is a set of formatting instructions that apply to the nodes selected by an XPath expression. The <xsl:template> element is used to build templates. The match attribute is used to associate a template with an XML element. The match attribute can also be used to define a template for the entire XML document. The value of the match attribute is an XPath expression (i.e. match=”/” defines the whole document).
Since an XSL style sheet is an XML document, it always begins with the XML declaration: <?xml version="1.0" encoding="UTF-8"?>. The next element, <xsl:stylesheet>, defines that this document is an XSLT style sheet document (along with the version number and XSLT namespace attributes). The <xsl:template> element defines a template. The match="/" attribute associates the template with the root of the XML source document. The content inside the <xsl:template> element defines some HTML to write to the output. The last two lines define the end of the template and the end of the style sheet.
The <xsl:value-of> element can be used to extract the value of an XML element and add it to the output stream of the transformation.
5.2 Transformation
In this section we will see how to do the transformation in Java. We will make use of two java packages:
javax.xml.parsers – It provides classes allowing the processing of XML documents. Two types of plugable parsers are supported: SAX (Simple API for XML) and DOM (Document Object Model)
javax.xml.transform – This package defines the generic APIs for processing transformation instructions, and performing a transformation from source to result. These interfaces have no dependencies on SAX or the DOM standard, and try to make as few assumptions as possible about the details of the source and result of a transformation. It achieves this by defining Source and Result interfaces. To define concrete classes for the user, the API defines specializations of the interfaces found at the root level. These interfaces are found in javax.xml.transform.sax, javax.xml.transform.dom, and javax.xml.transform.stream. The API allows a concrete TransformerFactory object to be created from the static function TransformerFactory.newInstance().
First we will create the DocumentBuilderFactory:
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
It defines a factory API that enables applications to obtain a parser that produces DOM object trees from XML documents. Then we will create a new DocumentBuilder using this factory:
DocumentBuilder builder = factory.newDocumentBuilder();
This class defines the API to obtain DOM Document instances from an XML document. Once an instance of this class is obtained, XML can be parsed from a variety of input sources. These input sources are InputStreams, Files, URLs, and SAX InputSources. Note that this class reuses several classes from the SAX API. This does not require that the implementor of the underlying DOM implementation use a SAX parser to parse XML document into a Document. It merely requires that the implementation communicate with the application using these existing APIs.
Then we will parse the xml:
document = builder.parse(xml);
This method parses the content of the given file as an XML document and return a new DOM Document object.
Now we will create the transformer as below:
TransformerFactory tFactory = TransformerFactory.newInstance(); StreamSource stylesource = new StreamSource(xsl); Transformer transformer = tFactory.newTransformer(stylesource);
A TransformerFactory instance can be used to create Transformer and Templates objects.
Now we can use this transformer instance to transform the xml source to the result. Below is the full class representation:
XsltTransformation.java
package com.javacodegeeks;
import org.w3c.dom.Document;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import javax.xml.transform.stream.StreamSource;
import java.io.File;
/**
* Created by Meraj on 08/04/2017.
*/
public class XsltTrasfromation {
private static Document document;
public static void main(String[] args) throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
File xml = new File("C:\\temp\\persons.xml");
File xsl = new File("C:\\temp\\persons.xsl");
DocumentBuilder builder = factory.newDocumentBuilder();
document = builder.parse(xml);
// Use a Transformer for output
TransformerFactory transformerFactory = TransformerFactory.newInstance();
StreamSource style = new StreamSource(xsl);
Transformer transformer = transformerFactory.newTransformer(style);
DOMSource source = new DOMSource(document);
StreamResult result = new StreamResult(System.out);
transformer.transform(source, result);
}
}
If we run the above program the html will be outputted to the console. You can copy the html text in a file and save this file as *.html. If you open this file you will see something like:

6. Conclusion
In this article we learned about XPath and XSLT. We saw how XSLT works and how it uses XPath to do the processing. We also discussed various terminologies used in XPath and XSLT and what they corresponds to in an XML document. We also showed the example of how to convert a given XML to another format (or another XML) using XSLT. In the end we discussed how to do the transformation with Java. XSLT is a very useful feature in any project as it allows you, adapt to changes very quickly and efficiently.
