HashMap in Java programming is a widely used data structure that allows application developers to store and manage key-value pairs efficiently. When developing applications, it is common to encounter scenarios where you need to remove duplicate values from a HashMap. In this blog post, we will explore different approaches to delete duplicates from a HashMap in Java.
1. Exploring the Concept of Duplicate Values in HashMap
Exploring the concept of duplicate values in a HashMap is essential for understanding why and how they might occur, and how to address them effectively.
1.1 Common Scenarios for Duplicate Values
Here are some common scenarios that can lead to a program having multiple values in a HashMap
- When multiple keys are assigned to the same value intentionally to represent some relationship or grouping.
- When data is added to a HashMap without checking for duplicates. This can lead to unintentional duplication.
- When duplicate keys are used, which causes the original
key-valuepair to be overwritten, but the value remains the same.
1.2 Duplicate Values in Hashmap
In a typical HashMap, keys are unique, meaning that each key can have only one associated value. However, the values in a HashMap can be duplicated. This means that multiple keys can map to the same value. Here’s an example that demonstrates duplicate values in a HashMap:
public class HashMapExample {
public static void main(String[] args) {
// Create a HashMap
HashMap<Integer, String> hashMap = new HashMap<Integer, String>();
// Add key-value pairs with potentially duplicate values
hashMap.put(1, "Apple");
hashMap.put(2, "Banana");
hashMap.put(3, "Cherry");
hashMap.put(4, "Banana"); // Duplicate value
hashMap.put(5, "Cherry"); // Duplicate value
// Display the HashMap
System.out.println("HashMap: " + hashMap);
}
}
In the example code above, we create a HashMap where keys are integers and values are strings. Notice that the value Banana is associated with both keys 2 and 4, and the value Cherry is associated with keys 3 and 5 making them duplicate values. When we run this code, the output shows that HashMap allows duplicate values, as shown below:

Now, Let’s consider a scenario where we want to remove the duplicate fruits (Banana and Cherry) from the map. Removing duplicates from a HashMap usually means removing entries key-value pairs where the values are the same. It’s important to note that each key is unique in a HashMap, However, HashMaps do not enforce uniqueness in values
2. Approach 1: Using a Loop
We can use a loop to remove duplicates in a HashMap by iterating through the entries of the HashMap and checking for duplicate values while building a new HashMap without duplicates.
Below is a Java code example that demonstrates this:
public class RemoveDuplicatesHashmap {
public static void main(String[] args) {
// Create a sample HashMap with duplicate values
HashMap<Integer, String> originalMap = new HashMap<Integer, String>();
originalMap.put(1, "Apple");
originalMap.put(2, "Banana");
originalMap.put(3, "Cherry");
originalMap.put(4, "Banana"); // Duplicate
originalMap.put(5, "Orange");
originalMap.put(6, "Apple"); // Duplicate
// Create a new HashMap to store non-duplicate entries
HashMap<Integer, String> nonDuplicateMap = new HashMap<Integer, String>();
// Iterate through the entries of the original HashMap
for (Map.Entry<Integer, String> entry : originalMap.entrySet()) {
Integer key = entry.getKey();
String value = entry.getValue();
// Check if the value is not already present in the nonDuplicateMap
if (!nonDuplicateMap.containsValue(value)) {
nonDuplicateMap.put(key, value);
}
}
// Print the non-duplicate HashMap
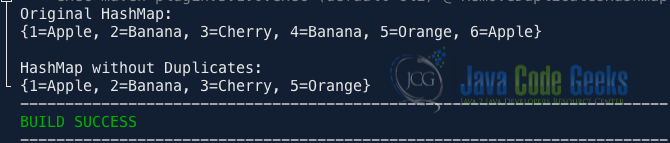
System.out.println("Original HashMap:");
System.out.println(originalMap);
System.out.println("\nHashMap without Duplicates:");
System.out.println(nonDuplicateMap);
}
}
In this example, we first create an originalMap with duplicate values. Next, we create a nonDuplicateMap to store the non-duplicate entries. We iterate through the entries of the originalMap, and for each entry, we check if its value is already present in the nonDuplicateMap. If not, we add the entry to the nonDuplicateMap.
