In the previous examples, we have studied about various Itext Classes like PDFTable, PDFStamper,PDFRectangle etc. that help us in creation of the PDF document. In this example, we will demonstrate when we already have a document in HTML format and need to convert it to a PDF Document.
1. Project Set-Up
We shall use Maven to setup our project. Open eclipse and create a simple Maven project and check the skip archetype selection checkbox on the dialogue box that appears. Replace the content of the existing pom.xml with the pom.xml below:
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>ItextHtmlToPDFExample</groupId> <artifactId>ItextHtmlToPDFExample</artifactId> <version>0.0.1-SNAPSHOT</version> <dependencies> <dependency> <groupId>com.itextpdf</groupId> <artifactId>itextpdf</artifactId> <version>5.5.6</version> </dependency> <dependency> <groupId>org.bouncycastle</groupId> <artifactId>bcprov-jdk15on</artifactId> <version>1.52</version> </dependency> <dependency> <groupId>com.itextpdf.tool</groupId> <artifactId>xmlworker</artifactId> <version>5.5.7</version> </dependency> </dependencies> </project>
In this example, we have added one more dependency for the Xmlworker JAR. That’s all from setting-up project point of view, let’s start with the actual code writing now:
2. Implementation
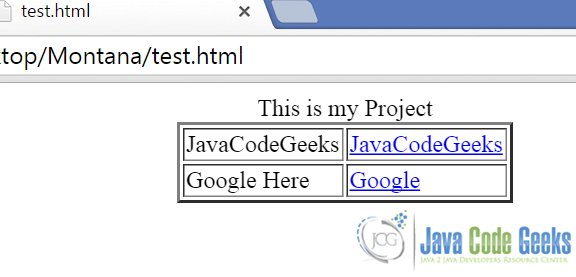
We will convert the below HTML document into a PDF document:
<html><body align='center'> This is my Project <table border='2' align='center'> <tr> <td> JavaCodeGeeks </td> <td> <a href='examples.javacodegeeks.com'>JavaCodeGeeks</a> </td> </tr> <tr> <td> Google Here </td> <td> <a href='www.google.com'>Google</a> </td> </tr> </table>
Here’s the how the document looks like in a browser(CHROME here):
The com.itextpdf.tool.xml.XMLWorkerHelper converts the XHTML code to PDF. The Xhtml is a stricter version of HTML which ensures the document are well-formed and hence can be parsed efficiently by the standard XML parsers. Not closing the tags or any other syntax errors can lead to exception like :
com.itextpdf.tool.xml.exceptions.RuntimeWorkerException: Invalid nested tag html found, expected closing tag body.
Now that we are clear with the basics let’s write the code for the actual conversion:
ItextHtmlToPDFExample.java
package com.jcg.examples;
import java.io.ByteArrayInputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
import com.itextpdf.text.Document;
import com.itextpdf.text.pdf.PdfWriter;
import com.itextpdf.tool.xml.XMLWorkerHelper;
public class ItextHtmlToPDFExample
{
public static void main(String[] args)
{
try
{
OutputStream file = new FileOutputStream(new File("HTMLtoPDF.pdf"));
Document document = new Document();
PdfWriter writer = PdfWriter.getInstance(document, file);
StringBuilder htmlString = new StringBuilder();
htmlString.append(new String("<html><body> This is HMTL to PDF conversion Example<table border='2' align='center'> "));
htmlString.append(new String("<tr><td>JavaCodeGeeks</td><td><a href='examples.javacodegeeks.com'>JavaCodeGeeks</a> </td></tr>"));
htmlString.append(new String("<tr> <td> Google Here </td> <td><a href='www.google.com'>Google</a> </td> </tr></table></body></html>"));
document.open();
InputStream is = new ByteArrayInputStream(htmlString.toString().getBytes());
XMLWorkerHelper.getInstance().parseXHtml(writer, document, is);
document.close();
file.close();
}
catch (Exception e)
{
e.printStackTrace();
}
}
}
We create an instance of the Document and FileOutputStream and pass it the PDFWriter. Now we create a StringBuilder object which holds the HTML source code. The XMLWorker class accepts the Byte Array of the HTML source code. XMLWorkerHelper.getInstance().parseXHtml() method parses the HTML source code and writes to the document created earlier via the PDFWriter instance.

Here’s how the converted PDF document looks like:

3. Download the Source Code
Here, we demonstrated how we can convert a HTML Document to PDF format using the Itext library.
You can download the source code of this example here: ItextHtmlToPDFExample.zip

Can i encoding a base64 from PDF file?
Best regards
This is work for me …. thank you
iText7 converting htmltoPDF not setting background color
XMLWorkerHelper is not wotking for me.gradle: implementation ‘com.itextpdf:itextpdf:5.0.6’
how to run this project>?
Got It thanks Just Run as java Application
How to use URL to pdf?
can we convert MathML into pdf