After running the code, you will notice that the nonDuplicateMap contains only unique values from the originalMap as shown in Fig 2.
3. Approach 2: Using Java Stream API and Lambdas
We can use the Stream API introduced in Java 8 to remove duplicate values from a HashMap. Using Java 8 onwards, we can create a new HashMap that retains the first occurrence of each unique value from the original HashMap using the Stream API.
Below is an example code that demonstrates how to do it:
public class RemoveDuplicatesUsingStream {
public static void main(String[] args) {
// Create a HashMap with key-value pairs (including duplicates)
Map<String, String> hashMap = new HashMap<String, String>();
hashMap.put("Thomas", "Age of Reason");
hashMap.put("Charles", "Olivier Twist");
hashMap.put("Jonathan", "Gullivers Travels");
hashMap.put("Daniel", "Robinson Crusoe");
hashMap.put("Thomass", "Age of Reason"); // Duplicate Value
hashMap.put("Chinua", "Chike and The River");
hashMap.put("John", "Gullivers Travels");// Duplicate Value
// Use Java Streams to extract the unique values
Map<String, String> result = hashMap.entrySet()
.stream()
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (existing, replacement) -> existing));
// Print the unique values
System.out.println("Unique Values" + result);
}
}
In the code example above, we use the Collectors.toMap method to create a new HashMap while filtering out duplicates. The lambda expression (existing, replacement) -> existing ensures that if duplicate keys are encountered, the existing value is retained.
As a result, the new HashMap will contain only unique values, and duplicate values will be removed. The output will show the unique key-value pairs in the HashMap as shown below:
Unique Values{Thomas=Age of Reason, Charles=Olivier Twist, Jonathan=Gullivers Travels, Chinua=Chike and The River, Daniel=Robinson Crusoe}
4. Approach 3: Using Java Stream API with a Set
We can also delete duplicate values from a HashMap using the Stream API, utilizing a Set<String> to store the current values. Below is the code example to achieve this:
public class RemoveDuplicatesUsingStream {
public static void main(String[] args) {
// Create a HashMap with key-value pairs (including duplicates)
Map<String, String> hashMap = new HashMap<String, String>();
hashMap.put("Thomas", "Age of Reason");
hashMap.put("Charles", "Olivier Twist");
hashMap.put("Jonathan", "Gullivers Travels");
hashMap.put("Daniel", "Robinson Crusoe");
hashMap.put("Thomass", "Age of Reason"); // Duplicate Value
hashMap.put("Chinua", "Chike and The River");
hashMap.put("John", "Gullivers Travels");// Duplicate Value
System.out.printf("Original HashMap: %s%n", hashMap);
// Set to keep the existing values
Set<String> existing = new HashSet<String>();
hashMap = hashMap.entrySet()
.stream()
.filter(entry -> existing.add(entry.getValue()))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
System.out.printf("HashMap without Duplicates: %s%n", hashMap);
}
}
When we run the example code above, the result will contain only the unique values from the hashMap. The second output will show the unique values:
Original HashMap: {Thomas=Age of Reason, Charles=Olivier Twist, Jonathan=Gullivers Travels, John=Gullivers Travels, Chinua=Chike and The River, Daniel=Robinson Crusoe, Thomass=Age of Reason}
HashMap without Duplicates: {Thomas=Age of Reason, Charles=Olivier Twist, Jonathan=Gullivers Travels, Chinua=Chike and The River, Daniel=Robinson Crusoe}
5. Conclusion
In this article, we showed three different approaches and code examples on how to remove duplicate values from a Hashmap in Java. To delete duplicates from a HashMap in Java typically involves iterating through the HashMap entries and creating a new HashMap or using the Stream API introduced in Java 8 as a tool to achieve this task.
6. Download the Source Code
This was an example of Delete Duplicates From HashMap in Java.
You can download the full source code of this example here: Delete Duplicate Values From HashMap in Java
